







本帖用来记录JVET中各家单位将深度学习用于帧间预测的各种方法,为编码与深度学习结合提供思路。
目前深度学习用于帧间编码的几个思路:
- 双向加权预测
- 插帧
- 时域滤波
- 预测值增强
一、双向加权预测
在帧间编码中,双向加权预测是将前向参考帧得到的预测块和后向参考帧得到的预测块进行加权融合,得到最终的预测块。在VVC中,加权预测方法包含:
其中可以使用网络代替传统融合方式。
JVET-V0076 AHG11: Deep-learning based inter prediction blending(InterDigital)
本提案提出使用网络代替a和b进行双向融合预测。NN模式仅用于亮度分量,色度分量仍使用传统的融合方式。
本提案提出三种NN融合模式,下表是这三种模式使用条件:
| Mode | fast |
| normal |
|
| fast | Same as normal + block width and height greater than 8 |
| slow | Same as normal without condition d) and e) |
如果该三种模式均不可用,则使用传统融合方式。
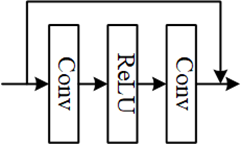
本提案提出使用一个小型全卷积网络进行融合预测,网络结构如下图所示,其中网络的输入为前向预测块和后向预测块,网络的输出是融合后的预测块。本提案提出两个版本的网络结构(N=5和N=6)。其中,除最后一层外的所有层都使用 ReLU 激活函数,并需要通过对最后一层卷积后的输出进行clip操作。

训练:
使用Tensorflow 2.0 训练。 训练集为BVI-DVC 和 UVG 数据集,具体训练信息如下表所示。输入的两个块提取的是满足应用BDOF条件的两个预测块,用于数据集中每个序列的子集。
| Network Information in Training Stage | ||
| Mandatory | GPU Type | GPU: Tesla-P100-16GB |
| Framework: | Tensorflow 2.x | |
| Number of GPUs per Task | 1 | |
|
|
| |
| Epoch: | 10 | |
| Batch size: | 256 | |
| Training time: | ~100h | |
| Training data information: | UVG, BVI-DVC | |
| Training configurations for generating compressed training data (if different to VTM CTC): | VTM-11.0, QP {22, 27, 32, 37, 42} | |
| Optional |
|
|
| Patch size | 16x16x2 | |
| Learning rate: | 1e-4 | |
| Optimizer: | ADAM | |
| Loss function: | SATD | |
| Preprocessing: | none | |
| Other information: |
| |
推理:
网络在 16 位整数上量化,操作使用 32 位整数执行。
| Network Information in Inference Stage | |||
| Small version (N=5) | Medium version (N=6) | ||
| HW environment: | |||
| GPU Type | none | none | |
| Framework: | Standalone C++ | Standalone C++ | |
| Number of GPUs per Task | 0 | 0 | |
|
|
| ||
| Total Parameter Number | 7k | 9k | |
| Parameter Precision (Bits) | 16 (I) | 16 (I) | |
| Memory Parameter (MB) | ~0.013 MB | ~0.0178 MB | |
| MAC (kMACs) | 11.3 kMACs/pix | 16.6 kMACs/pix | |
| Optional |
|
| |
| Total Conv. Layers | 5 | 6 | |
| Total FC Layers | 0 | 0 | |
| Total Memory (MB) | |||
| Batch size: | 1 block at a time | 1 block at a time | |
| Patch size | Depending on the block (8x8..16x16) | Depending on the block (8x8..128x128) | |
| Peak Memory Usage | 16*3*3*26*26=95kB | 16*3*3*28*28=110kB | |
| Other information: |
| ||
实验结果:
Small NN-Normal mode
| Random access Main10 | ||||||
| BD-rate Over VTM11.0 | ||||||
| Y-PSNR | U-PSNR | V-PSNR | EncT | DecT | bit DIFF | |
| Class A1 | -0.26% | -0.05% | 0.05% | 481% | 579% | 0% |
| Class A2 | -0.77% | -0.30% | -0.21% | 554% | 832% | 0% |
| Class B | -0.56% | -0.28% | -0.20% | 553% | 751% | 0% |
| Class C | -0.76% | -0.39% | -0.32% | 488% | 825% | 1% |
| Class E | ||||||
| Overall | -0.60% | -0.27% | -0.18% | 520% | 746% | 0% |
| Class D | -1.51% | -1.04% | -0.77% | 500% | 1165% | 1% |
| Class F | -0.15% | -0.02% | -0.10% | 426% | 369% | 0% |
Medium NN-Normal mode
| Random access Main10 | ||||||
| BD-rate Over VTM11.0 | ||||||
| Y-PSNR | U-PSNR | V-PSNR | EncT | DecT | bit DIFF | |
| Class A1 | -0.42% | -0.15% | 0.04% | 648% | 752% | 0% |
| Class A2 | -1.06% | -0.37% | -0.31% | 757% | 1082% | 0% |
| Class B | -0.83% | -0.40% | -0.35% | 731% | 1033% | 0% |
| Class C | -1.24% | -0.46% | -0.41% | 645% | 1168% | 1% |
| Class E | ||||||
| Overall | -0.90% | -0.36% | -0.28% | 695% | 1011% | 0% |
| Class D | -2.68% | -1.45% | -1.10% | 654% | 1624% | 2% |
| Class F | -0.23% | -0.07% | -0.12% | 561% | 442% | 0% |
JVET-X0102 AHG11: Deep neural network for inter bi-prediction
本提案提出对某些类型的块使用网络代替VVC中的三种融合预测方法。
网络框架如下图所示,其中P0和P1代表前向和后向预测块,Pf表示最终的预测块。
两个输入预测块中的各自被送入三个 CNN 层以增加特征数。 利用点积和sigmoid激活函数可以得到两个特征之间的attention map。 之后,注意力图然后乘以原始嵌入特征。 然后将嵌入的特征和提取的特征级联起来。 这些特征依次通过两个 CNN 层和 10 个残差块(没有batch normalization)和两个 CNN 层。
网络中所有的卷积均为3x3,通道数均为64(最后一个卷积为1),激活函数为LeakyRelu。

训练:
使用 BVI-DVC 数据集。两个预测块来自RA配置下的 VTM-11.0 解码器。Ground Truth 是原始块。
该数据集包含大约 9M 对块。
| Training information | ||
| Mandatory | GPU Type | GeForce RTX 2080 Ti-11GB |
| CPU Type | Intel(R) Xeon(R) CPU E5-2620 v4 @ 2.10GHz | |
| Framework: | PyTorch 1.4.0 | |
| Number of GPUs per Task: | 1 | |
| Number of Iterations: | 600k | |
| Batch size: | 64 | |
| Total Parameter Number: | 1295k | |
| Parameter Precision (Bits): | 32 (F) | |
| Training data information: | BVI-DVC | |
| Training configurations for generating compressed training data (if different to VTM CTC): | VTM-11.0, QP {22, 27, 32, 37, 42} | |
| Optional | Patch size | 32x32x2, 64x64x2, 128x128x2 |
| Learning rate: | 4e-4 | |
| Optimizer: | ADAM | |
| Loss function: | Charbonnier penalty function | |
| Preprocessing: | Augmentation : Random horizontal and vertical flips, 90° rotation | |
推理:
将所提出的方法适用于三种块类型(128x128、64x64 和 32x32),集成到VTM11.0中。
| Inference information | ||
| Mandatory | GPU Type | Quadro RTX 8000-48GB |
| CPU Type | Intel(R) Xeon(R) Gold 6256 CPU @ 3.60GHz | |
| Framework: | Standalone C++, PyTorch 1.7.1 | |
| Number of GPUs per Task | 1 | |
| Total Parameter Number | 1295k | |
| Parameter Precision (Bits) | 32 (F) | |
| Optional | Total Conv. Layers | 32 |
| Total FC Layers | 0 | |
| Batch size: | 1 block at a time | |
| Patch size | Depending on the block (128x128, 64x64, 32x32) | |
实验结果:
| Random access Main10 | |||||
| Over VTM-11.0 | |||||
| Y | U | V | EncT | DecT | |
| Class A1 | |||||
| Class A2 | |||||
| Class B | -0.98% | 0.25% | 0.19% | 6494% | 660% |
| Class C | -0.96% | 0.06% | 0.11% | 3634% | 715% |
| Class D | -2.08% | -0.31% | -0.41% | 3029% | 1012% |
| Overall | -1.32% | 0.02% | -0.02% | 4296% | 771% |
二、预测值增强
JVET-Y0090-AHG11: Neural Network Based Motion Compensation Enhancement for Video Coding
本提案提出了一种基于神经网络的运动补偿增强方法。 所提出的方法在帧间编码的方形编码块完成运动补偿过程后强制执行。 目前,该方法仅适用于大小为 128x128、64x64、32x32、16x16 和 8x8 的编码块的亮度分量。
图 1 展示了所提出的运动补偿增强神经网络的结构,其中图 1(a) 展示了整体网络结构,图 1(b) 展示了残差单元的网络结构。 所提出的网络将运动补偿编码块作为输入,其中编码块可以是单向预测的或双向预测的。 编码块首先被送入卷积层以提取特征图。 之后,特征图通过 10 个残差单元 [1] 和一个卷积层。 最后,通过将输入编码块和学习到的残差信息相加得到神经网络输出。
对于图 1 中的所有卷积层,使用 3x3 的卷积核大小。 除最后一层外,每个卷积层中的特征图数量设置为 64。最后一个卷积层产生 1 个特征图。 对于激活函数,使用 ReLU。

训练:
在训练阶段,PyTorch 1.7.0 用于训练所提出的神经网络。 对于不同的编码块大小(128x128、64x64、32x32、16x16 和 8x8)和 QP(22、27、32、37 和 42),所提出的网络是独立训练的。 BVI-DVC [3] 数据集用于训练神经网络。 这些序列由具有 RA 配置的 VTM-11.0-nnvc-1.0 压缩。 如[2]所建议的,培训信息总结在表2中。
| Training information | ||
| Mandatory | GPU Type | NVIDIA Tesla V100-SXM2-32GB |
| CPU Type | Intel(R) Xeon(R) Platinum 8163 CPU @ 2.50GHz | |
| Framework: | PyTorch 1.7.0 | |
| Number of GPUs per Task: | 1 | |
| Epoch: | 50 | |
| Batch size: | 64 | |
| Total Parameter Number: | 776.71k/model (25 models in total) | |
| Parameter Precision (Bits): | 32 (F) | |
| Training data information: | BVI-DVC | |
| Training configurations for generating compressed training data (if different to VTM CTC): | QP {22, 27, 32, 37, 42} | |
| Optional | Patch size | 128x128, 64x64, 32x32, 16x16, 8x8 |
| Learning rate: | 1e-4 | |
| Optimizer: | ADAM | |
| Loss function: | L2 | |
| Preprocessing: | Normalize to 0~1 | |
推理
在推理阶段,PyTorch 1.7.1 用于在 VTM-11.0-nnvc-1.0 中执行基于神经网络的运动补偿增强。 如 [2] 所建议的,推断信息总结在表 1 中。
| Inference information | ||
| Mandatory | GPU Type | N/A |
| CPU Type | Intel(R) Xeon(R) CPU E5-2682 v4 @ 2.50GHz | |
| Framework: | PyTorch 1.7.1 | |
| Number of GPUs per Task | 0 | |
| Total Parameter Number | 776.71k/model (25 models in total) | |
| Parameter Precision (Bits) | 32 (F) | |
| Memory Parameter (MB) | 3.03M/model (25 models in total) | |
| MACs | 783.1k/pixel | |
| Optional | Total Conv. Layers | 22 |
| Total FC Layers | 0 | |
| Batch size: | 1 block at a time | |
| Patch size | Depending on the block (128x128, 64x64, 32x32, 16x16, 8x8) | |
实验结果
| Random access Main10 | |||||
| Over VTM-11.0-nnv-1.0 | |||||
| Y | U | V | EncT | DecT | |
| Class A1 | |||||
| Class A2 | |||||
| Class B | -1.23% | 0.12% | 0.11% | 2029% | 22315% |
| Class C | -1.20% | -0.09% | -0.14% | 1804% | 19404% |
| Overall | |||||
| Class D | -2.95% | -1.36% | -1.05% | 1700% | 29635% |















 3973
3973











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









