







散列表是一种众所周知的数据结构,可以快速地查找所需要的对象,在Java中散列表是通过链表数组实现,而每个列表又被称为桶(bucket)。
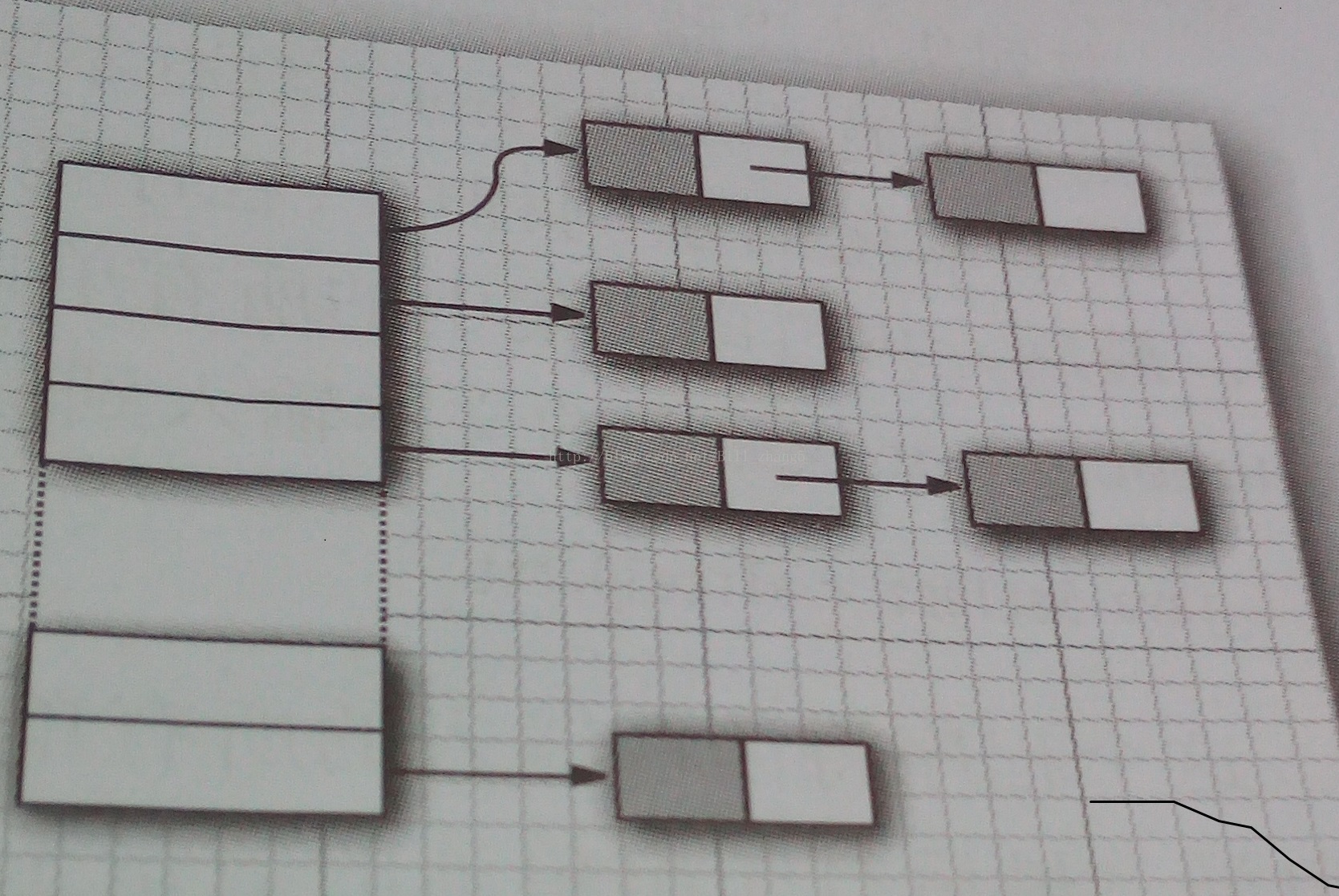
在Java SE8中桶满时就会变为平衡二叉树。,如果选择散列函数不当,会产生很多冲突,影响性能。尽管没有确凿证据,普遍认为装填因子(load factor)为0.75最好.Java集合类库提供了一个HashSet类,用于实现散列集。
主要方法如下:
| 构造方法摘要 | |
|---|---|
HashSet() 构造一个新的空 set,其底层 HashMap 实例的默认初始容量是 16,加载因子是 0.75。 | |
HashSet(Collection<? extends E> c) 构造一个包含指定 collection 中的元素的新 set。 | |
HashSet(int initialCapacity) 构造一个新的空 set,其底层 HashMap 实例具有指定的初始容量和默认的加载因子(0.75)。 | |
HashSet(int initialCapacity, float loadFactor) 构造一个新的空 set,其底层 HashMap 实例具有指定的初始容量和指定的加载因子。 | |
| 方法摘要 | |
|---|---|
boolean | add(E e) 如果此 set 中尚未包含指定元素,则添加指定元素。 |
void | clear() 从此 set 中移除所有元素。 |
Object | clone() 返回此 HashSet 实例的浅表副本:并没有复制这些元素本身。 |
boolean | contains(Object o) 如果此 set 包含指定元素,则返回 true。 |
boolean | isEmpty() 如果此 set 不包含任何元素,则返回 true。 |
Iterator<E> | iterator() 返回对此 set 中元素进行迭代的迭代器。 |
boolean | remove(Object o) 如果指定元素存在于此 set 中,则将其移除。 |
int | size() 返回此 set 中的元素的数量(set 的容量)。 |
以下是一个简单实现:
import java.util.*
public class SetTest
{
public static void main(string[] args)
{
Set<String> words=new HashSet<>();//HashSet实现Set
long totalTime=0;
try(Scanner in=new Scanner(System.in))
{
while(in.hasNext())
{
String word=in.next();
long callTime=System.currentTimeMillis();
words.add(word)
callTime=System.currentTimeMillis()-callTime;
totalTime+=callTime;
}
}
Iterator<String>iter=words.iteratir();
for(int i=1;i<=20;i++)
System。out.println(iter.next());
System.out.println(words.size()+"distinct words."+totalTime+"Millseconds.");
}
}













 252
252











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









