







Spark Streaming_第七章笔记
1.流计算概述
1.1流数据特点:
数据快速持续到达,潜在大小也许是无穷无尽的
数据来源众多,格式复杂
数据量大,但是不十分关注存储,一旦经过处理,要么被丢弃,要么被归档存储
注重数据的整体价值,不过分关注个别数据
数据顺序颠倒,或者不完整,系统无法控制将要处理的新到达的数据元素的顺序
1.2流计算
流计算秉承一个基本理念,即数据的价值随着时间的流逝而降低,如用户点击流。
因此,当事件出现时就应该立即进行处理,而不是缓存起来进行批量处理。为了及时处理流数据,就需要一个低延迟、可扩展、高可靠的处理引擎
1.2.1流数据:
实时获取来自不同数据源的海量数据,经过实时分析处理,获得有价值的信息
批量计算:充裕时间处理静态数据,如Hadoop
流数据不适合采用批量计算,因为流数据不适合用传统的关系模型建模
流数据必须采用实时计算,响应时间为秒级
数据量少时,不是问题,但是,在大数据时代,数据格式复杂、来源众多、数据量巨大,对实时计算提出了很大的挑战。因此,针对流数据的实时计算——流计算,应运而生
1.2.2流计算的要求:
高性能:处理大数据的基本要求,如每秒处理几十万条数据
海量式:支持TB级甚至是PB级的数据规模
实时性:保证较低的延迟时间,达到秒级别,甚至是毫秒级别
分布式:支持大数据的基本架构,必须能够平滑扩展
易用性:能够快速进行开发和部署
可靠性:能可靠地处理流数据
1.3流计算处理流程:
传统的数据处理流程隐含了两个前提:
1.存储的数据是旧的。存储的静态数据是过去某一时刻的快照,这些数据在查询时可能已不具备时效性了
2.需要用户主动发出查询来获取结果

流计算的处理流程一般包含三个阶段:数据实时采集、数据实时计算、实时查询服务
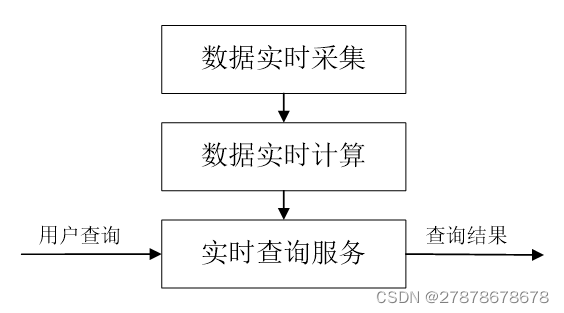
1数据实时采集:
数据实时采集阶段通常采集多个数据源的海量数据,需要保证实时性、低延迟与稳定可靠
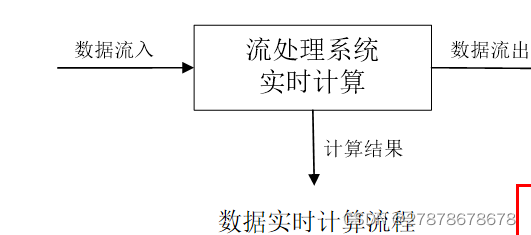
2数据实时计算:
数据实时计算阶段对采集的数据进行实时的分析和计算,并反馈实时结果。经流处理系统处理后的数据,可视情况进行存储,以便之后再进行分析计算。在时效性要求较高的场景中,处理之后的数据也可以直接丢弃。
3实时查询服务:经由流计算框架得出的结果可供用户进行实时查询、展示或储存
传统的数据处理流程,用户需要主动发出查询才能获得想要的结果。而在流处理流程中,实时查询服务可以不断更新结果,并将用户所需的结果实时推送给用户
虽然通过对传统的数据处理系统进行定时查询,也可以实现不断地更新结果和结果推送,但通过这样的方式获取的结果,仍然是根据过去某一时刻的数据得到的结果,与实时结果有着本质的区别
2.Spark Streaming
3.DStream操作概述
编写Spark Streaming程序的基本步骤是:
1.通过创建输入DStream来定义输入源
2.通过对DStream应用转换操作和输出操作来定义流计算
3.用streamingContext.start()来开始接收数据和处理流程
4.通过streamingContext.awaitTermination()方法来等待处理结束(手动结束或因为错误而结束)
5.可以通过streamingContext.stop()来手动结束流计算进程
3.1创建StreamingContext对象
登录Linux系统后,启动spark-shell。进入spark-shell以后,就已经获得了一个默认的SparkConext,也就是sc。因此,可以采用如下方式来创建StreamingContext对象
scala> import org.apache.spark.streaming._
scala> val ssc = new StreamingContext(sc, Seconds(1))
如果是编写一个独立的Spark Streaming程序,而不是在spark-shell中运行,则需要通过如下方式创建StreamingContext对象
import org.apache.spark._
import org.apache.spark.streaming._
val conf = new SparkConf().setAppName("TestDStream").setMaster("local[2]")
val ssc = new StreamingContext(conf, Seconds(1))
4基本输入源
进入spark-shell创建文件流
4.1文件流
4.1.1.在spark-shell中创建文件流
scala> import org.apache.spark.streaming._
scala> val ssc = new StreamingContext(sc, Seconds(20))
scala> val lines = ssc.textFileStream("file:///usr/local/spark/mycode/streaming/logfile")
scala> val words = lines.flatMap(_.split(" "))
scala> val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
scala> wordCounts.print()
scala> ssc.start()
scala> ssc.awaitTermination()
4.1.2采用独立应用程序方式创建文件流
import org.apache.spark._
import org.apache.spark.streaming._
object WordCountStreaming {
def main(args: Array[String]) {
val sparkConf = new SparkConf().setAppName("WordCountStreaming").setMaster("local[2]")//设置为本地运行模式,2个线程,一个监听,另一个处理数据
val ssc = new StreamingContext(sparkConf, Seconds(2))// 时间间隔为2秒
val lines = ssc.textFileStream("file:///usr/local/spark/mycode/streaming/logfile") //这里采用本地文件,当然你也可以采用HDFS文件
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
4.2套接字流
2.使用套接字流作为数据源
object NetworkWordCount {
def main(args: Array[String]) {
if (args.length < 2) {
System.err.println("Usage: NetworkWordCount <hostname> <port>")
System.exit(1)
}
StreamingExamples.setStreamingLogLevels()
val sparkConf = new SparkConf().setAppName("NetworkWordCount").setMaster("local[2]")
val ssc = new StreamingContext(sparkConf, Seconds(1))
val lines = ssc.socketTextStream(args(0), args(1).toInt, StorageLevel.MEMORY_AND_DISK_SER)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
- 使用Socket编程实现自定义数据源
4.3RDD队列流
每隔1秒创建一个RDD,Streaming每隔2秒就对数据进行处理
package org.apache.spark.examples.streaming
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.StreamingContext._
import org.apache.spark.streaming.{Seconds, StreamingContext}
object QueueStream {
def main(args: Array[String]) {
val sparkConf = new SparkConf().setAppName("TestRDDQueue").setMaster("local[2]")
val ssc = new StreamingContext(sparkConf, Seconds(2))
val rddQueue =new scala.collection.mutable.SynchronizedQueue[RDD[Int]]()
val queueStream = ssc.queueStream(rddQueue)
val mappedStream = queueStream.map(r => (r % 10, 1))
val reducedStream = mappedStream.reduceByKey(_ + _)
reducedStream.print()
ssc.start()
for (i <- 1 to 10){
rddQueue += ssc.sparkContext.makeRDD(1 to 100,2)
Thread.sleep(1000)
}
ssc.stop()
}
}
5高级数据源
Kafka是一种高吞吐量的分布式发布订阅消息系统,用户通过Kafka系统可以发布大量的消息,同时也能实时订阅消费消息
Kafka可以同时满足在线实时处理和批量离线处理
5.1编写Spark Streaming程序使用Kafka数据源
5.1.1编写生产者(producer)程序
package org.apache.spark.examples.streaming
import java.util.HashMap
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka._
object KafkaWordProducer {
def main(args: Array[String]) {
if (args.length < 4) {
System.err.println("Usage: KafkaWordCountProducer <metadataBrokerList> <topic> " +
"<messagesPerSec> <wordsPerMessage>")
System.exit(1)
}
val Array(brokers, topic, messagesPerSec, wordsPerMessage) = args
// Zookeeper connection properties
val props = new HashMap[String, Object]()
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers)
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer")
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer")
val producer = new KafkaProducer[String, String](props)
// Send some messages
while(true) {
(1 to messagesPerSec.toInt).foreach { messageNum =>
val str = (1 to wordsPerMessage.toInt).map(x => scala.util.Random.nextInt(10).toString)
.mkString(" ")
print(str)
println()
val message = new ProducerRecord[String, String](topic, null, str)
producer.send(message)
}
Thread.sleep(1000)
}
}
}
5.1.2.编写消费者(consumer)程序
package org.apache.spark.examples.streaming
import org.apache.spark._
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka._
import org.apache.spark.streaming.StreamingContext._
import org.apache.spark.streaming.kafka.KafkaUtils
object KafkaWordCount{
def main(args:Array[String]){
StreamingExamples.setStreamingLogLevels()
val sc = new SparkConf().setAppName("KafkaWordCount").setMaster("local[2]")
val ssc = new StreamingContext(sc,Seconds(10))
ssc.checkpoint("file:///usr/local/spark/mycode/kafka/checkpoint") //设置检查点,如果存放在HDFS上面,则写成类似ssc.checkpoint("/user/hadoop/checkpoint")这种形式,但是,要启动hadoop
val zkQuorum = "localhost:2181" //Zookeeper服务器地址
val group = "1" //topic所在的group,可以设置为自己想要的名称,比如不用1,而是val group = "test-consumer-group“
val topics = "wordsender" //topics的名称
val numThreads = 1 //每个topic的分区数
val topicMap =topics.split(",").map((_,numThreads.toInt)).toMap
val lineMap = KafkaUtils.createStream(ssc,zkQuorum,group,topicMap)
val lines = lineMap.map(_._2)
val words = lines.flatMap(_.split(" "))
val pair = words.map(x => (x,1))
val wordCounts = pair.reduceByKeyAndWindow(_ + _,_ - _,Minutes(2),Seconds(10),2) //这行代码的含义在下一节的窗口转换操作中会有介绍
wordCounts.print
ssc.start
ssc.awaitTermination
}
}
5.1.3.编写日志格式设置程序
package org.apache.spark.examples.streaming
import org.apache.spark.Logging
import org.apache.log4j.{Level, Logger}
/** Utility functions for Spark Streaming examples. */
object StreamingExamples extends Logging {
/** Set reasonable logging levels for streaming if the user has not configured log4j. */
def setStreamingLogLevels() {
val log4jInitialized = Logger.getRootLogger.getAllAppenders.hasMoreElements
if (!log4jInitialized) {
// We first log something to initialize Spark's default logging, then we override the
// logging level.
logInfo("Setting log level to [WARN] for streaming example." +
" To override add a custom log4j.properties to the classpath.")
Logger.getRootLogger.setLevel(Level.WARN)
}
}
}
5.1.4.编译打包程序
5.1.5.运行程序
6转换操作
6.1 DStream无状态转换操作
之前“套接字流”部分介绍的词频统计,就是采用无状态转换,每次统计,都是只统计当前批次到达的单词的词频,和之前批次无关,不会进行累计
map(func) :对源DStream的每个元素,采用func函数进行转换,得到一个新的Dstream
flatMap(func): 与map相似,但是每个输入项可用被映射为0个或者多个输出项
filter(func): 返回一个新的DStream,仅包含源DStream中满足函数func的项
repartition(numPartitions): 通过创建更多或者更少的分区改变DStream的并行程度
reduce(func):利用函数func聚集源DStream中每个RDD的元素,返回一个包含单元素RDDs的新DStream
count():统计源DStream中每个RDD的元素数量
union(otherStream): 返回一个新的DStream,包含源DStream和其他DStream的元素
countByValue():应用于元素类型为K的DStream上,返回一个(K,V)键值对类型的新DStream,每个键的值是在原DStream的每个RDD中的出现次数
reduceByKey(func, [numTasks]):当在一个由(K,V)键值对组成的DStream上执行该操作时,返回一个新的由(K,V)键值对组成的DStream,每一个key的值均由给定的recuce函数(func)聚集起来
join(otherStream, [numTasks]):当应用于两个DStream(一个包含(K,V)键值对,一个包含(K,W)键值对),返回一个包含(K, (V, W))键值对的新Dstream
cogroup(otherStream, [numTasks]):当应用于两个DStream(一个包含(K,V)键值对,一个包含(K,W)键值对),返回一个包含(K, Seq[V], Seq[W])的元组
transform(func):通过对源DStream的每个RDD应用RDD-to-RDD函数,创建一个新的DStream。支持在新的DStream中做任何RDD操作
// An highlighted block
var foo = 'bar';
6.2 DStream有状态转换操作
6.2.1滑动窗口转换操作
事先设定一个滑动窗口的长度(也就是窗口的持续时间)
设定滑动窗口的时间间隔(每隔多长时间执行一次计算),让窗口按照指定时间间隔在源DStream上滑动
每次窗口停放的位置上,都会有一部分Dstream(或者一部分RDD)被框入窗口内,形成一个小段的Dstream
可以启动对这个小段DStream的计算
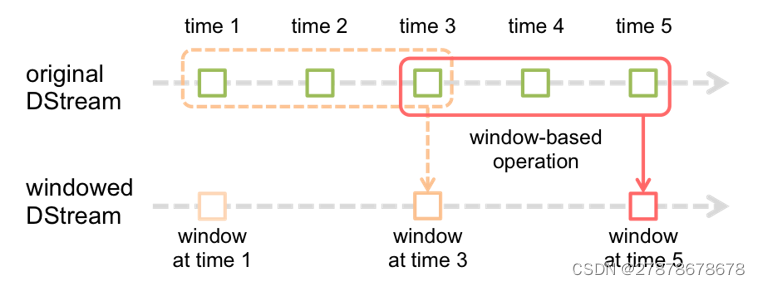
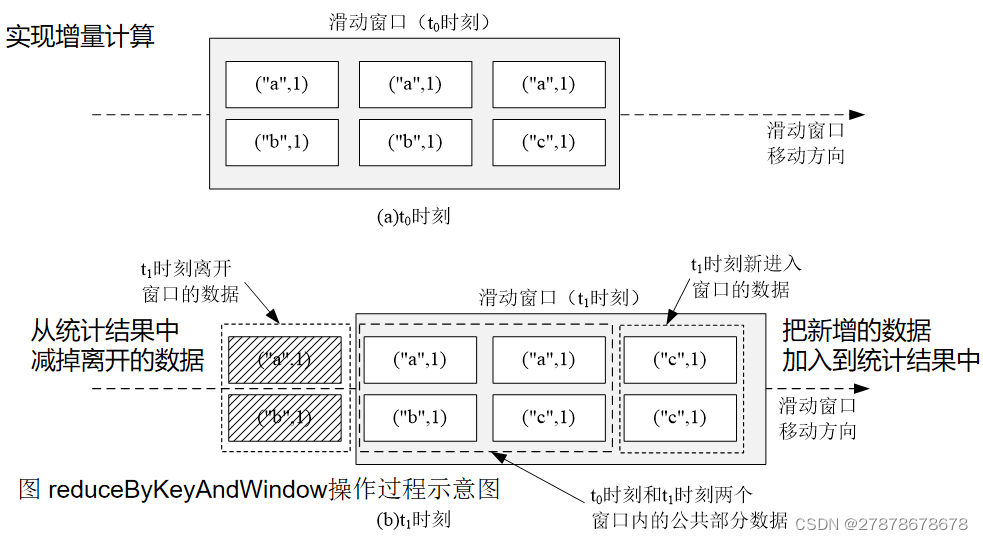
val wordCounts = pair.reduceByKeyAndWindow( _ + _, _ - _, Minutes(2), Seconds(10), 2)
//reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks])
6.2.2updateStateByKey操作
需要在跨批次之间维护状态时,就必须使用updateStateByKey操作
对于有状态转换操作而言,本批次的词频统计,会在之前批次的词频统计结果的基础上进行不断累加,所以,最终统计得到的词频,是所有批次的单词的总的词频统计结果
package org.apache.spark.examples.streaming
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.storage.StorageLevel
object NetworkWordCountStateful {
def main(args: Array[String]) {
//定义状态更新函数
val updateFunc = (values: Seq[Int], state: Option[Int]) => {
val currentCount = values.foldLeft(0)(_ + _)
val previousCount = state.getOrElse(0)
Some(currentCount + previousCount)
}
StreamingExamples.setStreamingLogLevels() //设置log4j日志级别
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCountStateful")
val sc = new StreamingContext(conf, Seconds(5))
sc.checkpoint("file:///usr/local/spark/mycode/streaming/stateful/") //设置检查点,检查点具有容错机制
val lines = sc.socketTextStream("localhost", 9999)
val words = lines.flatMap(_.split(" "))
val wordDstream = words.map(x => (x, 1))
val stateDstream = wordDstream.updateStateByKey[Int](updateFunc)
stateDstream.print()
sc.start()
sc.awaitTermination()
}
}
7输出操作
7.1 把DStream输出到文本文件中
package org.apache.spark.examples.streaming
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.storage.StorageLevel
object NetworkWordCountStateful {
def main(args: Array[String]) {
//定义状态更新函数
val updateFunc = (values: Seq[Int], state: Option[Int]) => {
val currentCount = values.foldLeft(0)(_ + _)
val previousCount = state.getOrElse(0)
Some(currentCount + previousCount)
}
StreamingExamples.setStreamingLogLevels() //设置log4j日志级别
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCountStateful")
val sc = new StreamingContext(conf, Seconds(5))
sc.checkpoint("file:///usr/local/spark/mycode/streaming/dstreamoutput/") //设置检查点,检查点具有容错机制
val lines = sc.socketTextStream("localhost", 9999)
val words = lines.flatMap(_.split(" "))
val wordDstream = words.map(x => (x, 1))
val stateDstream = wordDstream.updateStateByKey[Int](updateFunc)
stateDstream.print()
//下面是新增的语句,把DStream保存到文本文件中 stateDstream.saveAsTextFiles("file:///usr/local/spark/mycode/streaming/dstreamoutput/output.txt")
sc.start()
sc.awaitTermination()
}
}
7.2 把DStream写入到MySQL数据库中
package org.apache.spark.examples.streaming
import java.sql.{PreparedStatement, Connection, DriverManager}
import java.util.concurrent.atomic.AtomicInteger
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.StreamingContext._
import org.apache.spark.storage.StorageLevel
object NetworkWordCountStateful {
def main(args: Array[String]) {
//定义状态更新函数
val updateFunc = (values: Seq[Int], state: Option[Int]) => {
val currentCount = values.foldLeft(0)(_ + _)
val previousCount = state.getOrElse(0)
Some(currentCount + previousCount)
}
StreamingExamples.setStreamingLogLevels() //设置log4j日志级别
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCountStateful")
val sc = new StreamingContext(conf, Seconds(5))
sc.checkpoint("file:///usr/local/spark/mycode/streaming/dstreamoutput/") //设置检查点,检查点具有容错机制
val lines = sc.socketTextStream("localhost", 9999)
val words = lines.flatMap(_.split(" "))
val wordDstream = words.map(x => (x, 1))
val stateDstream = wordDstream.updateStateByKey[Int](updateFunc)
stateDstream.print()
//下面是新增的语句,把DStream保存到MySQL数据库中
stateDstream.foreachRDD(rdd => {
//内部函数
def func(records: Iterator[(String,Int)]) {
var conn: Connection = null
var stmt: PreparedStatement = null
try {
val url = "jdbc:mysql://localhost:3306/spark"
val user = "root"
val password = "hadoop" //数据库密码是hadoop
conn = DriverManager.getConnection(url, user, password)
records.foreach(p => {
val sql = "insert into wordcount(word,count) values (?,?)"
stmt = conn.prepareStatement(sql);
stmt.setString(1, p._1.trim)
stmt.setInt(2,p._2.toInt)
stmt.executeUpdate()
})
} catch {
case e: Exception => e.printStackTrace()
} finally {
if (stmt != null) {
stmt.close()
}
if (conn != null) {
conn.close()
}
}
}
val repartitionedRDD = rdd.repartition(3)
repartitionedRDD.foreachPartition(func)
})
sc.start()
sc.awaitTermination()
}
}
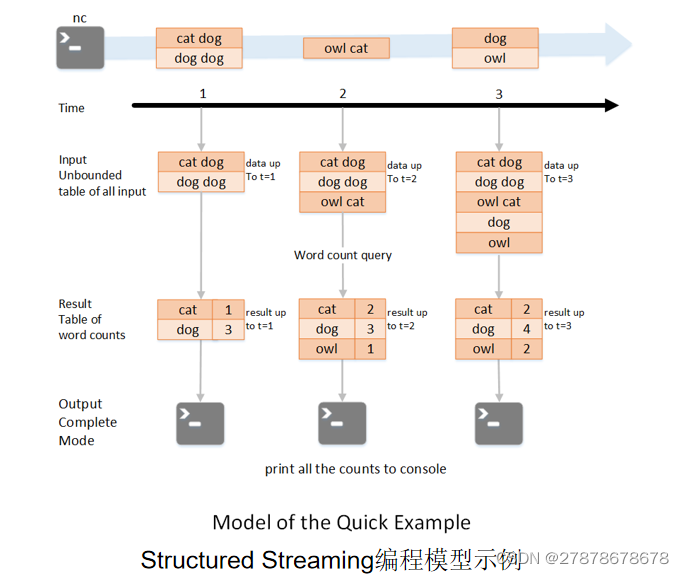
8Structured Streaming
把不断输入的流式数据加载为内存中一张没有边界的数据库表,每一条新来的数据都会作为一行数据新增到这张表中
每一条查询的操作都会产生一个结果集-Result Table。每一个触发间隔(比如说1秒),当新的数据新增到表中,都会最终更新Result Table















 2215
2215











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









