







为什么需要分布式锁?
分布式锁是一种用于 协调分布式系统中并发访问共享资源的机制。
目前常用的分布式锁组件有三种,
- 基于 Redis 这种远端缓存实现,常用的实现 Redission 客户端
- 基于 ZK,常用的实现 Curator 客户端。
- 基于DB,使用 X 锁
分布式锁区别:
| 锁类型 | 实现原理 | 性能差异 | 锁的安全性 |
|---|---|---|---|
| Redis | Redis 中基于键值对来实现分布式锁的添加和删除。需要考虑较多的 异常问题 | 1. 对于服务端来讲,Redis 集群主要做缓存中间件,以吞吐量作为系统的主要目标。 2. Redis 没有通知机制,尝试加锁过程中,需要使用类似 CAS 的轮询方式去争抢锁,故会占用 CPU 资源。 | 使用了 Redlock 算法,但无法保证 100% 的健壮性,但一般的应用不会遇到极端场景,所以也被常用。 |
| ZK | ZK 中可以基于临时 ZNode 来实现锁,ZNode 本身具有锁的特性,其内部实现简单。 | 1. 对于服务端来讲,ZK 集群主要用做注册中心和服务治理,具有CP(Consistence、Partition tolerance)的特点。 2. 对于连接的客户端来讲,ZK 由于有通知机制,获取锁的过程,添加一个监听器就可以了,避免了轮询,性能消耗较小。 | ZK 具有 CP 特性,有严格的 Zab 协议控制数据的一致性,锁模型健壮。 |
| DB | 多个客户端对同一个唯一键的行添加排他锁来实现。常和事务一起使用,也可以创建一行数据来完成加锁。 | 依赖 DB 的吞吐量 | 有持久化机制,可靠性较高。 |
如何借助 Redis 自主实现分布式锁?
如下的一个请求,模拟分布式场景下,多线程安全售票用例( ticket 的数据存于 Redis 中)。我们需要解决的问题如下:
-
如何确保正常、异常情况下锁都可以释放?
- 应用存活阶段,finally 块来保证出现代码执行异常时的锁释放
- 应用异常关闭场景下,合并 redis 的 设值与超时时间 为一个原子操作,保证该场景下锁可以通过过期策略,被释放
- 命令:加锁:SET lockKey UUIDOfTheThread NX;释放:DEL lockKey
-
如何确保删除的是当前线程添加的锁?
- 使用uuid标记每一个不同的锁来确定删除的是本线程加的锁
- 先使用 GET 命令查出 UUIDOfTheThread 进行对比,然后再使用 DEL 删除
- 使用uuid标记每一个不同的锁来确定删除的是本线程加的锁
-
在1.2场景下,锁的超时时间的合理性问题?
- 时间如果太短,会导致线程还没执行完,锁就被redis过期策略删除;时间如果太长且应用异常宕机后,锁很长时间才被过期,就会影响系统吞吐量低。
- 故考虑 开启新的线程来对时间进行管理, 先设置一个短的时间,如果锁还在,证明线程还没执行完成,为 redis 中的锁加一段时间。
-
单点故障场景下,如何确保锁不丢失?
- Redis 集群中,如果存锁的实例出现了单点故障,导致锁丢失场景下,我们可以把锁分散到集群中的多个实例上去存储,只要集群不下线,锁就不会丢失。
有缺陷的分布式锁:
@RequestMapping("/safeSale")
public String safeSaleTicket() {
String res = "", lockKey = "lock",uuid= UUID.randomUUID().toString();
try {
//1
Boolean ifAbsent = stringRedisTemplate.opsForValue().setIfAbsent(lockKey, uuid, 5, TimeUnit.SECONDS);//setnx key value + expire ...
if(!ifAbsent){
return "当前线程不具备出票能力";
}
Integer ticket = Integer.parseInt(stringRedisTemplate.opsForValue().get("ticket"));
if (ticket > 0) {
res = "售出票第" + ticket;
stringRedisTemplate.opsForValue().set("ticket", String.valueOf(ticket - 1));
System.out.println("======目前剩余库存" + (ticket - 1) + " in tomcatB");
} else {
res = "票已出完" + ticket;
}
} finally {//2
//3
if(uuid.equals(stringRedisTemplate.opsForValue().get(lockKey))){
stringRedisTemplate.delete(lockKey);
}
}
return res + " in tomcatB";
}
上述的4个问题,在 Redission 框架中,已经为我们封装好了
借助 Redission 实现的分布式锁
Redission 是一个 Redis 的 Java 客户端,内部封装了基于 RedLock 算法实现的分布式锁,具有以下的特性:
- 可重入
- 可公平
- 支持读写锁
@RequestMapping("/saleByRedission")
public String saleByRedission() {
String res = "", lockKey = "lock";
RLock redissonLock = redisson.getLock(lockKey);
try {
//加超时时间为10s的分布式锁,每隔10/3s,检测锁是否存在;如果锁存在重新设置超时时间为10s,如果不存在,则不做处理。
redissonLock.lock(10, TimeUnit.SECONDS);
Integer ticket = Integer.parseInt(stringRedisTemplate.opsForValue().get("ticket"));
if (ticket > 0) {
res = "售出票第" + ticket;
stringRedisTemplate.opsForValue().set("ticket", String.valueOf(ticket - 1));
System.out.println("======目前剩余库存" + (ticket - 1) + " in tomcatB");
} else {
res = "票已出完" + ticket;
}
} finally {
redissonLock.unlock();
}
return res + " in tomcatB";
}
RedLock 算法
旨在解决 Redis 单点故障的问题,通过在多个独立的 Redis 实例上加锁来提高分布式锁的可靠性。
RedLock 算法流程:
-
得到当前的时间,毫秒单位
-
尝试顺序地在 N 个实例上申请锁,当然需要使用相同的 key 和 random value。当在每个实例中设置锁时,客户机使用一个与锁自动释放总时间相比较小的超时来获取它,避免长时间和一个不可用的节点浪费时间,尽快与下一个节点通信
-
client 通过从当前时间减去在步骤1中获得的时间戳来计算获取锁所用的时间。如果 client 能够在大多数实例(至少3个)中获取锁,并且获取锁所用的总时间小于锁有效时间,则认为该锁已被获取。
-
如果获得了锁,则其有效时间被认为是初始有效时间减去经过的时间,如步骤3中计算的。
-
如果客户端由于某种原因未能获得锁(或者无法锁定N/2+1个实例,或者有效期为负),它将尝试解锁所有实例(甚至是它认为无法锁定的实例)。
RedLock 缺陷:
如果我们的节点没启用 持久化机制 或者 突然断电后 AOF 部分命令没来得及刷回磁盘直接丢失了,client1 从 5 个 master 中的 3 个获得了锁,然后其中一个 master 重启了(即丢失了 client1 创建的锁),那么此时集群中 又可以出现 3 个 master 给另一个 client2 申请同一把锁! 违反了互斥性。
解决这个问题的方法是,当一个节点重启之后,我们规定在 max TTL 期间它是不可用的,这样它就不会干扰原本已经申请到的锁,等到它 crash 前的那部分锁都过期了,环境不存在历史锁了,那么再把这个节点加进来正常工作。
使用延迟重启基本上可以实现安全性,即使没有任何Redis持久性可用,但是请注意,这可能会降低可用性。例如,如果大多数实例崩溃,系统将变得对 TTL 全局不可用(这里全局意味着在此期间没有任何资源是可锁定的)。
锁续约机制
锁续约机制是为了解决宕机情况下,不设置锁过期时间而导致的死锁问题。
加锁时,当未设置 leaseTime 参数(锁过期时间),配置 lockWatchdogTimeout(监控锁的看门狗超时间,单位毫秒,默认值30000)对应的续约机制将生效,大体的流程如下:
加锁:
流程图如下:
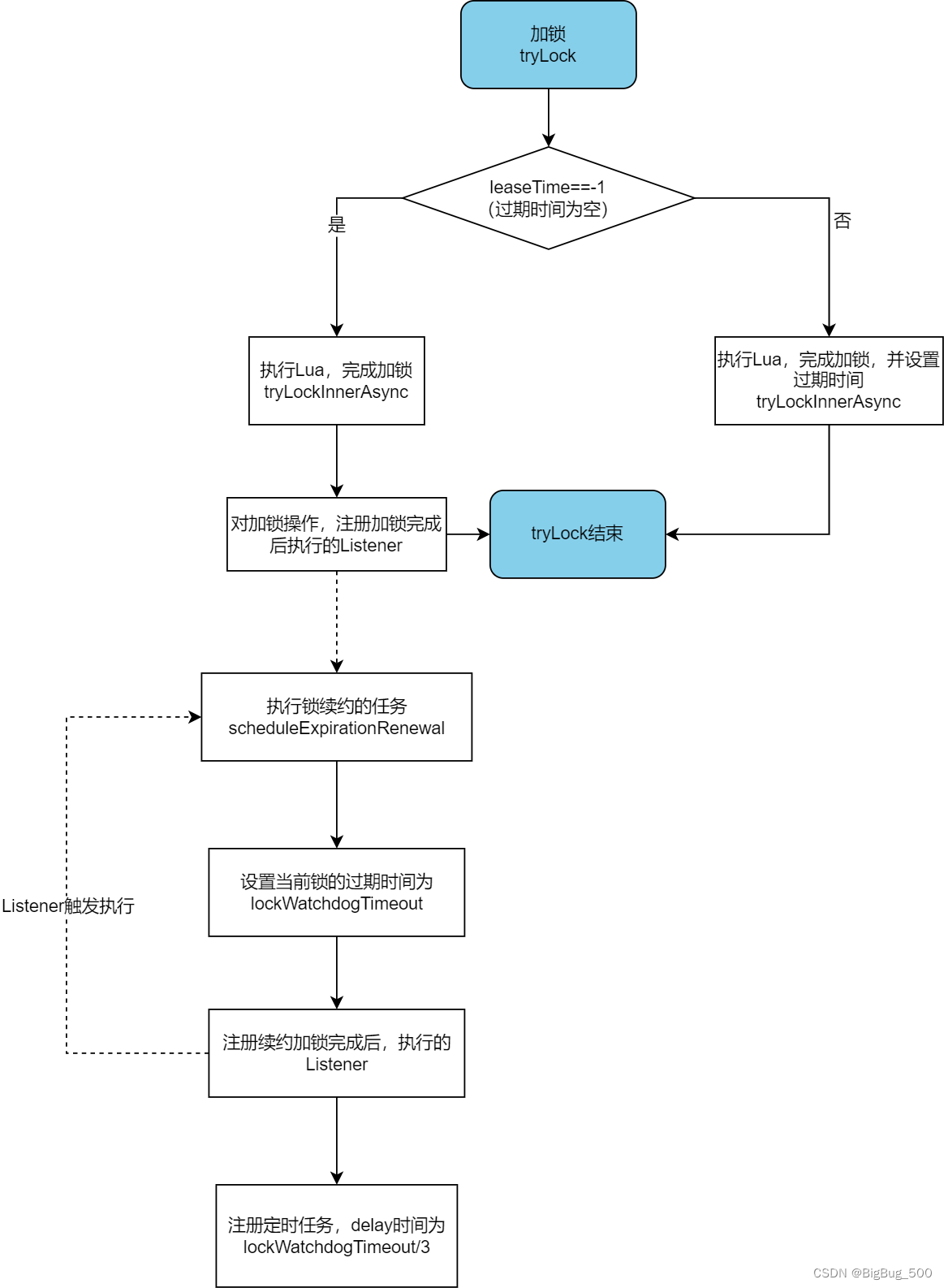
- 关键代码org.redisson.RedissonLock#scheduleExpirationRenewal,版本3.8.0
- 其中涉及到大量的异步操作,需要注意执行顺序
Redis 官网对 Redlock 的介绍与问题讨论
Redission-wiki-目录
wiki-分布式锁和同步器
DB下的分布式锁
通过数据库的事务特性和唯一约束 来保证锁的互斥性和可靠性。有两种实现方式
- 新增一条锁信息行,加锁时,让行数据生效,解锁时删除行数据。
- 缺点:需要对锁引入一张DB表
- 优点:不需要引入其他工具包,借助现有DB即可实现分布式锁
- 在事务中通过添加排他锁,如 select * for update,完成分布式资源锁定
- 缺点:锁定的时间不能超过事务超时时间
- 优点:不需要引入其他工具包,借助现有DB即可实现分布式锁
ZK下的分布式锁
基于ZK的吞吐量问题,应用新增依赖等问题,ZK 实现分布式锁的应用场景较少,此处不做深入研究。
















 525
525











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









