









在视频编码中,帧内预测是通过空域相邻像素预测当前块的像素,传统编码中帧内预测技术包括角度模式、DC和Planar模式,现在很多都开始使用深度学习来进行帧内预测。
大部分使用深度学习进行帧内预测的网络主要分为:
- 全连接神经网络
- 全卷积神经网络
- 卷积神经网络和全连接神经网络的结合。
网络的输入输出分为:
- 从相邻重建像素直接获得当前块的预测像素
- 输入相邻重建像素和HEVC的预测像素,输出当前块的增强预测像素(相当于对传统的帧内预测像素进行增强)
这里对各种方法进行一下总结,也梳理一下思路。
目录
2017-DCC-Convolutional Neural Networks based Intra Prediction for HEVC
2018-TIP-Fully Connected Network-Based Intra Prediction for Image Coding
2018-Neural network based intra prediction for video coding
2019-TIP-Context-adaptive neural network based prediction for image compression
2019-Video intra prediction using convolutional encoder decoder network
2019-TCSVT-Multi-Scale Convolutional Neural Network-Based Intra Prediction for Video Coding
2019-TMM-Generative Adversarial Network-Based Intra Prediction for Video Coding
2020-TMM-Enhanced Intra Prediction for Video Coding by Using Multiple Neural Networks
2020-VCIP-Fully Neural Network Mode Based Intra Prediction of Variable Block Size
2017-DCC-Convolutional Neural Networks based Intra Prediction for HEVC
本论文提出了使用卷积神经网络网络进行帧内预测(intra prediction convolutional neural network , IPCNN)
本文的结构如下,在训练过程中,从HEVC帧内编码中提取一组训练样本,该组训练样本由用于8x8 PU(粉色块)的帧内预测块(来自HEVC)和其三个最近的8×8重建块(绿色块)组成。网络(IPCNN)的输出是通过从输入块中减去原始块而生成的残差块。经过训练过程,就实现了一个完整的网络。该网络将用于帧内预测过程。
在帧内预测过程中,HEVC最佳帧内预测模式得到的8x8 PU及其相邻的三个8x8重建块输入到IPCCN中,得到残差块,输入块减去残差块即可得到目标块。

IPCCN的网络结构如下,使用残差学习的方式。网络的输入是8x8预测PU及其相邻的三个8x8重建块,最终输出是最终预测块,将右下的8x8块作为HEVC的最终预测块。所有的卷积核都是3x3。

训练仅对亮度分量进行, 针对Qp={22,27,32,37}各自训练单独的网络,实验结果如下所示:(基于HM14.0)

2018-TIP-Fully Connected Network-Based Intra Prediction for Image Coding
这是第一篇使用全连接神经网络进行帧内预测的论文,称之为IPFCN(intra prediction using fully connected net)。整个网络架构如下图所示:

对于待预测的NxN大小的块,网络的输入是相邻重建像素(个像素,L设置为8),通过K层全连接神经网络,输出预测的NxN像素。其中除最后一层外,其余层的都是用PReLU作为激活函数。
训练
损失函数使用欧式损失,并为了防止过拟合添加了正则项。训练数据使用New York city library images,使用HM在Qp{22,27,32,27}下进行编码,将四种Qp编码的图像混合起来作为最终的训练集(这样可以对各Qp编码情况下公用同一个网络)。对于训练对(R,Y),将参考像素R从码流中解析获得,Y为原始值从原始图像中获得。作者认为对于某些图像块内容过于复杂,不具备普适性,因此将其从训练集剔除,具体做法是计算预测块原始块之间的MSE,并计算整个图像所有块的平均MSE,仅保留块MSE小于两倍平均MSE的块。
提出两种训练IPFCN的方法:
- 对训练数据进行分类,将角度模式2-34分为一类,DC和Planar模式分为一类,两种数据得到两个模型,称为IPFCN-D
- 使用全部数据进行训练获得单一模式,称为IPFCN-S
网络超参数
① 网络的深度:
为了研究IPFCN的合适深度,本文收集了不同深度的IPFCN的验证误差,如下图所示。可以看到2层模型的结果和1层模型几乎一样。原因可能是2层模型中仅有的一个非线性层不足以提升性能。相比之下,3层模型比2层模型有很大的性能提升。额外的非线性层导致了质的飞跃。从4层模型的结果来看,我们发现性能可以进一步提高。然而,如果深度继续增加(例如从5到8),性能开始下降。8层模型的结果与3层模型非常接近。最终选择使用深度为4的网络

② 网络的维度:
本文还对不同维度的网络进行了研究,为了方便起见,模型中的所有层(除了最后一层)都具有相同的尺寸。测试尺寸从128增加到2048,增加了2倍。可以观察到,当维度处于增长的早期阶段(例如从128到256)时,性能具有相对较大的改善。然而,当维度继续增加时,改善的幅度变小。1024维模型的结果与2048维模型非常接近。因此,对于8x8 block使用维度为1024

集成在HEVC中
对于HEVC,帧内预测是基于TU进行的,尺寸为4x4 - 32x32,基于上面的分析,本文采用了深度为4的网络,对于4x4块,网络维度为512,对于8x8和16x16的块,网络维度为1024,对于32x32的块,网络维度为2048。IPFCN在编码端的选择如下所示,对于IPFCN的使用,使用CU级Flag进行标识,并对64x64块禁用IPFCN。

实验结果
基于HM16.9,CTC条件下ALL INTRA配置,实验结果如下所示 ,可用看出IPFCN-D平均可以节省3.4%的Bdrate,IPFCN-S可以节省2.9%的Bdrate。

2018-Neural network based intra prediction for video coding
本论文使用全连接神经网络进行帧内预测,使用了两个网络,一个网络用于产生预测信号,另一个网络用于选择神经网络的预测模式。
① 产生预测信号
预测网络的结构如下图所示,是4层全连接,网络输入为上两行和左两列的重建像素,经过全连接神经网络后输出预测像素。

② 预测模式的选择
为了捕捉不同类型的图像内容,本文对于max(M,N)<=32的块设计了35种预测模式,其余块设计了11种预测模式。本文使用了另外一个基于相邻重建像素来预测模式的网络,网络结构如下,网络的输入为相邻重建像素,输出为各模式的概率,然后选出概率最大的模式,将该模式传到解码端。

实验结果如下所示(High Tier:[22; 27; 32; 37],Main Tier:[27; 32; 37; 42])


2019-TIP-Context-adaptive neural network based prediction for image compression
本文认为全连接网络对于小块有更好的性能,而卷积网络对大块会有更好的性能,因此本文提出了针对小块使用全连接网络对大块使用卷积神经网络,这组神经网络称为预测神经网络组(Prediction Neural Networks Set ,PNNS)
同时,本文还认为用于帧内预测的神经网络的不需要在存在失真的上下文中训练,这意味着在未失真的上下文中训练的神经网络可以在失真的上下文中很好地泛化,即使对于严重的失真也是如此,即使用原始数据训练的网络可用很好地用在HM各种Qp编码的情况。
本文使用当前块的相邻重建像素预测当前块,如下图所示,Y为mxm大小的当前块,X0(mx2m)和X1(3mxm)为相邻重建像素。

全连接神经网络结构如下图,全连接网络用于4x4块和8x8块

卷积神经网络的结构如下,卷机神经网络用于其余块:

下图总结了基于神经网络的帧内预测方案在HEVC中的集成。当没有上下文可用时,即上下文超出解码图像的边界时,即上下文左上角的像素不在解码图像内时,就会出现这种情况。这种情况下,不使用神经网络,返回Y的零预测O。

两种集成方式:
- Substitution:替代HEVC中传统预测模式中最不常用的模式(本文替代的是18)
- Switch:在传统模式和PNNs之间进行选择,修改HEVC的帧内编码如下:

PNNs-Switch方法和IPFCN的性能比较如下:

2019-Video intra prediction using convolutional encoder decoder network
本文提出了一种使用卷积编解码结构进行帧内预测的网络,称为IPCED。IPCED编码器网络构建了一种新的多尺度跳跃结构,将深层的全局信息和浅层的局部信息结合起来。IPCED解码器网络采用多级分支来生成不同级别的预测,并以由粗到精的方式合成帧内预测结果。
IPCED针对尺寸为4x4、8x8、16x16和32x32的TU分别单独设计了网络,TU尺寸越大,网络结构越复杂。IPCED的网络结构如下图所示。IPCED的输入是当前PU(HEVC的预测值)及其左、左上和上方的三个相邻重建块,输出为细化后的当前PU的预测值。
在训练期间,IPCED可用看做是GAN网络的生成器,训练时后会接一个鉴别器网络D用于训练解码器网络,网络D不用于测试。

训练
使用MSE作为Loss训练编码器-解码器网络,由于在实践中,MSE Loss通常无法捕捉到图像的高频细节,为了解决这个问题,本文在训练时添加了对抗Loss ,即生成器网络G的Loss定义如下;

其中,λ设置为0.999。增强IPCED学习原始图像的自然分布,提高预测结果的真实性。请注意,
不会反向传播到编码器,因为解码器负责合成图像,而编码器用于提取和压缩特征。
训练时先对G网络进行预训练,在预训练之后再联合训练G和D网络,优化目标如下:
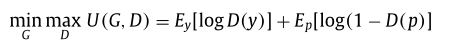
训练数据来源于 BSD500 database,使用HM16.0编码,对于不同Qp和不同尺寸的PU,训练单独的网络。
实验结果
将IPCED集成到HM16.0中,在CTC测试条件下,使用Qp{22,27,32,37}测试,与HEVC Baseline相比,其性能如下:

IPCED在各种尺寸PU选中为最佳模式的百分比:

2019-TCSVT-Multi-Scale Convolutional Neural Network-Based Intra Prediction for Video Coding
本文提出了一种用于帧内预测的多尺度卷积神经网络(multi-scale convolutional neural network , MSCNN)。MSCNN的输入是HEVC的预测像素及其相邻的重建像素,通过MSCNN生成更准确的预测像素。
MSCNN的网络结构如下图所示,整个网络包括两个部分,第一部分是多尺度特征提取网络,第二部分是重构网络。
使用多尺度网络的原因:作者认为,在视频编码中,复杂和纹理区域通常用小块编码,而平滑区域通常用大块编码。在卷积操作期间,小块中的像素与L-Shape的像素接近,并且小卷积核足以利用小块中的像素和L-Shape之间的相关性。但是大块中的像素离L-Shape较远,要用大的卷积核。代替对不同的块大小使用不同的核大小,提出了多尺度特征提取结构,这样可以使用固定大小的3x3卷积核。

特征提取网络
特征提取网络包含三部分:下采样,卷积、上采样。对于不同的块尺寸,包含不同的下采样尺度。具体地说,首先以不同的下采样率(例如1/2、1/4、1/8)对输入块进行下采样。然后利用卷积块得到不同尺度的特征图。最后,对不同比例的特征地图进行上采样并级联在一起。
特征提取网络的输入是当前块的预测像素和相邻L-shape的重建像素,本文对NxN块将L形的宽度设置为N/2。
本文使用的卷积块如下图所示。,ConvBlock-2L和ConvBlock-3L分别由两个卷积核和三个卷积核组成。

对于不同尺寸的TU,使用不同的卷积块。对于小块,其与相邻像素的相关性较强,因此使用简单的多尺度提取网络,而对于大块,块尺寸越大,其右下角的像素和左上相邻像素相关性越小,因此使用复杂的多特征提取网络。在提取不同大小块的特征图时,为了充分利用上下文信息,需要使用不同的感受野。对于小块通常用浅层网络,对于大块通常用深层网络。本文中对4x4块使用2层网络,对其余尺寸块使用3层网络。
TU4x4、8x8、16x16和32x32的特征提取网络结构如下图所示。

重建网络
重构网络是用于整合多尺度网络提取的特征,生成更准确的预测像素,其网络结构如下图所示:

训练:
训练数据是使用HM在Qp{22,27,32,37}编码生成的数据进行混合得到的。作者认为对于平滑块,传统的HEVC预测已经可以很好地进行预测了,因此,训练仅使用具有复杂纹理的块,即仅对满足如下条件的块进行训练,其中MSE表示预测块和原始块的MSE,表示图像的MSE。

对于亮度4x4、8x8、16x16和32x32尺寸的TU和色度4x4、8x8和16x16尺寸的TU分别训练单独的模式,即共七种模型。
集成在HEVC
在CU级标识MSCNN是否使用,如果MSCNN flag为True则该CU中的全部TUs均使用MSCNN。MSCNN集成在编码端和解码端的框图如下图所示。

在HM中,亮度分量预测模式的RDO过程中,首先操作粗糙模式决策(RMD),其中计算35个帧内预测模式的基于阿达玛变换的代价,并选择N(N=8、8、3、3,对于4×4、8×8、16×16、32×32和64×64)个最佳模式。然后使用该N个模式和最可能的模式MPM构建模式候选列表。然后,应用MSCNN通过率失真优化(RDO)从模式候选列表中选择最佳帧内预测模式。
对于色度分量预测模式的RDO,MSCNN仅应用于色度预测中的最佳模式。
在HM16.9的性能如下:

MSCNN的像素占比

2019-TMM-Generative Adversarial Network-Based Intra Prediction for Video Coding
本文提出使用GAN网络来进行帧内预测,和Deep Learning-Based Chroma Prediction for Intra Versatile Video Coding类似,该文章也是在CTU级别使用神经网络进行预测。
整个网络的网络如下图所示,网络的输入为当前CTU及其相邻的三个重建CTU,通过Generator产生预测后的像素,再将当前CTU的产生预测像素和其相邻重建像素重新组合起来通过鉴别器网络。鉴别器网络包括Global Discriminator和Local Discriminator,其中Global Discriminator用于鉴别组合后的图,Local Discriminator用于鉴别预测得到CTU块。

通过网络共产生35种预测模式,其中多种模式的不同是通过控制CTU的初始像素实现的,即按照如下公式产生待预测CTU的初始像素值,其中X取值范围为{0, 1, 2, …, 34}。在训练期间X值是在{0, 1, 2, …, 34}内随机产生的,在测试阶段,需要逐个遍历35种初始值产生的预测像素选出最佳的预测模式。
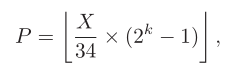
基于HM16.17的性能:(其中1 mode指的是用0初始化预测像素)

本文同时还比较了去掉鉴别器的性能,说明了鉴别器对预测值的修正还是很重要的。

2020-TMM-Enhanced Intra Prediction for Video Coding by Using Multiple Neural Networks
本文提出了两种基于神经网络网络的帧内预测模式NM集成到传统的帧内预测模式TM的方法,一种是在传统的帧内预测模式基础上,增加新的NM模式,但是该方法需要重新设计帧内的模式编码,本文讨论了添加1/3/5/7种NM模式的方法;另一种是使用NM模式替换TM模式,包括替换应用概率最高的模式或替换应用概率最低的模式。两种集成方法细节可以在参考原论文中,这里不讨论。
基于上述两种集成方案,本文使用了全连接神经网络作为NM模式,全连接神经网络的结构如下图所示,网络的输入为相邻的五个重建块,输出为当前PU的预测像素。

训练数据是使用HM在Qp=27下进行编码产生,并且仅针对N=8块进行训练。
这里不放测试性能了,因为测试是将HM限制为8x8的帧内编码,参考价值不大。
本论文最核心的贡献就是对两种集成方法的讨论,感兴趣的朋友可以在原论文查看细节。
2020-VCIP-Fully Neural Network Mode Based Intra Prediction of Variable Block Size
本文提出了使用神经网络替代传统方法进行帧内预测。针对4x4-32x32的35种预测模式,每种模式都提出了对应的神经网络模型。对于4x4和8x8的TU,使用全连接网络,对于16x16和32x32TU,使用卷积网络。本文使用的全连接网络和卷积网络的结构如下图所示。


作者分析了全连接神经网络的节点数目和卷积神经网络的卷积核数目对性能影响,如下图所示,对于4x4和8x8TU,全连接网络使用128个节点,对于16x16和32x32TU,卷积神经网络使用16个卷积核。

总共有35个NMs,通过以下步骤选择最佳NM。首先,通过SATD成本之和选择几个候选模式。为块4 x 4和8 x 8选择了八个候选,而为其他块选择了三个候选。除了SATD选择的候选模式之外,MPM模式也被加到候选模式列表中。创建候选模式列表后,通过比较RD Cost来确定最佳NM。
训练:
使用HM在Qp{22,27,32,37}下编码,然后按照最佳模式保存块(每个块对应一种最佳模式,按照最佳模式对块分类),先使用全部块对模型预训练,再在预训练的基础上,对每种模式的块进行微调。
集成在HM16.9的性能如下表所示:
















 683
683











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









