






 本文介绍了sklearn库中的几个关键函数,包括datasets.load_iris()用于加载鸢尾花数据集,train_test_split()用于将数据随机划分为训练集和测试集,以及model_selection.cross_val_score()进行交叉验证。鸢尾花数据集包含150个样本和四个特征,train_test_split()函数可以按比例随机分割数据,而cross_val_score()则用于评估模型的泛化能力。
本文介绍了sklearn库中的几个关键函数,包括datasets.load_iris()用于加载鸢尾花数据集,train_test_split()用于将数据随机划分为训练集和测试集,以及model_selection.cross_val_score()进行交叉验证。鸢尾花数据集包含150个样本和四个特征,train_test_split()函数可以按比例随机分割数据,而cross_val_score()则用于评估模型的泛化能力。
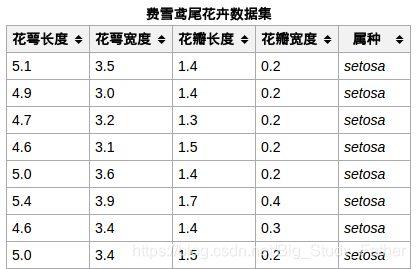
datasets.load_iris() iris鸢尾花数据集
样本大小150,每个样本包含四个特征和样本类别,所以iris数据集是一个150行5列的二维表。我们根据样本的四个特征(data)对其进行分类,分类结果放在第五列(target或label)
函数介绍:
http://sklearn.lzjqsdd.com/modules/generated/sklearn.datasets.load_iris.html
from sklearn import datasets
iris=datasets.load_iris()
print("打印样本大小")
print(iris.data.shape)
print("打印data前5行")
print(iris.data[:3])
print("打印target 大小数据")
print(iris.target.shape)
print(iris.target)
输出:
打印样本大小
(150, 4)
打印data前5行
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]]
打印target 大小数据
(150,)
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
源文:
https://blog.csdn.net/java1573/article/details/78865495
train_test_split() 将矩阵随即划分为训练子集和测试子集,并返回划分好的训练集测试集样本和训练集测试集标签
函数介绍:
https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.train_test_split.html
格式:
X_train,X_test, y_train, y_test =cross_validation.train_test_split(train_data,train_target,test_size=0.3, random_state=0)
主要参数:
train_data: 被划分的样本特征集
train_traget: 被划分的样本标签
test_size: (0,1)间的浮点数表示样本占比,整数则表示样本数量
random_state:随机数种子。
示例代码:
>>> import numpy as np
>>> from sklearn.model_selection import train_test_split
>>> X, y = np.arange(10).reshape((5, 2)), range(5)
>>> X
array([[0, 1],
[2, 3],
[4, 5],
[6, 7],
[8, 9]])
>>> list(y)
[0, 1, 2, 3, 4]
>>>
>>> X_train, X_test, y_train, y_test = train_test_split(
... X, y, test_size=0.33, random_state=42)
...
>>> X_train
array([[4, 5],
[0, 1],
[6, 7]])
>>> y_train
[2, 0, 3]
>>> X_test
array([[2, 3],
[8, 9]])
>>> y_test
[1, 4]
源文:
https://www.cnblogs.com/bonelee/p/8036024.html
sklearn.model_selection.cross_val_score() 交叉验证(Cross Validation 又称 CV)
函数介绍:
https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.cross_val_score.html
格式:
sklearn.cross_validation.cross_val_score(
//必选参数
estimator, //自己选定的模型; 估算量,算子,用于拟合数据
X, //训练集(自变量部分) ;需要拟合的数据,可以被实例化为list或array
//可选参数
y=None, //训练集(因变量部分)
scoring=None, // 评价函数
cv=None, //交叉验证生成器或可迭代的次数
n_jobs=1, //同时工作的cpu个数(-1代表全部)
verbose=0, //详细程度
fit_params=None, //传递给估算器的拟合方法参数
pre_dispatch=‘2*n_jobs’ //控制并行执行期间调度的作业数量。
)

















 3891
3891

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









