






Rabbit R1在上周正式发售,各类测评接踵而至,而我比较感兴趣LAM,以及R1的实现,下文是之前我对Large Action Model的实现推测。
========================================================================
| 本文部分结论来源于基于Rabbit r1技术报告(以下简称“报告”)的合理推测。点击“阅读原文”可跳转至该报告。 |
在#CES2024一众“透明电视”、“智能马桶”和“可跟随的自拍杆”之中,一只兔子(Rabbit r1)可谓是出尽了风头。市场对兔子反馈热烈,一周之内,兔子预售5万台,其在YouTube上的产品发布视频也突破了4百万播放。
在很“Q”的外表和“原生Teenage”的交互设计的噱头之外,兔子最大的卖点是Large Action Model(LAM),该model帮助兔子成为了一个可以使用APP的“伴侣”,能够实现从“打车”、“订餐”到“旅程规划”等可简单、可复杂的人类意图。
Rabbit R1
01:12
视频: 兔子无缝实现“打车”、“订餐”等意图(来源于Rabbit r1 官方视频)
与一般的“伴侣”相比,基于LAM的兔子有着“超高的准确率”、“10倍的响应速度”,以及“教一次就会”的学习能力。
但LAM并非是一个纯粹的语言大模型,而更近似于AI Agent,其官方定义可以佐证:
![]()
By utilizing neuro-symbolic techniques in the loop, LAM sits on the very frontier of interdisciplinary scientific research in language modeling (LM), programming languages (PL), and formal methods (FM).![]()
如果上述产品宣传为真,那么,兔子是如何“调教”LAM,使其在准确度、性能、和学习能力等方面超越一般的Agent?
依据报告,我们梳理了LAM的“调教”思路,以飨读者。

选择“路线”
如果从使用Tools的方式看,当下Agents 大抵有三条技术路线:原生、集成和生成(Program Synthesis):
- 原生:标准的Planner-Solver模式,完全依靠大模型自身实现意图,例如ReAct;
- 集成:其核心是Function calling,大模型通过使用外部API实现意图,这是当下比较标准的Agent路线;
- 生成:大模型通过生成代码(Program)来实现意图,例如 Code Interpreter、AutoGen或者MetaGPT。
当然也有不少Agents采取集成和生成的混合模式。
原生路线无法帮助LAM使用APP,首先被排除。其次,鉴于API只能覆盖有限的APP和场景,集成路线也被排除。
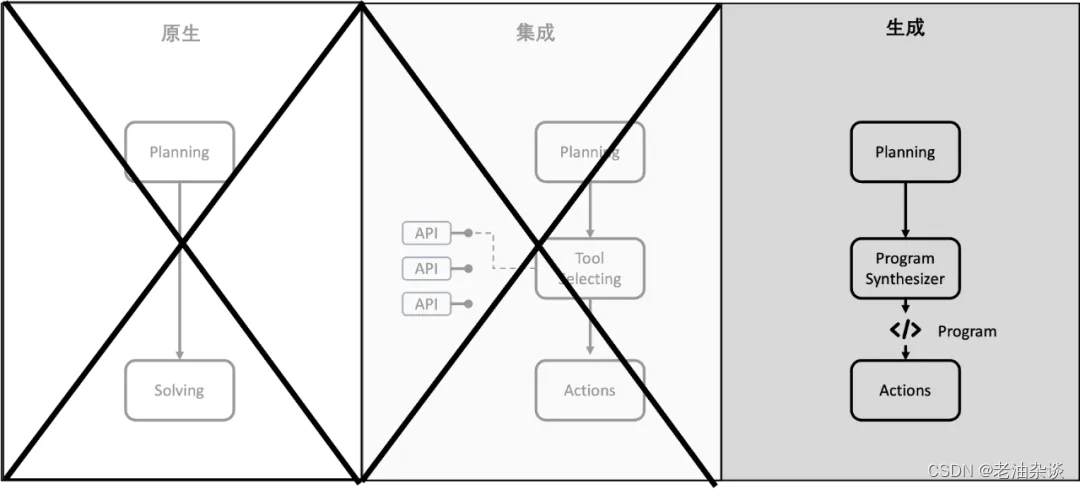
图1: LAM的路线选择
生成路线成了唯一的选择,而RPA在使用APP上比API更具普适性,因此,通过大模型生成RPA程序(text-to-RPA)也就顺理成章地成为了LAM的“基座”。
此时,我们可以更准确地描述LAM: 一个通过text-to-RPA模拟人类在UI上的交互以使用APP的Agent(图2)。
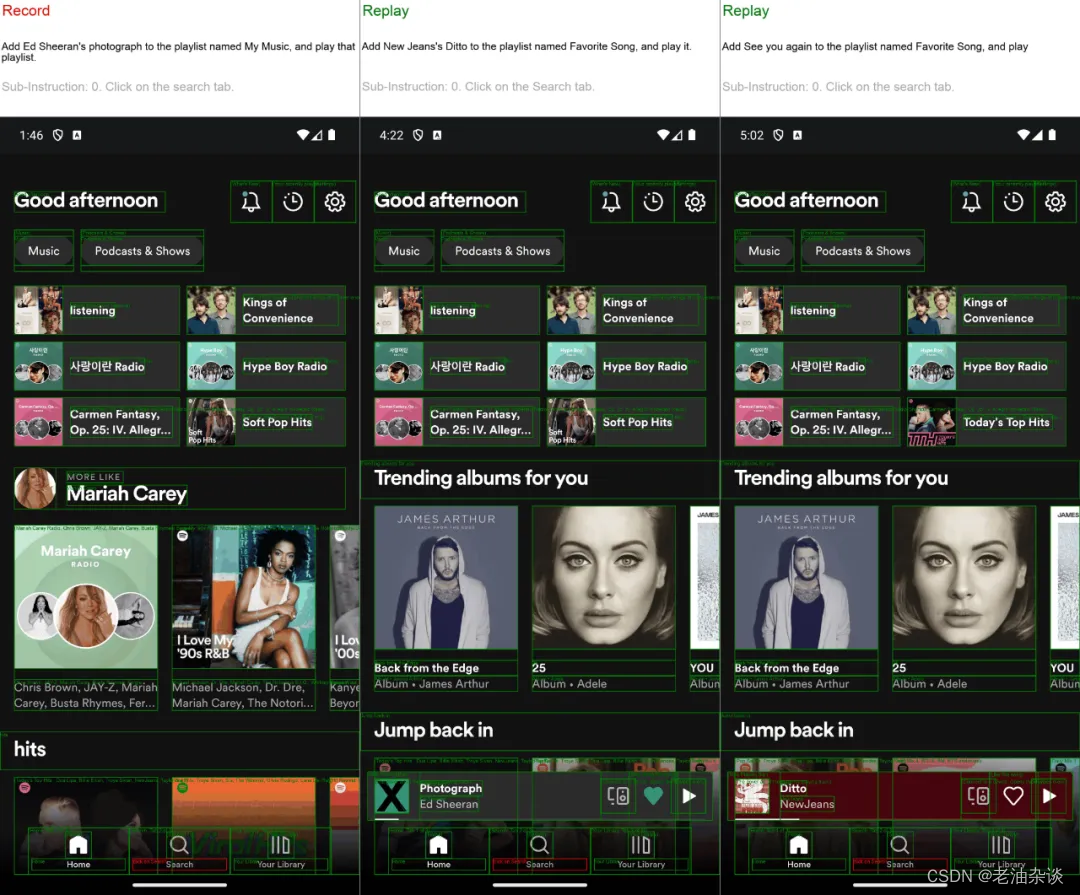
图2: LAM的text-to-RPA演示
那么,text-to-RPA中的RPA长什么样?

兔子的“食谱”
依据报告内容,兔子自定义了一整套基于Neuro-symbolic programming的RPA语言:食谱(Recipe)。Recipe用于描述UI的结构和用户在UI上的交互,其由Actions和Action Sequence(Action Seq)构成。
![]()
Enabled by recent advances in neuro-symbolic programming, the LAM allows for the direct modeling of the structure of various applications and user actions performed on them without a transitory representation, such as text.
![]()
与Standard RPA相比,Recipe有如下特性:
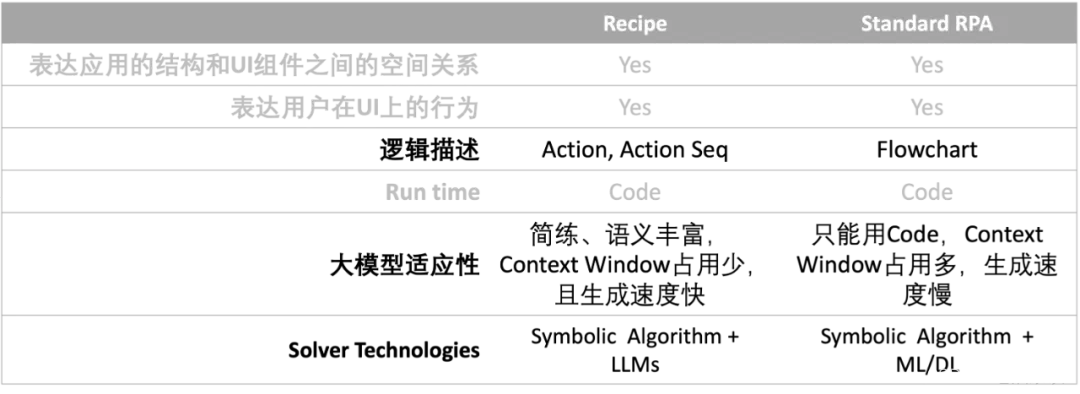
表1 :Recipe vs Standard RPA
- 使用Action Seq描述UI结构和用户在UI上的交互,Action Seq是更简练的结构和逻辑表达方式,富含丰富的语义,利于提升大模型任务的速度和准确度;
- 在交互分析上使用Symbolic Algorithm + LLMs,直接利用大模型的语义分析、图像理解和推理等能力分析用户的UI行为,例如内容匹配、分类和抽取,而无需借助其他CNN或DNN。
虽然报告未能提供Recipe的实现,但依据其引用的论文《Ringer: Web Automation by Demonstration》和《Web Question Answering with Neurosymbolic Program Synthesis》,我们推测其形式如下(图2):

图3: 推测Recipe的实现
Recipe由Actions/Action Seq构成,每个Action可由Symbolic Programming和LLM单独或共同实现。其中,Symbolic Programming处理基于规则的任务,例如,事件响应/触发等,而LLM处理基于语义的任务,例如,Action的语义理解、组件定位等。
LLM与Symbolic Programming的结合是LAM可以在UI变化后保持Recipe稳定的原因,也让LAM具备了UI交互建模的普适性。

“调教”工作
利用选定的路线和自定义的Recipe,我们推测兔子对LAM的各个环节进行了如下“调教”(图3):
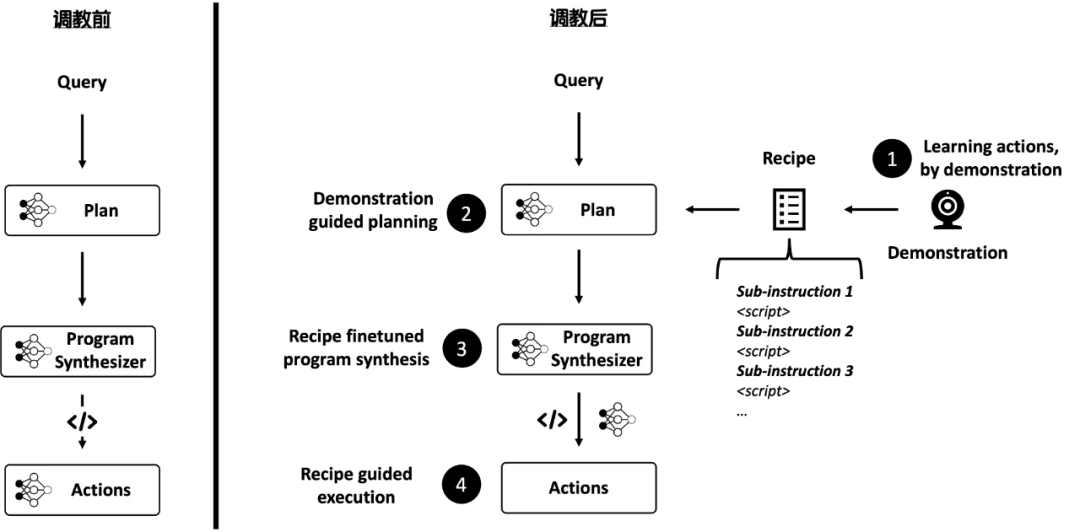
图4: 调教前 vs 调校后
首先,Plan阶段由大模型依据用户Query自主生成计划变为:
- Learning actions, by demonstration。 LAM可以将用户的APP使用演示转化为模版Recipe;
- Demonstration guided planning。LAM完全摒弃了由大模型主导的计划生成,而是结合用户的Query与对应的Recipe模版形成计划:大模型先依据用户Query找到对应的Recipe模版,之后,Recipe模版结合用户Query中的相关要素形成Program Synthesizer的输入prompt。
其次,Program Synthesis阶段由生成代码变为:
- Recipe finetuned program synthesis。Recipe Finetuned LLM会基于prompt生成新的Recipe。
最后,Actions阶段由Agent在Sandbox中执行代码变为:
- Recipe guided execution。新的Recipe被送往云端用于模拟用户的APP交互。由于事先已经要求用户在Rabbit Hole中完成认证,LAM将通过VNC的方式完成交互,并返回相应结果。
如果我们推测正确,上述“调教”过程是LAM达成“超高的准确率”、“10倍的响应速度”,以及“教一次就会”的学习能力的主要驱动力(图4)

图4: 预期的效果
其中,Plan阶段的“调教”是LAM的画龙点睛之笔,用户演示像是给LAM装上了导航,避免了一般Agent路线的“试错”过程,既提升了准确度,又节省了大模型的生成时间。

疑问与启示
当然,我们对LAM的功能性也有诸多疑问,例如,假设用户只给出非常模糊的意图,LAM是否有能力通过追问厘清需求? 再如,LAM是否对内容较复杂的APP友好,例如Excel或者Numbers?此外,LAM“端”的能力有多强大?是否能在离线状态下具备一定能力?
但无论兔子是否能够成功,LAM都是一个可以借鉴的Agent调优思路。尤其是在特定领域中(例如,回答2B的业务问题),面对数量有限的APP和业务场景,我们也许无需选择“一个能够回答任何问题、产生任何代码”的通用Agent,而是选择类似于LAM和text-to-RPA这类较为定制化的Agent方案。
















 265
265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











