






Code: https://github.com/mzweilin/EvadeML-Zoo
- Feature squeezing: reducing the color bit depth of each pixel and spatial smoothing.
- Framework:
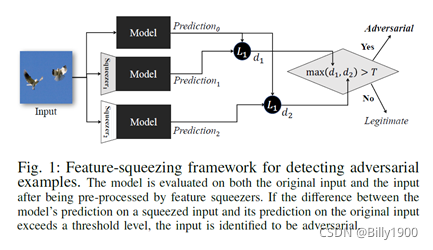
-
Adversarial examples attacks
- L p n o r m L_p norm Lpnorm attack
- FGSM
- BIM
- DeepFool
- JSMA
- Carlini/Wagner attacks
-
Defense:
- Adversarial training
- Gradient masking
- Feature squeezing/input transformation
-
Detecting adversarial examples
- Sample statistics: maximum mean discrepancy
- Training a detector
- Prediction inconsistency: one adversarial example may not fool every DNN model.
-
Color depth

-
Spatial smoothing
- Local smoothing

- Non-local smoothing

- Local smoothing
-
这篇paper大篇幅都在survey adversarial attack and defense, 提出的方案很简单,并不effective
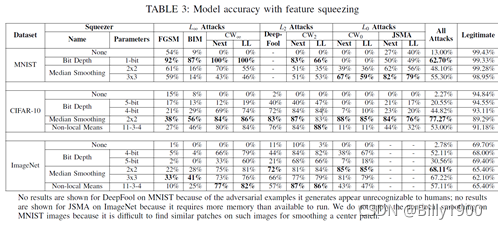
More Update:https://github.com/Billy1900/Backdoor-Learning















 2229
2229











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









