






目录
算法通关村 —— LRU的设计与实现
缓存时应用软件的必备功能之一,常用的有FIFO、LRU和LFU三种基本的形式。FIFO也就是队列方式不能很好利用程序局部性特征,缓存效果比较差。一般使用LRU(最近最少使用)和LFU(最不经常使用淘汰算法)比较多一些。LRU是淘汰最长时间没有被使用的页面,而LFU是淘汰一段时间内,使用次数最少的页面。
1 LRU缓存
1.1 LRU的含义
简单来说就是当内存空间满了,不得不淘汰某些数据(通常是容量已满),选择最长时间未被使用的数据进行淘汰。
1.2 LRU算法思路
假设内存按照栈的方式来描述访问时间,在上面的是最近访问的,在下面的是最远时间访问的,LRU工作流程如下图:

1.3 LRU实现方式
目前公认最合理的方式是使用hash+双向链表,具体做法如下:
⚪ Hash的作用:用来做到时间复杂度O(1)访问元素,哈希表就是普通的哈希映(HashMap),通过缓存数据的键映射到其在双向链表终端位置。Hash里数据是 key-value 结构。value为我们自己封装的node,key则为键值,也就是在Hash的地址。
⚪ 双向链表的作用:用来实现根据访问情况排序元素。靠近头部的键值对是最近使用的,靠近尾部的键值对是最长时间未使用的。
故我们要确认元素位置只需访问哈希表,找出缓存项在双向链表中的位置,随后将其移动到双向链表头部,即可在O(1)时间内完成get或者put操作。具体实现方法如下:
⚪ get 操作:先判断key是否存在。
如果key不存在,则返回-1;
如果key存在,则key对应的节点是最近被使用的节点。通过哈希表定位到该节点在双向链表中的位置,并将其移动到双向链表头部并返回该节点值。
⚪ put 操作:先判断key是否存在。
如果key不存在,使用key-value创建新结点,在双向链表头部添加该节点,并将key和该节点添加进哈希表中。然后判断双向链表节点数是否超出容量,如果超出,则删除尾部节点,并删除哈希表中对应项(value变为null);
如果key存在,通过哈希表定位到该节点在双向链表中的位置,将对应节点值更新为value,将该节点移到双向链表头部。
注:上述操作,访问哈希表时间复杂度未O(1), 在双向链表头部添加节点、尾部删除节点也为O(1).
将节点移到双向节点的操作可以分为两步:删除该节点、 在双向链表头部添加节点,都为O(1)
在双向链表的实现中,使用伪头部节点(dummy head)和伪尾部(dummy tail)标记界限,这样在添加和删除节点就不需要检查相邻节点是否存在。具体实现如下图所示:
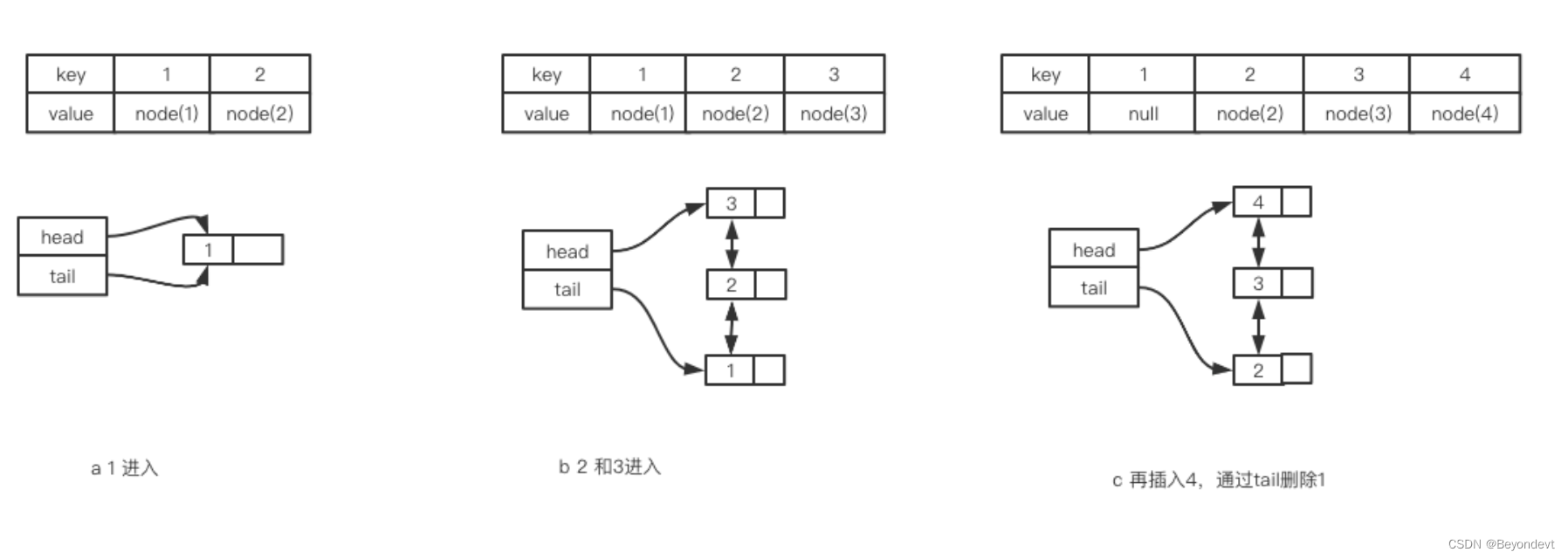

注(双向链表):
1)若容量没满,新元素直接插入到链表头
2)若容量满了,新的元素到来,将tail指向的表尾元素删除就行
3)若要访问已经存在的元素,则将该元素从链表中删除,再插入到表头就行了
注(Hash):
1)Hash没有容量限制,被访问的元素都会在Hash中有个标记,key就是我们的查询条件。value就是链表节点的引用,可以直接通过Hash定位到链表中的节点
2)HashMap中的删除其实就是将node变成为null
1.4 LRU实现代码
public class LRUCache {
/**
* 定义双向链表和实现有参无参构造
*/
class DLinkedNode {
int key;
int value;
DLinkedNode prev;
DLinkedNode next;
public DLinkedNode() {
}
public DLinkedNode(int _key, int _value) {
key = _key;
value = _value;
}
}
/**
* 定义HashMap,value存放双向链表节点
*/
private Map<Integer, DLinkedNode> cache = new HashMap<Integer, DLinkedNode>();
private int size;
private int capacity;
private DLinkedNode head, tail;
/**
* 初始化LRU缓存容量,以及构造伪头节点、伪尾节点
*/
public LRUCache(int capacity) {
this.size = 0;
this.capacity = capacity;
// 使用伪头部和伪尾部节点
head = new DLinkedNode();
tail = new DLinkedNode();
head.next = tail;
tail.prev = head;
}
/**
* get操作:根据值取节点,将节点移到头部
*/
public int get(int key) {
DLinkedNode node = cache.get(key);
if (node == null) {
return -1;
}
// 如果 key 存在,先通过哈希表定位,再移到头部
moveToHead(node);
return node.value;
}
/**
* put操作:存放新结点或改变节点的值
*/
public void put(int key, int value) {
DLinkedNode node = cache.get(key);
if (node == null) {
// 如果 key 不存在,创建一个新的节点
DLinkedNode newNode = new DLinkedNode(key, value);
// 添加进哈希表
cache.put(key, newNode);
// 添加至双向链表的头部
addToHead(newNode);
++size;
if (size > capacity) {
// 如果超出容量,删除双向链表的尾部节点
DLinkedNode tail = removeTail();
// 删除哈希表中对应的项
cache.remove(tail.key);
--size;
}
} else {
// 如果 key 存在,先通过哈希表定位,再修改 value,并移到头部
node.value = value;
moveToHead(node);
}
}
/**
* 添加新结点到链表头部
*/
private void addToHead(DLinkedNode node) {
node.prev = head;
node.next = head.next;
head.next.prev = node;
head.next = node;
}
/**
* 删除节点
*/
private void removeNode(DLinkedNode node) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
/**
* 将指定节点移到链表头部
*/
private void moveToHead(DLinkedNode node) {
removeNode(node);
addToHead(node);
}
/**
* 删除链表尾结点
*/
private DLinkedNode removeTail() {
DLinkedNode res = tail.prev;
removeNode(res);
return res;
}
/**
* 测试类
*/
public static void main(String[] args) {
LRUCache lRUCache = new LRUCache(2);
lRUCache.put(1, 1); // 缓存是 {1=1}
lRUCache.put(2, 2); // 缓存是 {1=1, 2=2}
System.out.println(lRUCache.get(1)); // 返回 1
lRUCache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3}
System.out.println(lRUCache.get(2)); // 返回 -1 (未找到)
lRUCache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3}
System.out.println(lRUCache.get(1)); // 返回 -1 (未找到)
System.out.println(lRUCache.get(3)); // 返回 3
System.out.println(lRUCache.get(4)); // 返回 4
}
}














 3405
3405











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









