







0. 前言
从 CPU 到内存、到磁盘、到操作系统、到网络,计算机系统处处存在不可靠因素。工程师和科学家努力使用各种软硬件方法对抗这种不可靠因素,保证数据和指令被正确地处理。在网络领域有 TCP 可靠传输协议、在存储领域有 Raid5 和 Raid6 算法、在数据库领域有基于 ARIES 算法理论实现的事务机制……
本文将从实际场景出发(Trade、Fund),介绍传统事务下的并发操作问题、分布式场景下操作多数据源面临的问题,然后给出一些常用的解决方案。
传统并发事务与数据操作
术语:
- ACID:Durability、Isolation、Consistency、Atomicity
并发事务场景下,需要考虑安全、高效的操作数据,其核心要处理的问题有哪些?
- 并发更新冲突
- 并发事务隔离
- 死锁
- 并发性能
并发更新冲突:
解决方法:使用锁机制(如悲观锁或乐观锁)、版本控制方式来处理并发更新冲突,确保数据的一致性和完整性。
加锁方式对比:
| 方式 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|
| 悲观-中间件 |
- 锁定时长可按需设定
| | 适用于更新频繁、数据一致性要求较高的场景 |
| 悲观-Exclusive Lock | - 锁定时长有限制,由事务控制
| | 适用于更新频繁、数据一致性要求较高的场景 |
| 悲观-Shared Lock | - 锁定时长有限制,由事务控制
- 降低了锁的粒度
| | 适用于更新频繁、数据一致性要求较高的场景 |
| 乐观锁 | - 不加锁,更新时才校验
| - 依赖业务流程中,选择对应的数据操作版本
| 更新冲突较少的场景 |
并发事务隔离:
解决方法:使用合适的事务隔离级别来控制事务的隔离程度,确保事务之间的操作不会相互干扰。
注意事项:
- 案例:幻读问题
- 使用锁定范围之外的快照数据问题
- 一锁、二判、三更新
死锁:
解决方法:采用死锁检测与处理机制,例如设置合适的超时时间、死锁检测器、死锁回滚等方式来处理死锁情况,确保系统能够正常运行。
注意事项:
- 同一系统中,不同业务处理流程下,资源循环等待
- 按一定的顺序锁定资源,避免形成环路。
- 所有需要访问的资源在事务开始时,一次性(或尽快)全部分配
- 不同业务系统中,环链路的形成
- 调整不合理的交互行为
- 事务在执行完毕后未正确释放锁或资源
- 完成业务边界测试
- 业务未按照预期的时间完成,长时间占用资源
- 设置资源锁定的超时或回滚时间
并发性能:
需要考虑锁的粒度、事务持有时间、索引优化等方面,以确保系统能够高效地处理大量并发操作。
解决方法:
优化数据库设计、合理设置锁策略、使用合适的索引、减少事务持有时间等方式来提高并发性能
讨论
**场景:**在充值、扣款、退款等多业务并发流程下,如何安全、高效的操作账户的余额?
方案:“孔乙己-茴的四种写法”
微服务间的分布式事务
术语:
- CAP:Consistency、Availability、Partition tolerance
- BASE:Basically Available、Soft state(系统在某个时刻的状态是可变的)、Eventual Consistency
- XA:XA 协议由 X/Open 组织提出的分布式事务处理规范,主要定义了事务管理器 TM 和局部资源管理器 RM 之间的接口。目前主流的数据库,MySQL、Oracle、DB2 都实现了 XA 协议
强依赖场景
服务A依赖服务B的处理结果,来完成一个实时业务流程
交互场景举例:
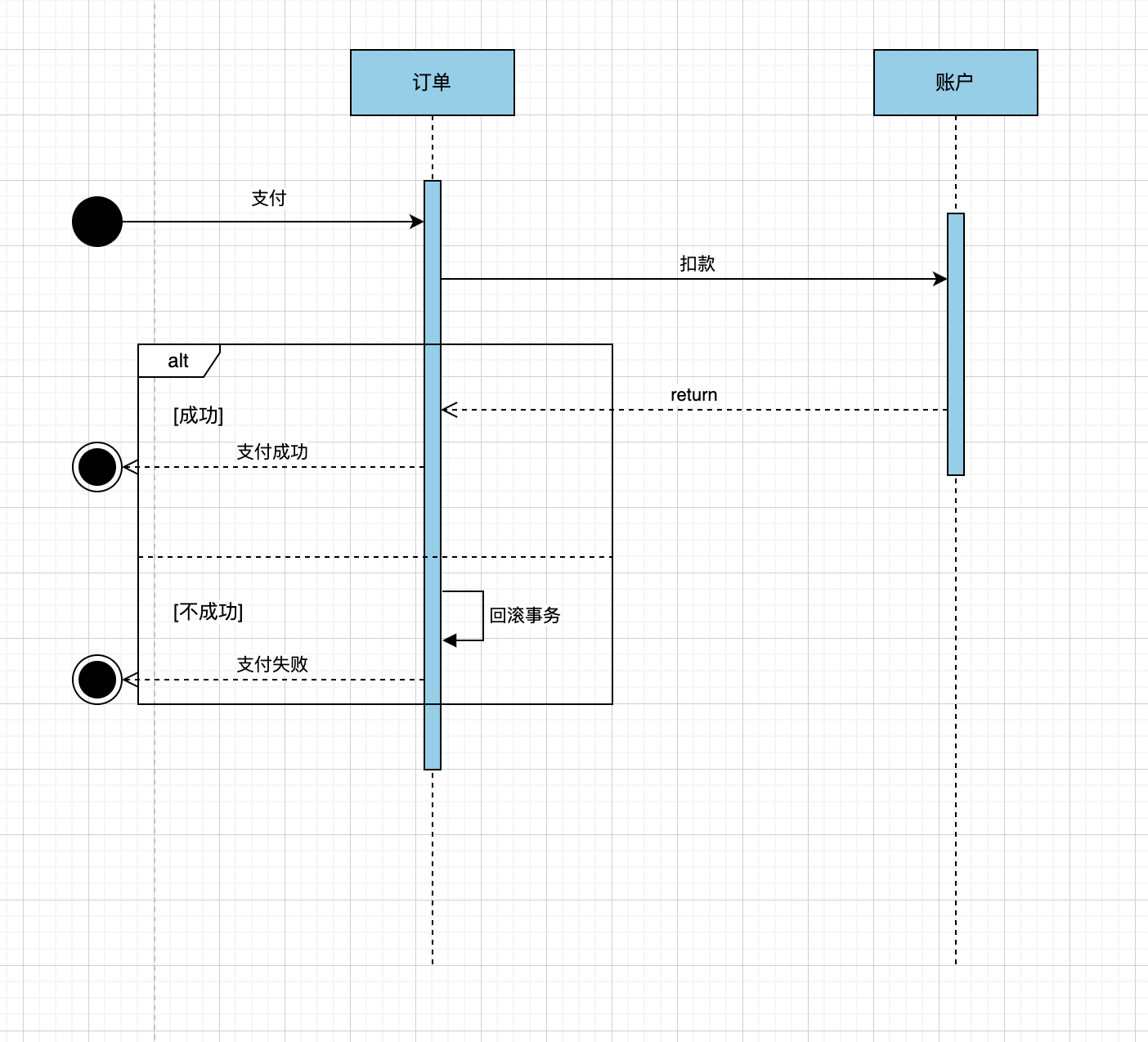
问题:
- 扣款接口超时,出现钱扣了,订单是未支付状态
短期重试方案
大体流程:
- 检测接口调用失败后、明确重试策略、执行重试操作、处理重试成功或失败(根据业务需求进行相应的处理,如记录日志、回滚操作、通知管理员等)、发出对应的告警通知。
可能存在的问题:
- 如果下游接口幂等性有问题,将出现重复数据等问题
- 系统间出现重试风暴
- 重试任务因宕机等问题丢失
应用场景:
- 短暂性问题
- 业务场景对可靠性要求不高
- 重试机制对可用性影响小
- 下游接口具有幂等性
eg:
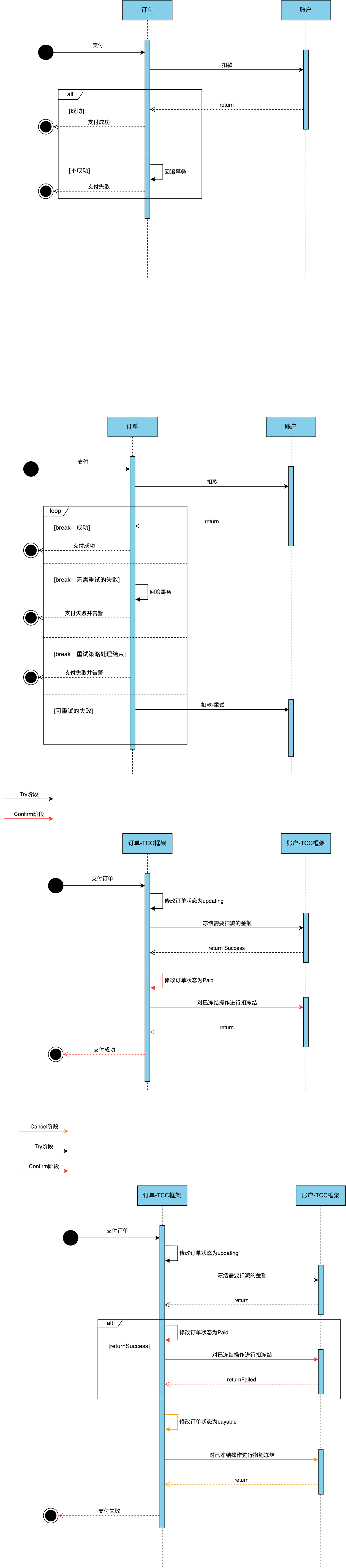
思考:
- 当重试策略处理结束后,两个系统数据不一致了,如何处理多个系统的业务数据一致性
TCC(Try-Confirm-Cancel)方案
大体流程:
- Try 阶段:对各个服务的资源做检测,以及对资源进行锁定或者预留。
- Confirm 阶段:在各个服务中执行实际的操作,失败后需要重试,所以需要保证该阶段操作具备幂等性。
- Cancel 阶段:如果任何一个服务的业务方法执行出错,那么就需要执行 Confirm 阶段的业务回滚和释放 Try 阶段锁定的资源操作
应用场景:
- 高一致性要求:当业务流程对数据一致性要求较高,需要一起成功,或回滚时,TCC 可以确保事务在任何情况下都能保持一致性。
- 分布式系统:在分布式环境中,由于网络、服务故障等原因,可能会导致事务中断或者部分操作失败。TCC 可以在分布式系统中保证事务的一致性。
- 复杂业务流程:对于涉及多个服务或者微服务的复杂业务流程,TCC 可以通过拆分事务、分步提交来简化事务管理,提高系统可维护性和可扩展性。
- 业务流程可撤销:TCC 适用于业务流程可以被撤销或者回滚的场景,比如订单支付、库存扣减等操作,可以尝试执行,确认执行成功后再进行最终提交,否则进行取消操作。
TCC想要解决的问题:
- 应用系统强依赖的某个基础服务(如数据库、Redis)宕机了
- 某个应用系统自己挂了
- 某些资源不足了,比如说库存、余额这些不够
为了简化 TCC 流程下3个阶段的处理,可以在项目中集成如下几种较成熟的开源框架,ByteTCC、Seata、Himly等,集成TCC开源框架后,应用处理流程如下:
eg:Try-Confirm
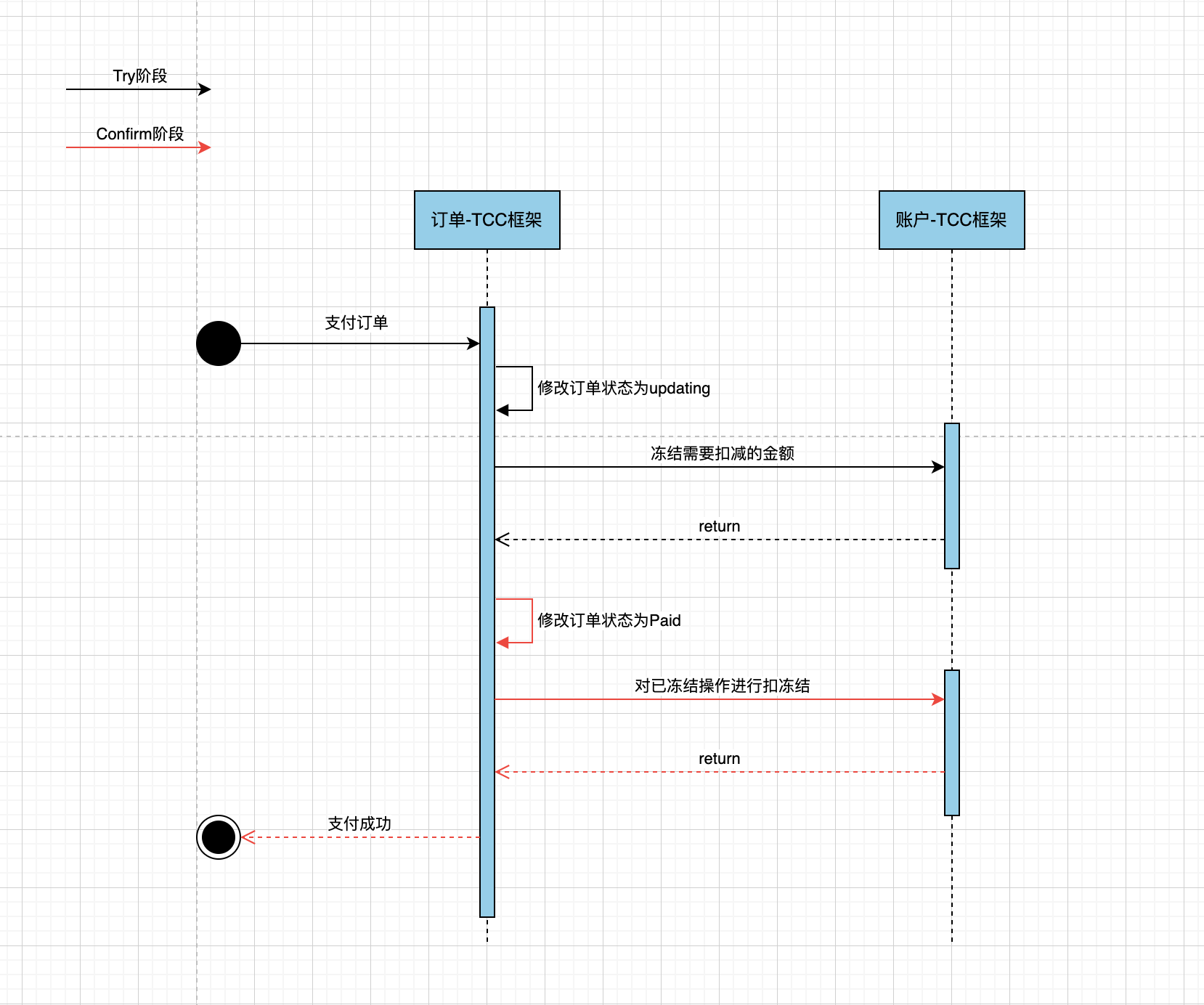
eg:Try-[Confirm]-Cancel
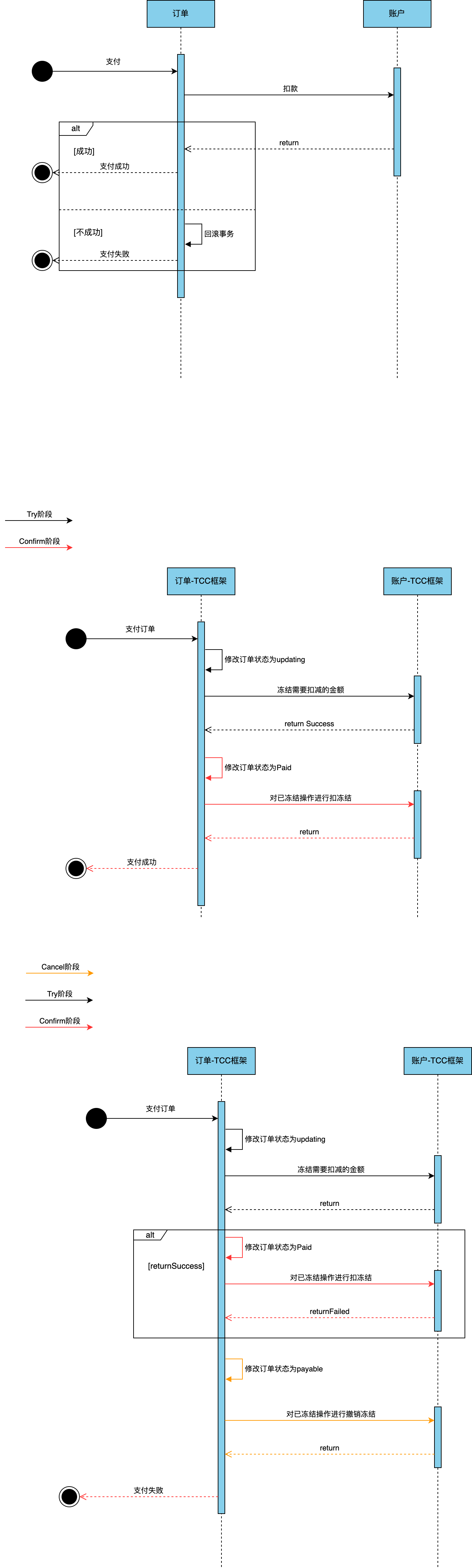
思考:
- 如果有一些意外的情况发生了,比如说订单服务突然挂了,然后再次重启,应该如何保证之前没执行完的分布式事务继续执行的呢?
- 如果某个服务的 Cancel 或者 Confirm 逻辑执行一直失败怎么办?
弱依赖场景
服务A不直接依赖服务B的处理结果,也可以完成一个业务流程
取消支付交互场景举例:
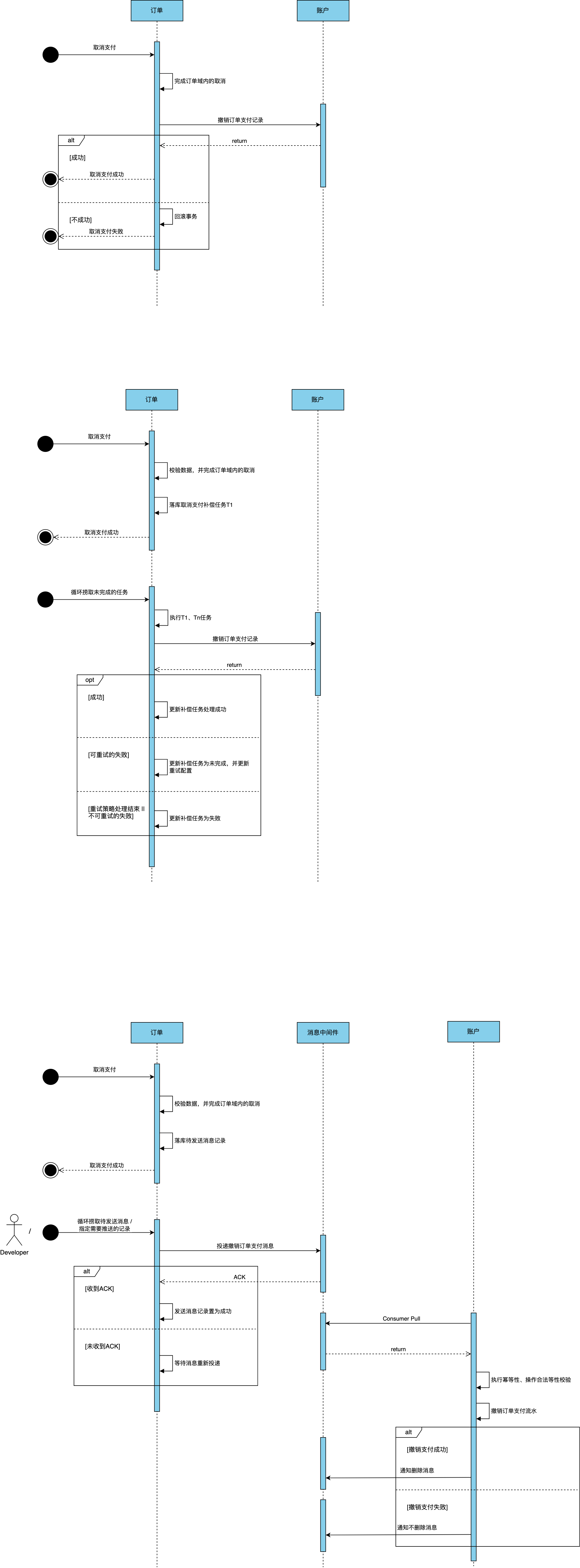
问题:
- 同步调用,当商户余额【临时】报错时,退款流程将失败
- 退款流程中,两个系统并非强依赖场景,可以异步➕补偿方式进行处理
基于重试任务的最终一致性分布式事务方案
大体流程:
- 服务A处理主要逻辑,包括与服务B的交互,但不直接依赖服务B的处理结果。
- 服务A向服务B发送请求,并将请求放入消息队列或任务队列中,不等待服务B处理结果。
- 服务A定期检查消息队列或任务队列中的请求,根据重试策略进行重试处理。
可能存在的问题:
- 下游接口幂等性问题
- 重试风暴问题
- 各种异常情况处理策略选择问题
- 重试任务丢失问题
- 内存中的重试方式
- 持久化的重试方式
- Antscheduler简单介绍:三层分发任务处理框架介绍
eg:
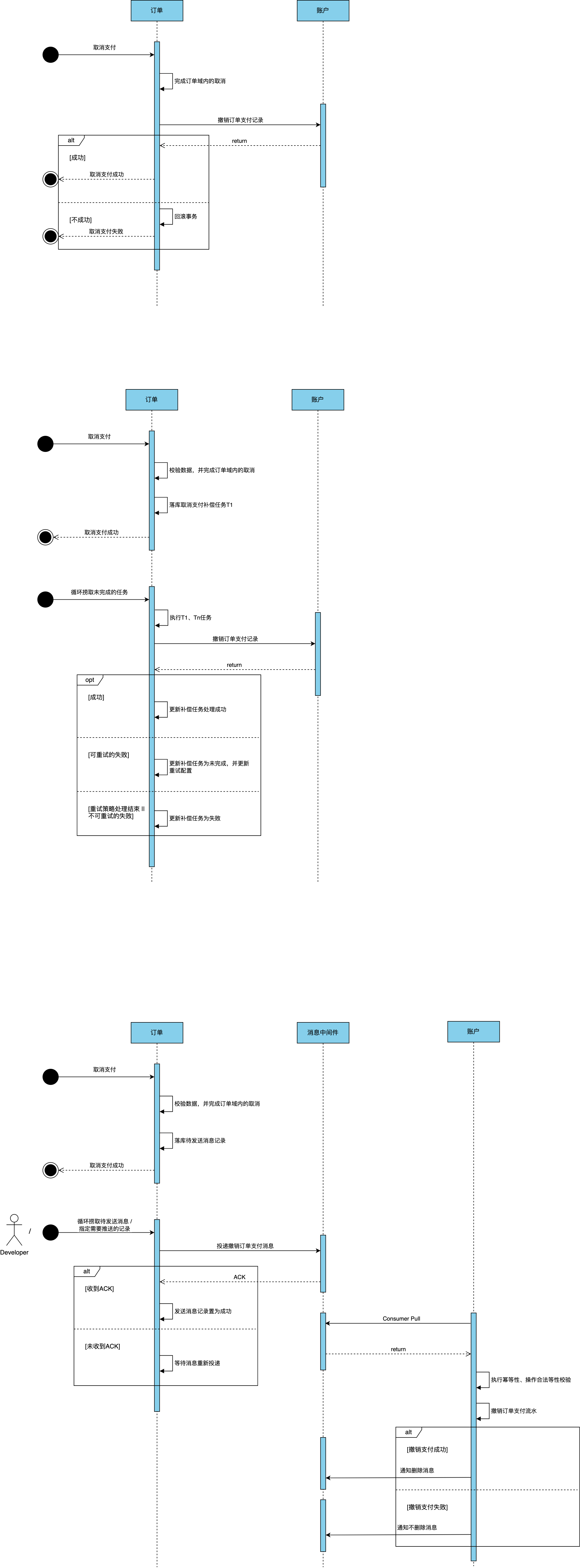
问题:
- 基于当下依赖的一些基础组件,如何设计补偿任务的落库与捞起重试
基于消息中间表的最终一致性分布式事务方案
大体流程:
- 生产者在业务处理事务中,新增一条需要投递的消息记录,并提交本地事务
- 后台任务循环扫描消息记录表,对未完成投递的消息进行重投;对MQService已响应ACK的消息标记为已完成(保证消息100%投递到服务端)
- 消费者消费消息,并保证消费幂等性,消费完成后给MQService响应ACK
- 异常时,消费者在处理事务时发生异常,可以使用重试机制或者死信队列进行异常处理
可能存在的问题:
- 业务流程侵入性
- 生产者端需要新增消息表记录相关流程
- 消费者可能需要新增消费记录表来保证消费幂等性、消息消费顺序
- 可能出现消息重复投递
- 异常处理机制,如何处理重试和死信队列
- producer、consumer重试时,性能和可伸缩性的影响
eg:
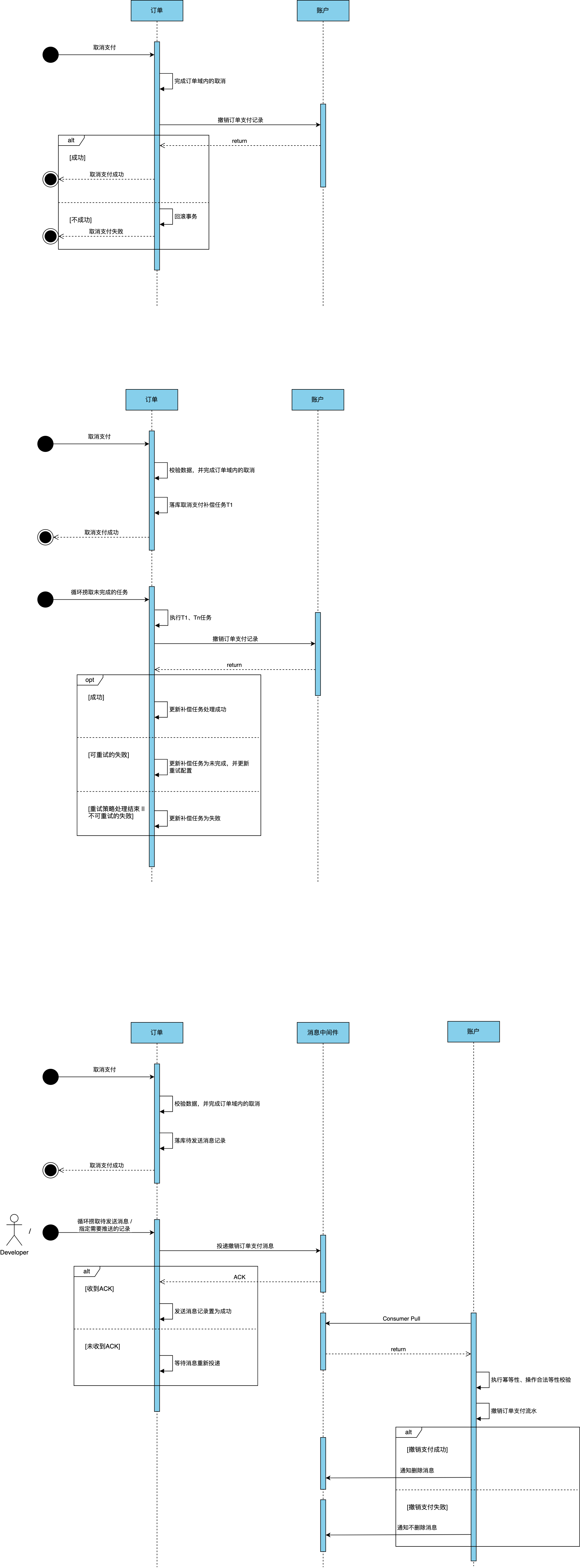
思考:
- 生产者里新增的中间表有那些作用?
- 如何在保证业务质量的同时,减少框架对生产者,消费者的业务代码侵入性
- 生产者能否在业务流程中,直接投递消息,收到MQService响应ACK后,忽略中间表相关步骤?
幻读:
定义:
在一个事务中,当某些行被另一个事务插入或删除时,第一个事务重新查询时发现有新的行出现,就好像出现了幻觉一样。具体来说,幻读是指在同一个事务中,由于其他事务的插入或删除操作导致查询结果的变化。
RC
| 事务A | 事务B |
|---|---|
| 开启事务,查询某一范围的数据 | |
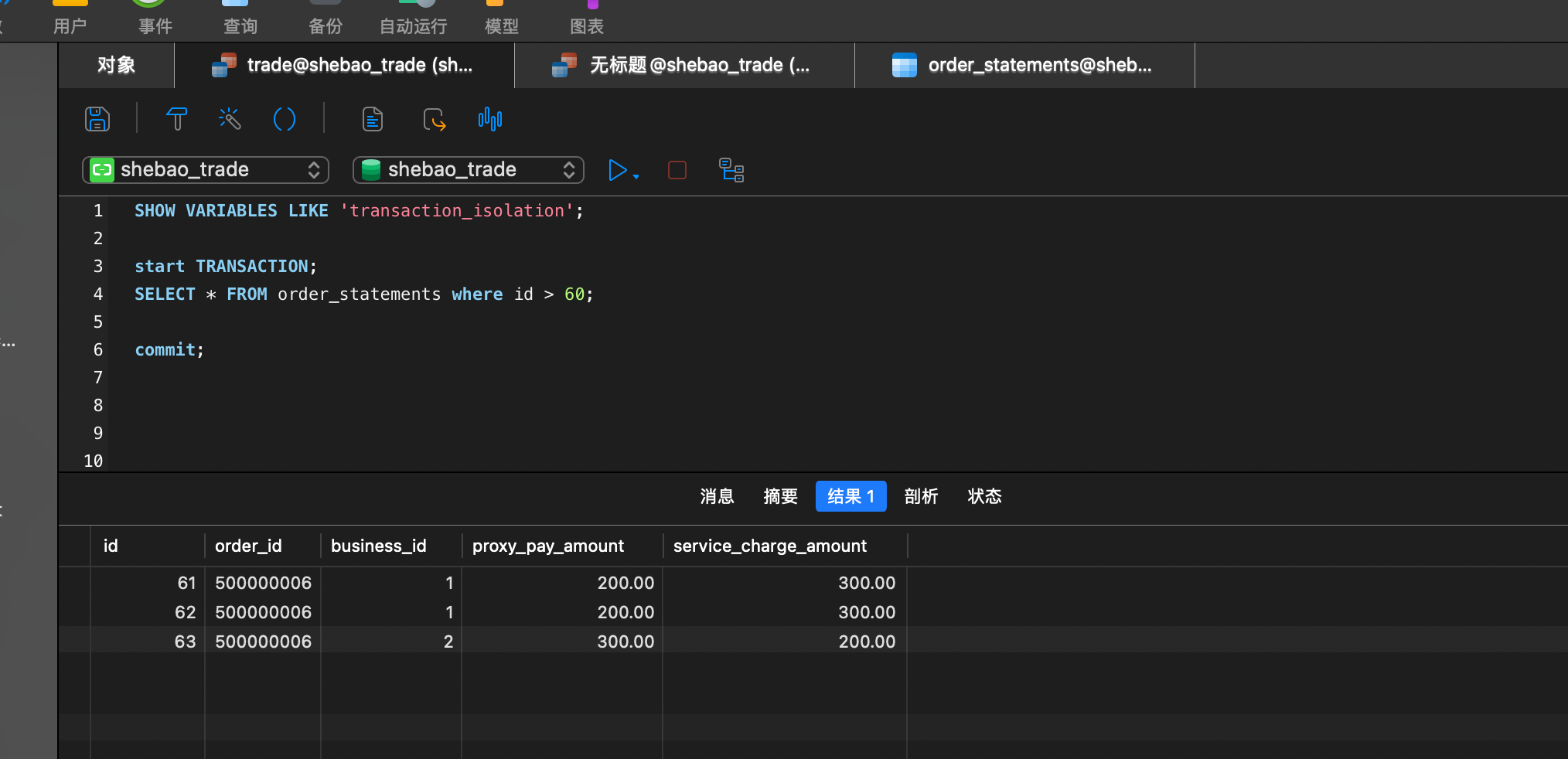 | |
| 开启事务,插入数据 | |
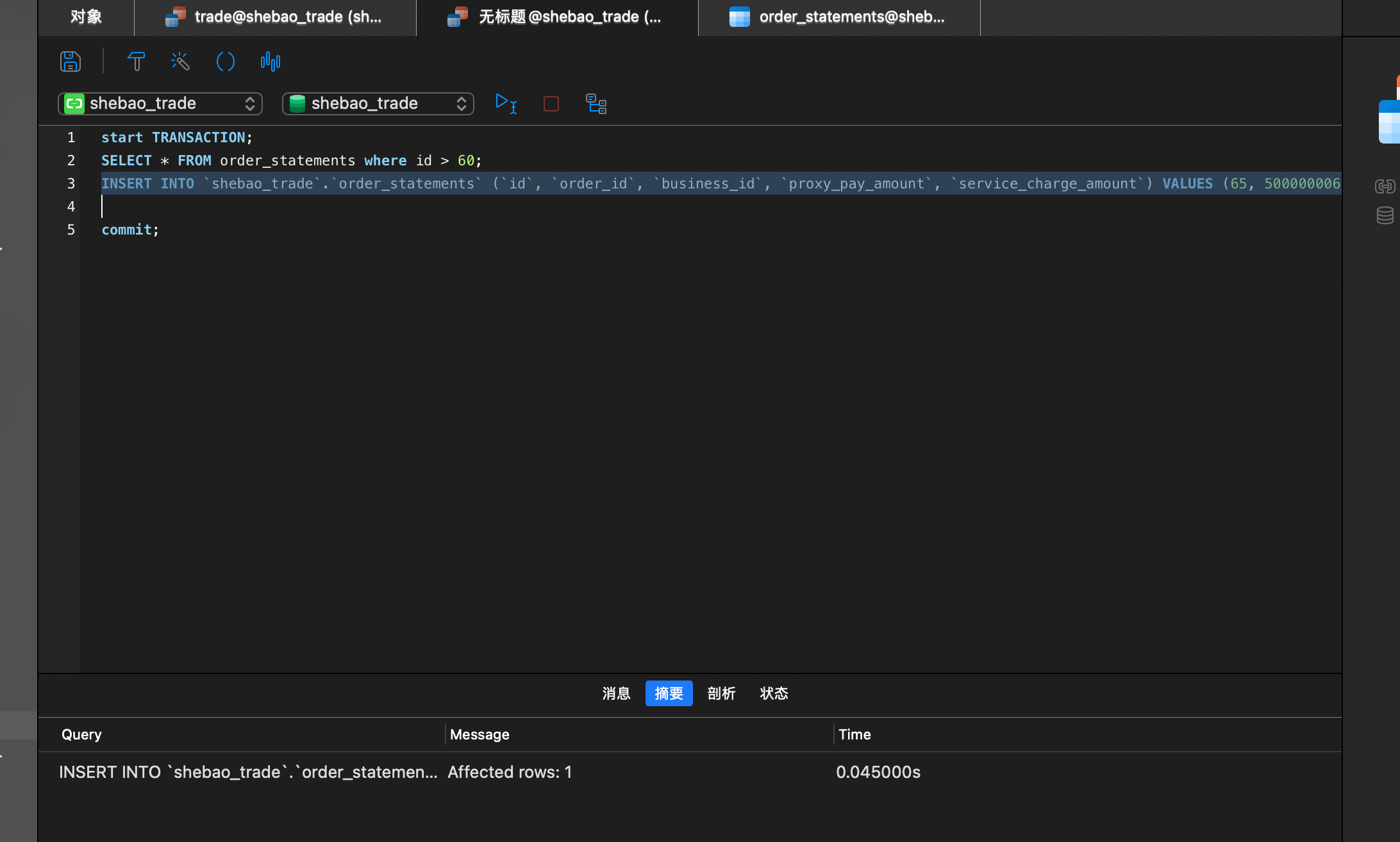 | |
| 继续查询指定范围的数据,未发现变化 | |
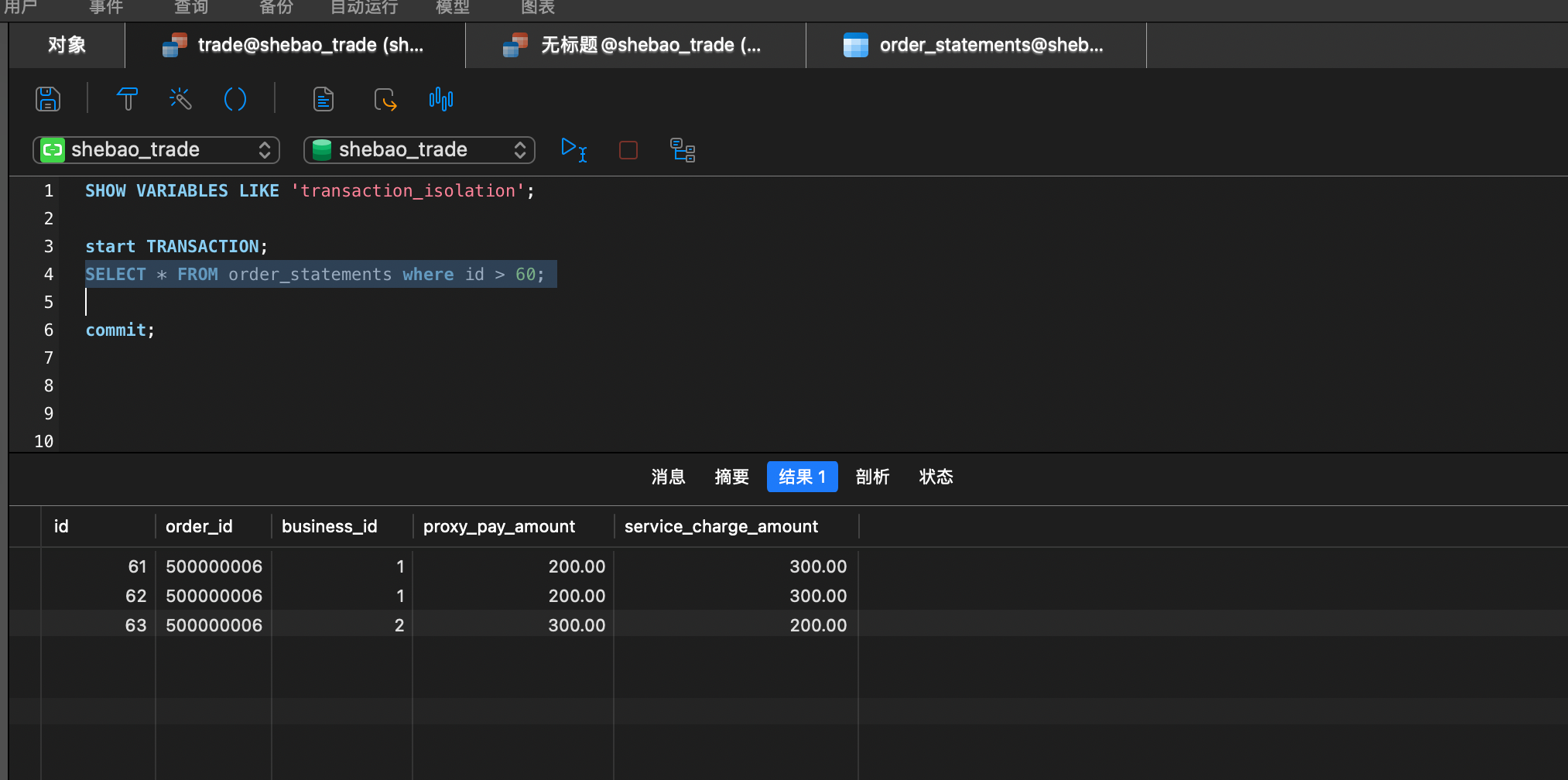 | |
| 提交事务 | |
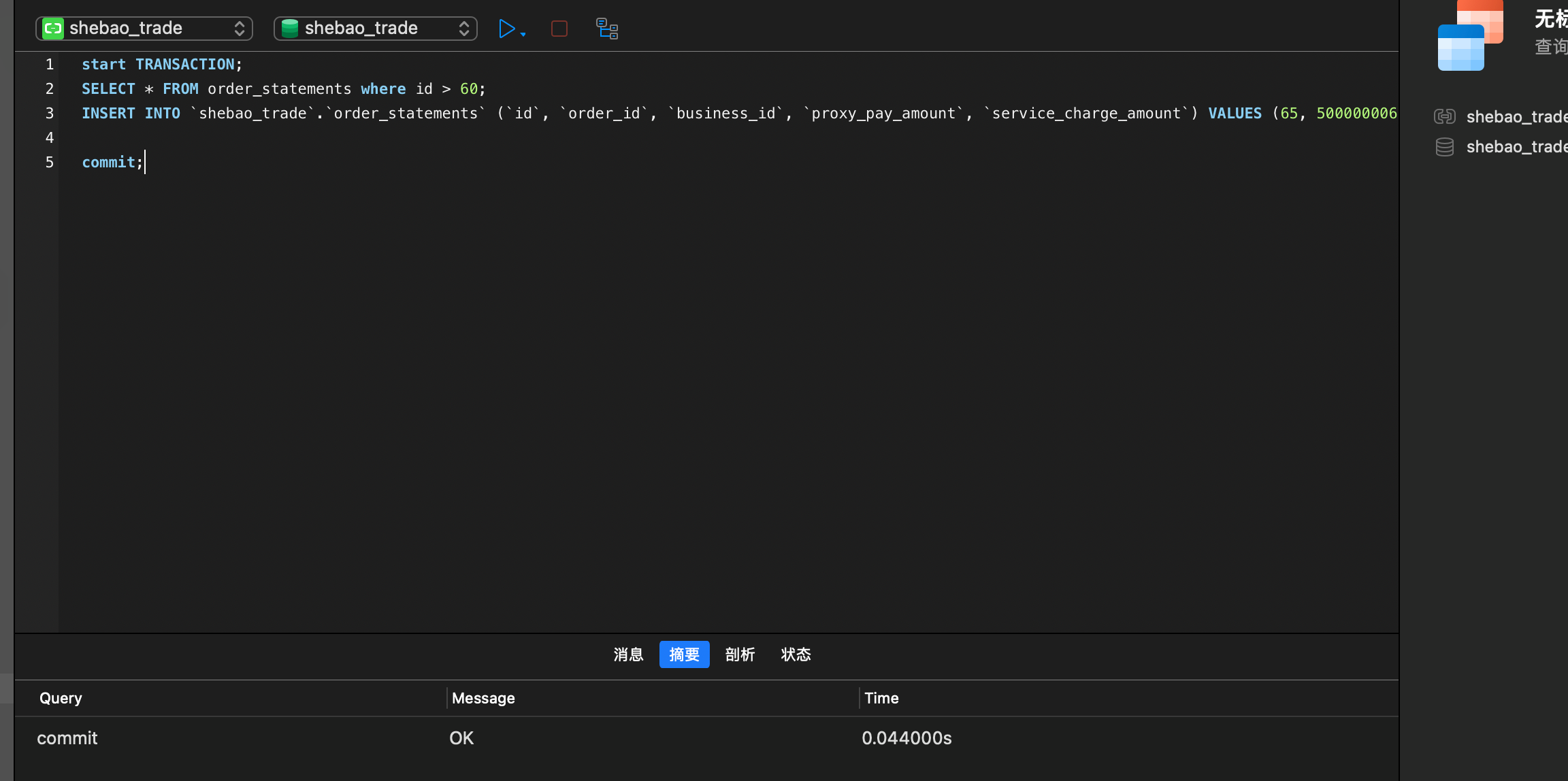 | |
| 继续查询指定范围的数据,发现数据变化(幻读) | |
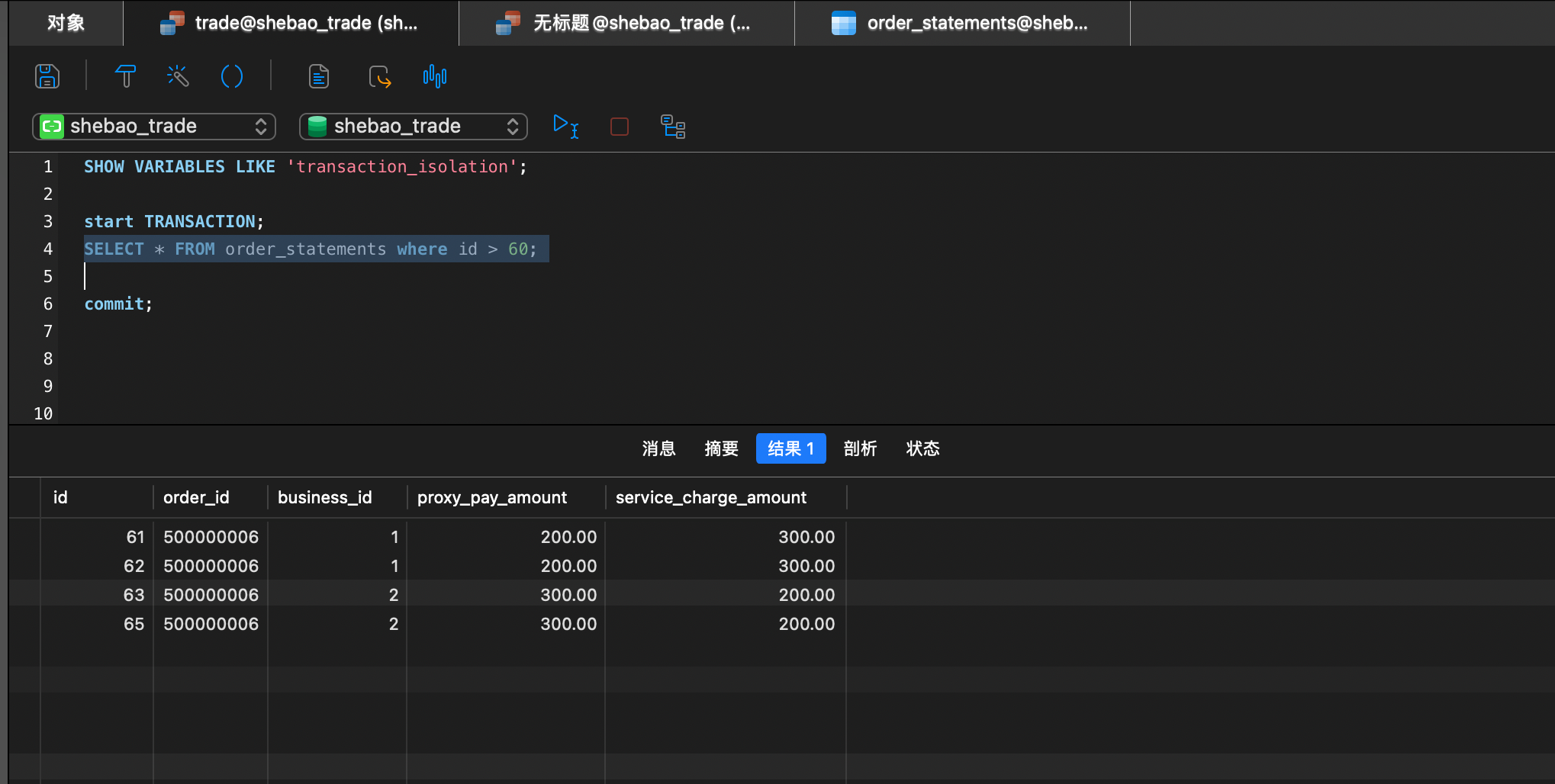 |
RR

说明:
- 开启事务A,查询不到id=6的数据
- 开启事务B,新增id=6的数据,并提交
- 由于 MVCC 的版本控制,事务A无法查找到B已提交的id=6的数据(幻读问题已解决)
- 更新id=6的数据,MVCC将数据的修改版本更新到为前事务的版本,此时便可以在事务A中查到id=6的数据
问题:
- 当前PolarDB下DB的隔离级别是什么?为什么?
方案:“孔乙己-茴的四种写法”
方案1:
// 定义扣款函数
@Transactional
function deductWithRedisLock(accountId, amount) {
lockKey = "lockPrefix:" + accountId // 锁的键名
lockValue = generateUniqueValue() // 生成唯一标识作为锁的值
// 1. 锁:获取锁,如果获取成功则执行扣款操作
if redisClient.setnx(lockKey, lockValue) == 1 {
try {
balance = accountReponsitory.get(accountId)
//2.判 判断账户余额
if balance >= amount {
// 3. 更新 扣款操作
newBalance = balance - amount
accountReponsitory.set(accountId, newBalance)
print("扣款成功,余额:" + newBalance)
} else {
print("扣款失败:余额不足")
}
} finally {
// 释放锁
if redisClient.get(lockKey) == lockValue {
redisClient.del(lockKey)
}
}
} else {
print("扣款失败:获取锁失败")
}
}
方案2:
// 定义扣款函数
@Transactional
function deductWithDBLock(accountId, amount) {
// 获取账户信息并加锁,lockType=X或S
account = accountRepository.findAndLockById(accountId, "X")
// 判断账户余额
if account.balance >= amount {
// 扣款操作
newBalance = account.balance - amount
account.balance = newBalance
accountRepository.save(account)
print("扣款成功,余额:" + newBalance)
} else {
print("扣款失败:余额不足")
}
}
方案3:
// 定义扣款函数
@Transactional
function deductWithOptimisticLock(accountId, amount) {
// 获取账户信息
account = accountRepository.findById(accountId)
// 判断账户余额
if account.balance >= amount {
// 计算新余额
newBalance = account.balance - amount
// 更新账户余额时使用乐观锁
updatedRows = accountRepository.updateBalanceWithOptimisticLock(accountId, newBalance, account.version)
if updatedRows > 0 {
print("扣款成功,余额:" + newBalance)
} else {
print("扣款失败:并发更新冲突")
}
} else {
print("扣款失败:余额不足")
}
}
方案4:
// 定义扣款函数
@Transactional
function deductAndUpdateBalance(accountId, changeAmount) {
// 直接更新余额
rowsUpdated = accountRepository.updateBalance(accountId, changeAmount)
// 检查更新结果
if rowsUpdated > 0 {
// 查询更新后的余额
newBalance = accountRepository.getBalance(accountId)
// 检查新余额是否大于0
if newBalance > 0 {
print("扣款成功,余额:" + newBalance)
} else {
print("扣款失败:扣款后余额小于等于0")
}
} else {
print("扣款失败:更新余额时发生错误")
}
}
UPDATE accounts SET balance = balance - :changeAmount WHERE account_id = :accountId
【优缺点讨论】
















 953
953

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









