







Redis 6.0 之后为何引入了多线程?6.0 之前为什么不使用多线程?
官方解析
在 Redis 6.0 之前,Redis 是单线程的,这是因为 Redis 的主要瓶颈是在 CPU 上。但是随着硬件的发展,现代服务器的 CPU 核心数已经达到了几十个,这就导致 Redis 单线程模型无法充分利用多核处理器的性能。因此,Redis 6.0 引入了多线程,以提高 Redis 在多核处理器上的性能。
Redis 6.0 之前为什么不使用多线程,主要有以下几个原因:
-
Redis 单线程模型相对简单,容易维护和调试,代码逻辑也比较清晰。
-
Redis 的主要瓶颈在于 CPU,而不是 I/O,因此采用多线程模型并不能显著提高性能。
-
Redis 是一个内存型数据库,它的性能主要受到 CPU 和内存带宽的限制。采用多线程模型会增加线程之间的竞争和锁等开销,反而可能降低 Redis 的性能。
但是随着硬件的发展,多核处理器已经成为了现代服务器的标配,因此 Redis 引入多线程的举措可以更好地发挥硬件的性能,提高 Redis 的吞吐量和响应速度。
redis 的多线程
-
redis 在 6.0 支持的多线程是指网络 IO 的多线程,而 redis 的指令执行还是单线程的
-
redis 的性能取决于网络 IO,内存和 CPU
-
在 redis6.0 之前的处理网络 IO 是单线程的,服务端对客户端的请求,socket 的连接,指令数据的接收,解析都由一个线程来执行,效率较低
-
redis6.0 之后支持网络 IO 的多线程,通过多线程并行的执行来提高网络 IO 的处理效率
-
redis 的服务端对用户传过来的指令的执行还是单线程的
-
redis 的网络 IO 多线程默认是关闭的,需要在 redis.conf 中进行配置
-
redis 对指令的执行不改为多线程,是因为指令的执行是在内存中,没有性能的瓶颈,且 redis 对数据结构进行了很多的优化。若 redis 指令的执行支持多线程,则需要对数据的操作加锁的同步,这会导致性能的下降,代价较大。
-
redis6.0 之前不使用多线程的原因:
-
redis 的性能瓶颈为内存和网络,官方说明 redis 几乎不存在 CPU 的性能瓶颈问题
-
redis 使用单线程,其可维护性提高
-
redis 若使用多线程,会增加需要对数据加锁,这增加了系统的复杂度,且会造成性能下降
-
关键词:网络IO多线程,指令执行单线程,内存,网络,CPU,默认关闭,可维护性,加锁同步
Redis 6.0 之后,引入多线程主要是为了解决 Redis 在处理大规模数据时,单线程的性能瓶颈问题,以提高 Redis 的处理能力和效率。
在 Redis 6.0 之前,Redis 只采用单线程的方式进行处理,这是因为 Redis 的核心是一个基于内存的键值对存储系统,它的瓶颈主要在于 CPU 的计算能力,而不是 I/O 操作的速度。
在单线程模式下,Redis 可以使用简单的事件驱动模型,来实现高效的网络通信和事件处理,避免了线程切换和上下文切换带来的开销,同时也避免了多线程之间的锁竞争问题。因此,在 6.0 之前,Redis 一直采用单线程模式运行。
但是随着 Redis 的应用场景不断扩大和升级,Redis 也面临着越来越大规模、越来越高并发的挑战,单线程模式已经不能满足这些需求了。因此,在 Redis 6.0 中引入了多线程技术,以利用多核 CPU 的计算能力,提高 Redis 的性能和处理能力。
Redis 6.0 引入多线程后,采用了多种技术手段来实现多线程操作的安全和稳定性,如使用锁和原子操作来保证数据一致性和线程安全。
需要注意的是:
-
Redis 6.0 中的多线程并不是完全替代了单线程模型,而是在其基础上引入了多线程支持,通过将一些负载耗时的操作(如I/O操作)交给后台线程处理,从而提高 Redis 的性能。同时,在多线程模式下,Redis 仍然保留了所有的单线程模式特性,如 ACID 事务等。
-
Redis 6.0 中多线程的使用是可选的,并且可以通过配置文件进行启用或禁用,以便在不同的应用场景下选择最适合的运行模式。
Redis 6. 0 引入多线程的原因有两个:
-
充分利用 CPU 多核,6.0 之前主线程只能利用一个核,多线程可以利用服务器 CPU 资源。
-
多线程任务可以分摊 Redis 同步 IO 读写负荷。
Redis 6.0 默认情况下是关闭多线程的,需要在 redis.conf 配置文件中进行配置:
io-threads-do-reads yes
开启多线程后需要设置线程数,否则不会生效。线程数应该小于机器核数。官方建议 4 核的机器建议设置为 2 或 3 个线程,8 核的建议设置为 6 个线程 .
Redis 在处理客户端的请求时是单线程的,其中执行命令阶段,由于 Redis 是单线程来处理命令的,所有每一条到达服务端的命令不会立刻执行,所有的命令都会进入一个 Socket 队列中,当 socket 可读则交给单线程事件分发器逐个被执行. Redis6.0 引入多线程主要是为了解决 Redis 在处理客户端请求时网络 I/O 消耗过大的问题。多线程主要用来处理网络数据的读写和协议解析,而执行命令仍然是单线程.
Redis 的多线程网络模型并不是标准的 Multi-Reactors/Master-Workers 模型,I/O 线程任务仅仅是通过 socket 读取客户端请求命令并解析,但没有真正去执行命令. Redis 的多线程方案中,删除操作是可以被其他线程异步处理的,这些删除操作可以通过多线程的方式异步处理.
总的来说,Redis 引入多线程的目的是为了提高 Redis 的性能,充分利用 CPU 多核,分摊 Redis 同步 IO 读写负荷,解决 Redis 在处理客户端请求时网络I/O消耗过大的问题。
之前为什么不使用多线程的原因:
-
Redis 6.0 之前不使用多线程的原因是因为 Redis 通过 AE 事件模型以及 IO 多路复用等技术,处理性能非常高,因此没有必要使用多线程。单线程机制使得 Redis 内部实现的复杂度大大降低,Hash 的惰性 Rehash、Lpush 等等“线程不安全”的命令都可以无锁进行。
-
Redis 将所有数据放在内存中,内存的响应时长大约为 100 纳秒,对于小数据包,Redis 服务器可以处理 80,000到 100,000 QPS,这也是 Redis 处理的极限了,对于 80% 的公司来说,单线程的 Redis 已经足够使用了。因此,在处理性能方面,Redis 6.0 之前的单线程机制已经足够。
-
但是随着互联网业务系统所要处理的线上流量越来越大,Redis 的单线程模式会导致系统消耗很多 CPU 时间在网络 I/O 上从而降低吞吐量。因此,Redis 6.0 引入了多线程来提高性能。
-
Redis 6.0 支持多线程有两个原因:一是可以充分利用服务器 CPU 资源,目前主线程只能利用一个核;二是多线程任务可以分摊 Redis 同步 IO 读写负荷。通过将主线程 IO 读写任务拆分出来给一组独立的线程处理,使得多个 socket 读写可以并行化,但是 Redis 命令还是主线程串行执行。
-
Redis 的多线程网络模型实际上并不是一个标准的 Multi-Reactors/Master-Workers 模型,I/O 线程任务仅仅是通过 socket 读取客户端请求命令并解析,却没有真正去执行命令。因此,Redis 6.0 的多线程模型相对于其他多线程模型更加轻量级。
-
Redis 6.0 默认没有开启多线程,但可以在 conf 文件中进行配置。关于线程数的设置,官方建议 4 核的机器设置为 2 或 3 个线程,8 核的机器建议设置为 6 个线程,线程数一定要小于机器核数。
题目二
HTTP 协议中 GET 和 POST 有什么区别?分别适用于什么场景?
官方解析
HTTP 协议中 GET 和 POST 是两种常用的请求方法,它们的区别如下:
-
参数传递方式不同
-
GET 请求参数是在 URL 中以键值对的形式传递的,例如:http://www.example.com/?key1=value1&key2=value2。
-
而 POST 请求参数是在请求体中以键值对的形式传递的。
-
-
参数传递大小不同 GET 请求参数有大小限制,因为 URL 长度有限制,不同的浏览器和服务器对 URL 长度的限制不同,一般为 2048 个字符。而 POST 请求参数没有大小限制,因为它们是以请求体的形式传递的。
-
安全性不同
-
GET 请求的参数是明文传输的,因为参数在 URL 中,如果涉及敏感信息(如密码),容易被窃取或暴露在浏览器历史记录、代理服务器日志等地方。
-
而 POST 请求的参数在请求体中传输,相对安全一些,但是也需要注意参数加密和防止 CSRF 攻击等问题。
-
-
GET 和 POST 适用的场景不同:
-
GET 请求适用于获取数据,如浏览网页、搜索等。因为 GET 请求参数以明文形式传输,容易被拦截和篡改,所以不适用于提交敏感信息的操作。
-
POST 请求适用于提交数据,如登录、注册、发布内容等。因为 POST 请求参数在请求体中传输,相对安全一些,可以提交敏感信息,但是需要注意参数加密和防止 CSRF 攻击等问题。
-
既然评论区都有这么多答案了,那还缺我一个吗?
-
关于二者的区别 和 使用场景 ( 详见评论区 )
-
参数位置
-
安全性
-
幂等
-
长度
-
缓存
-
使用场景
-
拓展区别:
- GET 产生一个 TCP 数据包 ,浏览器会把 header 和 data 一并发送出去,服务器响应 200
- POST 产生两个 TCP 数据包 , 浏览器先发送 header,服务器响应 100(continue),然后再发送 data,服务器响应 200
在网络良好的情况下,差别不大。当然也不是所有的 POST 都发两次包,FireFox 在处理 POST 的时候,会一次性直接发送 header 和 data。(从这里也可以看出来,GET 和 POST 之所以产生区别,是因为浏览器/服务器)
补充说明( 把 get 和 post 结合 Http ):
-
关于 get 和 post 甚至是 delete,put 等方法
-
1、他们都是 Http 发送请求的方法
-
2、Http 是基于 TCP 的
-
所以,其实 GET,POST 都是 TCP 连接
-
既然如此,从 TCP 协议来理解,GET 和 POST 没有本质区别,
-
-
所以其实
-
get也可以带RequestBody
-
post也可以有?+参数
-
-
之所以出现各种差异
-
是因为Http 的规定和服务器/浏览器的限制,让 get 不能让 url 超过一定的长度限制,让 get 的 RequestBody 不被服务器处理,让 Post 的 url 的路径参数(?+参数)不被处理
-
题目三
什么是零拷贝?说一说你对零拷贝的理解?
官方解析
零拷贝(Zero-Copy)是一种高效的数据传输技术,它可以将数据从内核空间直接传输到应用程序的内存空间中,避免了不必要的数据拷贝,从而提高了数据传输的效率和性能。
在传统的数据传输方式中,当应用程序需要从磁盘、网络等外部设备中读取数据时,操作系统需要先将数据从外部设备拷贝到内核空间的缓冲区,然后再将数据从内核空间拷贝到应用程序的内存空间中,这个过程中需要进行两次数据拷贝,浪费了大量的 CPU 时间和内存带宽。
而使用零拷贝技术,数据可以直接从外部设备复制到应用程序的内存空间中,避免了中间的内核空间缓冲区,减少了不必要的数据拷贝,提高了数据传输的效率和性能。
在网络编程中,零拷贝技术可以用于大文件的传输、网络文件系统的读写、数据库查询等场景中,提高数据传输的效率和响应速度。同时,零拷贝技术也可以减少系统内存的开销,提高系统的稳定性和可靠性。
零拷贝(Zero-Copy)是一种高效的数据传输技术,它可以将数据从内核空间直接传输到应用程序的内存空间中,避免了不必要的数据拷贝,从而提高了数据传输的效率和性能。
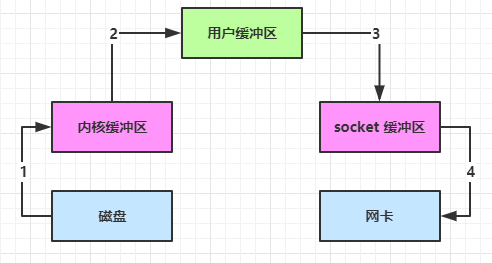
传统IO:
零拷贝:
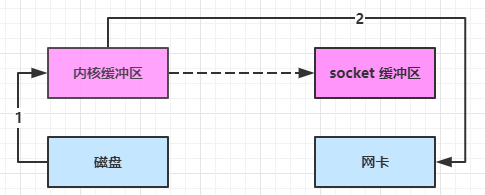
-
java 调用 transferTo 方法后,要从 java 程序的用户态切换至内核态,使用 DMA 将数据读入内核缓冲区,不会使用 cpu
-
只会将一些 offset 和 length 信息拷入 socket 缓冲区,几乎无消耗
-
使用 DMA 将 内核缓冲区的数据写入网卡,不会使用 cpu
整个过程仅只发生了一次用户态与内核态的切换,数据拷贝了 2 次。所谓的【零拷贝】,并不是真正无拷贝,而是在不会拷贝重复数据到 jvm 内存中,零拷贝的优点有
-
更少的用户态与内核态的切换
-
不利用 cpu 计算,减少 cpu 缓存伪共享
-
零拷贝适合小文件传输
零拷贝零拷贝(Zero-copy)是一种技术,它可以让计算机在处理数据时,不必在内存之间来回复制数据,从而降低内存复制的开销,提高计算机的性能和效率。具体来说,零拷贝是指在数据传输过程中,数据可以直接从发送端内存区域被传输到接收端内存区域,而无需在传输过程中进行任何复制操作。从而可以减少上下文切换以及CPU的拷贝时间。它是一种 I/O 操作优化技术。
传统的 IO 执行流程
传统 IO 流过程包括 read 和 write 过程
-
read:把数据从磁盘读到内核缓冲区,再拷贝到用户缓冲区
-
write:先把数据写到 socket 缓冲区,再写入到网卡设备
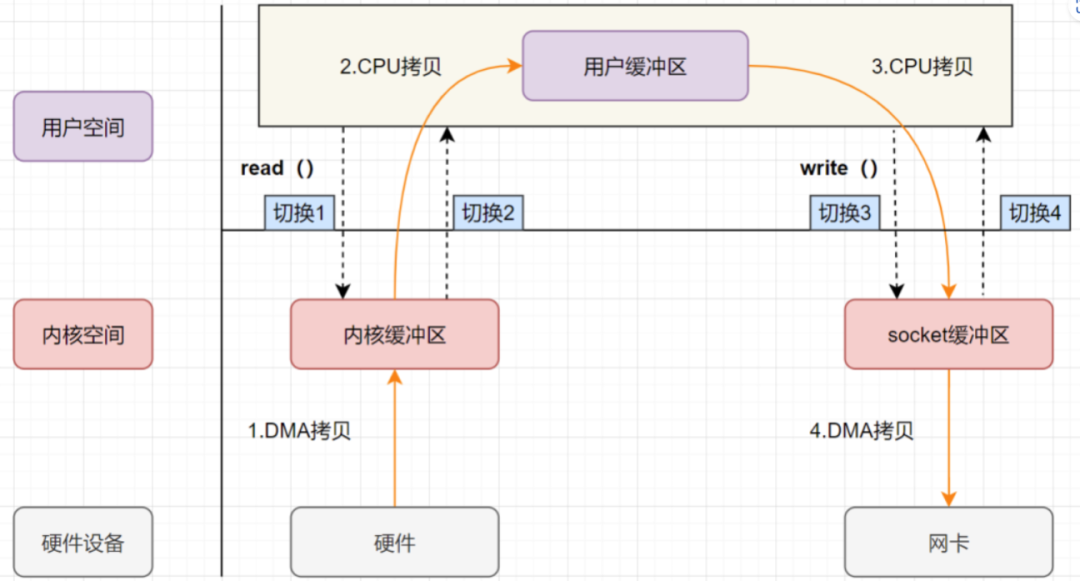
-
用户应用进程调用 read 函数,向操作系统发起 IO 调用, 上下文从用户态转为内核态(切换1)
-
DMA 控制器把数据从磁盘中,读取到内核缓冲区。
-
CPU 把内核缓冲区数据,拷贝到用户应用缓冲区, 上下文从内核态转为用户态(切换2),read 函数返回
-
用户应用进程通过 write 函数,发起 IO 调用,上下文从用户态转为内核态(切换3)
-
CPU 将用户缓冲区中的数据,拷贝到 socket 缓冲区
-
DMA 控制器把数据从 socket 缓冲区,拷贝到网卡设备, 上下文从内核态切换回用户态(切换 4),write 函数返回
从流程图可以看出,传统 IO 的读写流程,包括了 4 次上下文切换(4 次用户态和内核态的切换),4 次数据拷贝(两次 CPU 拷贝以及两次的 DMA 拷贝)
零拷贝实现的几种方式这里的零拷贝其实是根据内核状态划分的,在这里没有经过 CPU 的拷贝,数据在用户态的状态下,经历了零次拷贝,所以才叫做零拷贝,但不是说不拷贝。
-
mmap + write
-
sendfile
-
带有 DMA 收集拷贝功能的 sendfile
sendfile+DMA scatter/gather 实现的零拷贝sendfile 表示在两个文件描述符之间传输数据,它是在操作系统内核中操作的,避免了数据从内核缓冲区和用户缓冲区之间的拷贝操作,因此可以使用它来实现零拷贝。
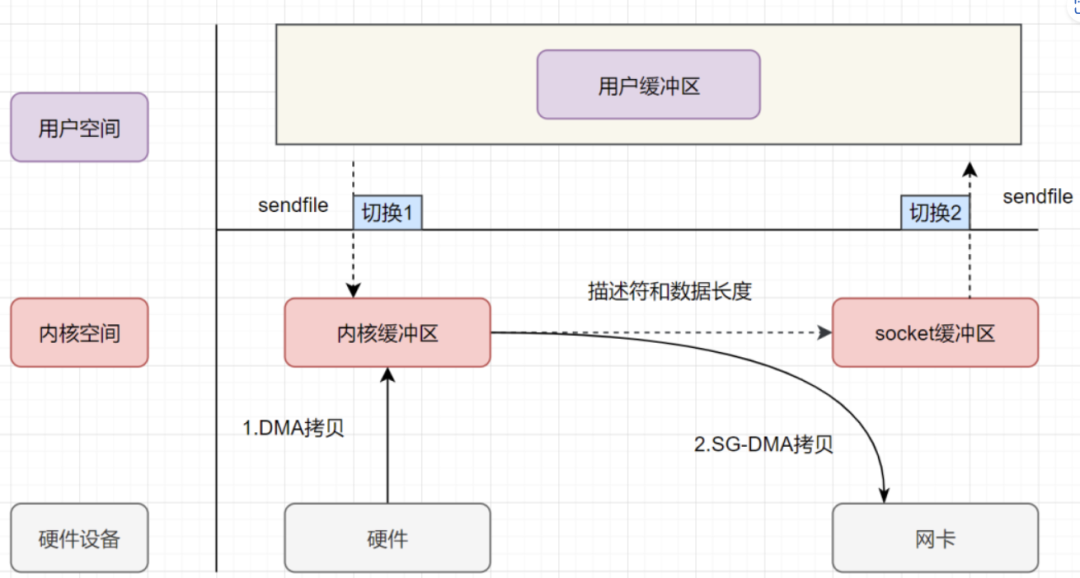
-
用户进程发起 sendfile 系统调用, 上下文(切换1)从用户态转向内核态
-
DMA 控制器,把数据从硬盘中拷贝到内核缓冲区。
-
CPU 把内核缓冲区中的 文件描述符信息(包括内核缓冲区的内存地址和偏移量)发送到 socket 缓冲区
-
DMA 控制器根据文件描述符信息,直接把数据从内核缓冲区拷贝到网卡
-
上下文(切换2)从内核态切换回用户态,sendfile 调用返回。
可以发现,sendfile+DMA scatter/gather 实现的零拷贝,I/O 发生了 2 次用户空间与内核空间的上下文切换,以及 2 次数据拷贝。其中 2 次数据拷贝都是包 DMA 拷贝。这就是真正的零拷贝(Zero-copy) 技术,全程都没有通过 CPU 来搬运数据,所有的数据都是通过 DMA 来进行传输的。
零拷贝(Zero-copy)是一种高效的数据传输机制,在追求低延迟的传输场景中十分常用。
它是一种 I/O 操作优化技术,指计算机执行 IO 操作时,CPU 不需要将数据从一个存储区域复制到另一个存储区域,从而可以减少上下文切换以及 CPU 的拷贝时间。
传统的数据传输方法需要将数据从一个缓冲区拷贝到另一个缓冲区,而零拷贝技术可以直接在内核空间中完成数据传输,避免了数据复制的过程,从而提高了数据传输的效率。
在传统的数据传输方法中,数据需要经过多次复制才能到达目标缓冲区,这个过程包含了用户空间和内核空间之间的多次上下文切换,这些上下文切换会导致系统的性能下降。而零拷贝技术可以避免这些上下文切换,从而提高了系统的性能。例如,当应用程序需要将大量的数据写入到磁盘或者网络中时,使用零拷贝技术可以减少数据复制的过程,提高数据传输的效率。
零拷贝技术的实现主要有以下几种方式:
-
文件描述符传递:通过文件描述符的传递,将数据从一个进程传递到另一个进程,避免了数据复制的过程。
-
sendfile()函数:在 Linux 系统中,sendfile()函数可以将一个文件描述符指向的文件内容直接传输到一个 socket 文件描述符中,避免了数据复制的过程。
-
mmap()函数:mmap()函数可以将一个文件映射到内存中,避免了数据复制的过程。
总之,零拷贝是一种高效的数据传输机制,在追求低延迟的传输场景中应用广泛。使用零拷贝技术可以避免数据复制的过程,减少上下文切换,提高系统的性能。
前端
题目一
怎么使用 CSS3 来实现动画?你实现过哪些动画?
官方解析
CSS3 提供了丰富的动画效果,通过使用 CSS3 动画可以实现许多视觉效果,比如旋转、平移、缩放、淡入淡出等。
CSS3 动画的实现需要使用 @keyframes 规则和 animation 属性,具体的实现步骤如下:
定义关键帧 使用 @keyframes 规则定义动画关键帧。例如,定义一个旋转动画:
@keyframes spin {
from { transform: rotate(0deg); }
to { transform: rotate(360deg); }
}
这个关键帧定义了从 0 度到 360 度的旋转动画。
应用动画 使用 animation 属性将动画应用到元素上。例如,将上面定义的 spin 动画应用到一个元素:
div {
animation: spin 2s linear infinite;
}
这个样式定义了一个 2 秒线性旋转动画,并且无限循环。
CSS3 动画的优点在于它不需要使用 JavaScript,可以通过 CSS 代码实现各种复杂的动画效果,并且动画效果比使用 JavaScript 实现的动画效果更加平滑。
在实际开发中,我们可以使用 CSS3 动画来实现各种动态效果,比如页面切换、元素滚动、菜单展开等。具体实现要根据具体的需求来选择使用哪种动画效果,一些常见的动画效果包括:
-
淡入淡出
-
旋转
-
缩放
-
平移
-
拉伸
-
闪烁 我们可以使用 CSS3 动画来实现这些效果,提高用户体验和交互性。
css3 动画的实现的方案,大概有以下方案:
-
js 的 animation() 方法实现动画
-
@keyframes + animation:这是一个实现动画的组合,必须一起使用。
i. @keyframes——创建动画
(1)在 @keyframes 中用 from 和 to 创建动画
(2)在 @keyframes 中用 “百分比” 创建动画
(3)将 @keyframes 嵌套进要添加动画的元素的样式里
ii. animation 执行动画
-
transition:表示过渡。transition 可以单独使用
-
transform:表示变形。使用 transform 实现动画时有两种选择:
-
transform + transition:一次性动画。transform 定义行为,transition 驱动,但一次仅能驱动一次。
-
transform + @keyframes + animation:支持循环动画。在 @keyframes 里使用 transform 定义行为,animation 驱动,可充分调整动画的实现,包括:指定动画任意的执行次数,指定动画的结束与开始的状态等等。
.iconfont-loadding {
animation: start_loadding 800ms linear 100ms infinite normal none running;
}
@keyframes start_loadding {
from { transform: rotate(0deg);}
to { transform: rotate(360deg);}
}
transition 和 animation 实现动画的区别:transition:需要触发一个事件才执行动画。animation:自动执行动画,可循环执行。
题目二
如何使用 JS 判断某个字符串长度(要求支持 Emoji 表情)?
官方解析
在 JavaScript 中,可以使用 String 类型的 length 属性来获取字符串的长度。但是,由于 Emoji 表情在字符串中占用了两个字符的位置,因此直接使用 length 属性得到的结果并不准确。
为了正确地获取字符串的长度,可以使用如下的方法:
/**
* 计算字符串的长度(支持 Emoji 表情)
* @param {string} str - 要计算长度的字符串
* @returns {number} - 字符串的长度
*/
function getLength(str) {
let length = 0;
for (let i = 0; i < str.length; i++) {
const code = str.charCodeAt(i);
if (code >= 0xd800 && code <= 0xdbff) {
i++;
}
length++;
}
return length;
}
举个例子,对于字符串 "Hello,🌍!",使用该函数计算出的长度为 8,而使用 length 属性计算出的长度则为 9。
正则表达式替换
利用正则表达式将 emoji 替换成单字符的符号,然后再获取len就是正确的 length了。
replace不会影响原字符串的内容
const str = "H😋";
const len = str.replace(/\uD83C[\uDF00-\uDFFF]|\uD83D[\uDC00-\uDE4F]/g,"-").length;
console.log(len)
输出
2
ES6特性
ES6大幅增强了对字符串的处理能力。借用数组,可以快速判断带有emoji字符的字符串长度。
const str = "A😋";
const arr = Array.from(str);
console.log(str.length,arr.length)
输出:
3 2
局限性
多码点的emoji比如👨👩👧,会显示长度为5,这是因为unicode的约定导致的,详情可看阮一峰的这篇博文 http://www.ruanyifeng.com/blog/2017/04/emoji.html
题目三
Vue Router 路由有哪些模式?各模式有什么区别?
官方解析
Vue Router 路由有三种模式:
-
hash 模式:使用 URL 中的 hash(即 # 后面的内容)来作为路由路径。这种模式下,页面不会重新加载,只会更新 hash 值,并触发路由变化,从而渲染对应的组件。
-
history 模式:使用 HTML5 中新增的 History API 来管理浏览历史记录,从而实现页面的前进和后退。在这种模式下,URL 中不会带有 # 号,而是使用真实的 URL 路径来作为路由路径。
-
abstract 模式:在不需要基于浏览器的 API 时,可以使用这种模式。在这种模式下,路由器并不会监听 URL 变化,而是通过调用 router.replace 或 router.push 来进行导航。区别:
-
hash 模式可以兼容较老的浏览器,但 URL 中会带有 # 号。
-
history 模式无需带有 # 号,更加美观,但需要后端支持,否则刷新页面会导致 404 错误。
-
abstract 模式主要用于一些特定场景,例如在使用 Node.js 时,可以使用 abstract 模式来构建路由。一般来说,如果需要支持较老的浏览器,或者不需要后端支持,可以使用 hash 模式;否则建议使用 history 模式。
Vue Router 路由有三种模式:hash 模式、history 模式和 abstract 模式。
| 区别 | hash模式 | history模式 | abstract模式 |
|---|---|---|---|
| URL 格式 | URL 中带有 #,如:http://example.com/#/home | URL 中没有 #,而是直接使用 path,如:http://example.com/home | 没有真实的 URL,只使用虚拟路径,如:/home |
| 浏览器兼容性 | 兼容性好,支持所有浏览器 | 需要 HTML5 支持,不支持 IE9 及以下版本 | 无浏览器兼容问题 |
| 服务端配置 | 不需要进行额外配置,可以直接在前端中使用 | 需要服务器端进行配置,防止 404 | 不需要服务端配置 |
| SEO | 不利于 SEO,因为搜索引擎不会爬取 URL 中的 # 后面的内容 | 对 SEO 更加友好,因为路径更加规范 | 不利于 SEO |
| 使用场景 | 不需要考虑浏览器兼容性和服务端配置,适用于简单应用场景 | 需要考虑 SEO 和更规范的 URL 地址,适用于较复杂应用场景 | 非浏览器环境下的应用程序或者只需要使用编程式导航的情况 |
一般情况下,我们建议使用 history 模式,因为它对 SEO 更加友好、URL 更加规范,并且随着 HTML5 技术的普及,浏览器兼容性也不再是问题。但是在特定场景下,如需要支持 IE9 及以下浏览器,或者不方便进行服务端配置时,可以选择使用 hash 模式。而 abstract 模式则适用于一些特殊的场景,如非浏览器环境下的应用程序或者只需要使用编程式导航的情况。















 490
490











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









