







今天来整理下如何在读CSV的时候正确处理列名。
csv文件自带列标题
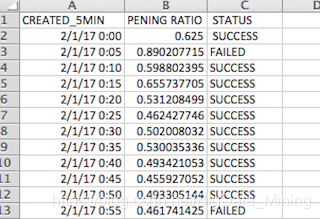
原始数据是有列标的,用excel打开是这样的:
import pandas as pd
df_example = pd.read_csv('Pandas_example_read.csv')
这种方法等同于
df_example = pd.read_csv('Pandas_example_read.csv', header=0)
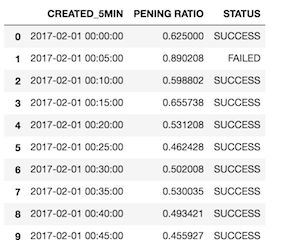
结果都是:
csv文件有列标题,但是想自己换成别的列标题:
2.1 在读数之后自定义标题:
df_example = pd.read_csv('Pandas_example_read.csv')
df_example.columns = ['A','B','C']
2.2 在读数的同时自定义标题:
df_example = pd.read_csv('Pandas_example_read.csv', names=['A', 'B','C'])
或者
df_example = pd.read_csv('Pandas_example_read.csv', header=0, names=['A', 'B','C'])
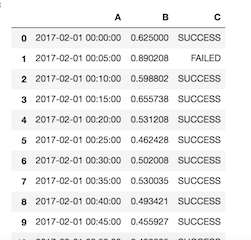
2.1和2.2效果都是一样的,读取文件,并且改列名:
csv文件没有列标题,从第一行就直接开始是数据的录入了:
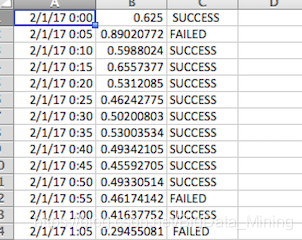
原始数据是没有列标的,用excel打开呈现是这样的:
df_example_noCols = pd.read_csv('Pandas_example_read_withoutCols.csv', header=None)
这个时候一定要加’header=None’, 这样读进来的列名就是系统默认的0,1,2… 序列号:
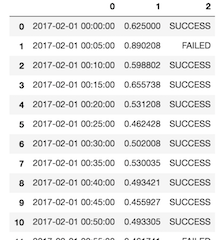
csv文件没有列标题,但是自己想加上列标题:
4.1 读进来数之后加上标题
df_example_noCols = pd.read_csv('Pandas_example_read_withoutCols.csv', header=None)
df_example_noCols.columns = ['A', 'B','C']
4.2 读数的同时加标题
df_example_noCols = pd.read_csv('Pandas_example_read_withoutCols.csv', names=['A', 'B','C'])
或者
df_example_noCols = pd.read_csv('Pandas_example_read_withoutCols.csv', header=None, names=['A', 'B','C'])
注意:这里不可以用’header=0’, 用了之后就会导致第一行的数据先被当成了列名,然后又被重命名覆盖,结果是第一行的数据丢失。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









