









京东商城有货提醒,补货监控。
运行环境:Windows
支持多种推送方式
功能:支持有货直接打开BP链接直接提交,有货声音提示,有货推送
库存监控目的就是为了,让我们第一时间知道自己关注的商品库存状态,从无货到有货,第一时间买到自己想要的,同时又不能整天蹲着浪费时间。
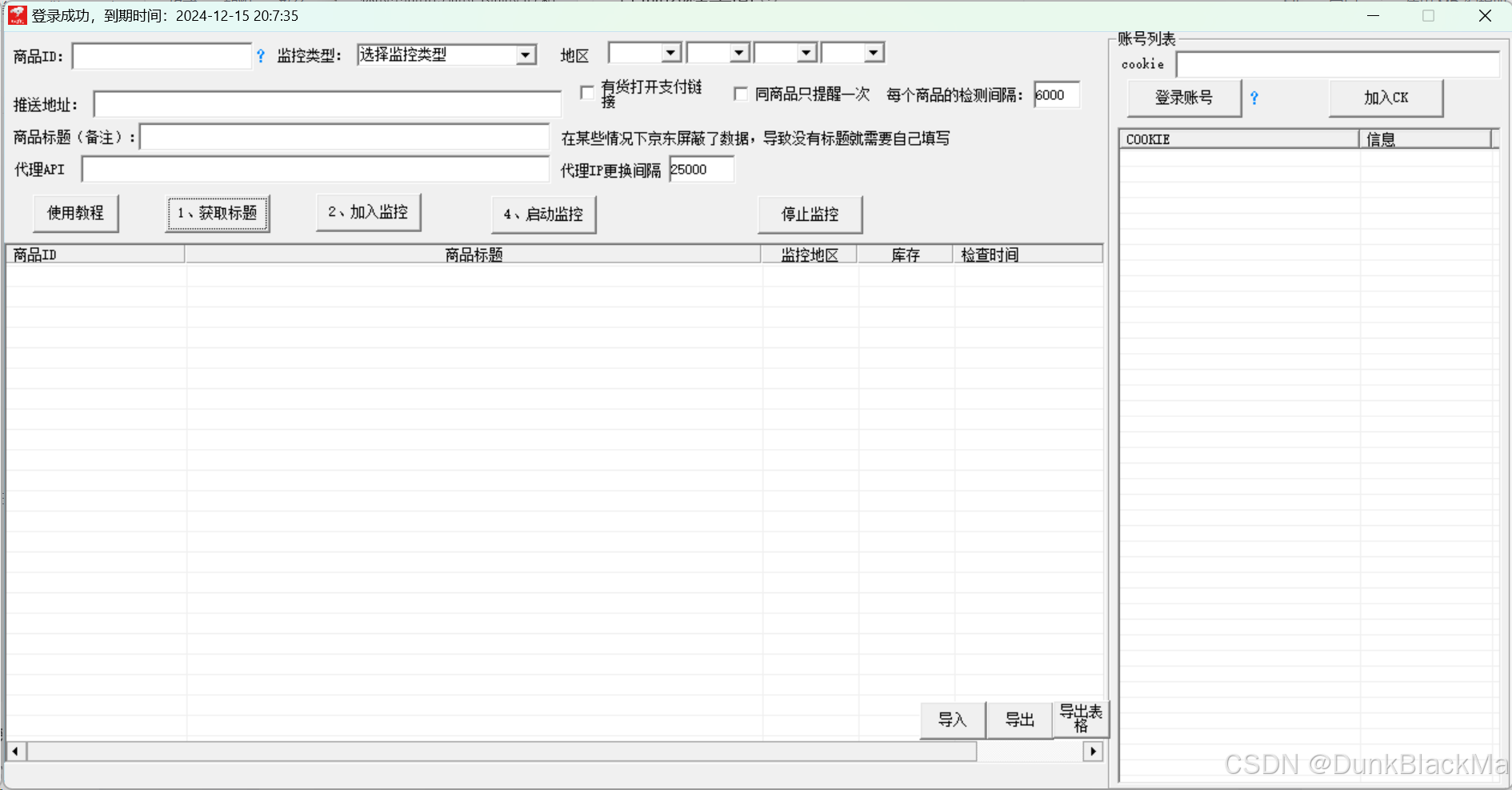
下面是京东库存监控软件的使用教程
打开之后输入商品链接或者直接输入商品ID,选着需要监控的地区,软件自动读取标题,然后加入监控,设置好一些参数或者默认直接启动即可
电脑上操作一次就不用在电脑边守着,企业vx的推送方式也带有直接BP链接,也不用在重复了,软件自带使用教程,直接点击登陆即可
泡泡 dunkblackma

















 4481
4481

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









