






亮点的前言:
在数字浪潮中,图像生成技术一直是创意与科技的前沿阵地。然而,传统模型的局限性如同枷锁,束缚着创新的步伐。如今,字节跳动带着 UNO FLUX 版强势来袭,以单模型架构打破常规,实现多图个性化生成的突破。更令人振奋的是,字节跳动将训练、推理代码及模型权重全盘公开,这不仅是一次开源,更是一场技术的盛宴,为全球开发者和研究人员提供了无限可能,开启了图像生成的新纪元。
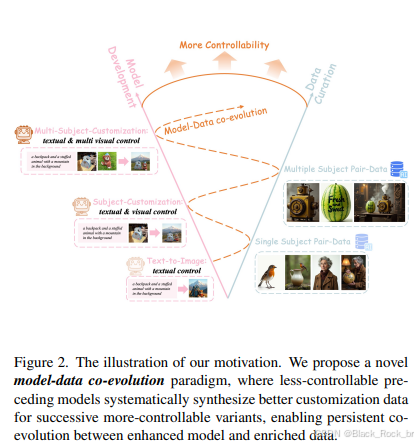
提出了一种模型与数据协同进化的创新范式,成功突破了传统定制化图像生成中数据资源受限的瓶颈。
设计了渐进式数据生成框架,并开发了通用定制化模型UNO,能够实现从单主体到多主体的高质量图像生成。
在多项任务中表现出卓越性能,涵盖单主体和多主体驱动的图像生成场景,同时具备强大的泛化能力,可广泛应用于身份定制(ID)、虚拟试穿(Try-On)、风格迁移(Style)等多样化任务。

1:解决的问题
数据瓶颈:
获取高质量、多视角且主体一致的配对数据存在较大难度,这一问题严重制约了模型的扩展能力。
主体扩展性:
当前方法多聚焦于单主体生成任务,在面对复杂多样、包含丰富种类的多主体场景时往往表现有限,难以有效应对。
2:提出的方案
-
数据生成与模型训练流程
-
首先,利用 Text - to - Image(T2I)模型生成单主体定制化数据;然后,基于这些数据训练 Subject - to - Image(S2I)模型,使其能够生成质量高、种类丰富的多主体数据。这一流程体现了从单主体数据生成到多主体模型训练的逐步推进,通过协同进化范式提升整个图像生成系统的性能。
-
-
模型架构与框架开发流程
-
开发渐进式数据生成框架,为数据的逐步生成和优化提供支持;在此基础上,构建通用定制化模型 UNO,实现从单主体到多主体图像生成的平滑过渡。这一流程展示了从底层数据生成框架到通用模型架构的开发过程,体现了技术的系统性和层次性。
-
3:应用的技术
1. 核心改进:模型能力扩展
- 从T2I到S2I的升级
基于当前最先进的文本到图像(T2I)模型FLUX,通过技术改进使其支持多条件生成,拓展为图像到图像(S2I)模型,从而满足更复杂的生成需求。
---
2. 关键技术创新
- 渐进式跨模态对齐
引入逐步训练策略,实现对多图像条件的高效处理,确保不同模态之间的精准对齐。
- 通用旋转位置嵌入(UnoPE)
提出一种创新的旋转位置嵌入机制,有效解决多图像条件下的属性混淆问题,提升生成结果的一致性和准确性。
---
3. 技术价值与意义
- 多条件生成的支持
新模型不仅能够处理单一条件输入,还能灵活应对多图像、多条件的生成任务,显著提升了模型的适用范围和复杂场景处理能力。
- 属性一致性保障
通过UnoPE等技术手段,解决了多主体生成中常见的属性混淆问题,确保生成图像在细节上保持高度一致。
4:达到的效果
在 DreamBench 和多主体生成基准测试中,UNO 模型凭借出色的一致性和文本可控性,取得了最佳性能。它显著减少了生成图像中的“复制 - 粘贴”现象,从而大幅提升了图像生成的质量和可控性。此外,UNO 模型还展现出极佳的泛化能力,能够广泛应用于换装、人物保持、风格化等多种个性化生成任务。
-
基准测试性能
-
在 DreamBench 和多主体生成基准测试中,UNO 模型的一致性和文本可控性表现卓越,取得了最佳性能,这表明其在图像生成的准确性和对文本描述的遵循程度上达到了较高水平。
-
-
生成质量提升
-
显著减少了“复制 - 粘贴”现象,有效提高了生成图像的质量和可控性,使得生成的图像更加自然、真实且符合用户需求。
-
-
5:方法
上下文数据生成框架
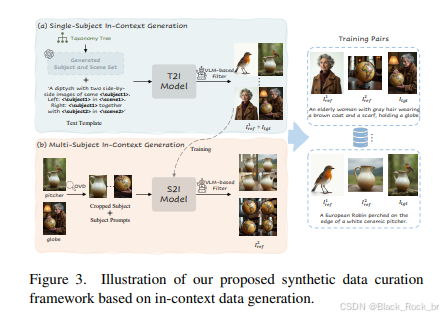
渐进式训练策略
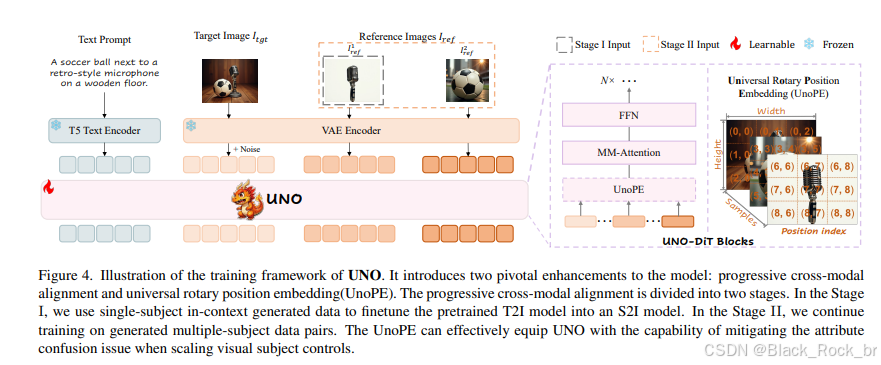
DiT模型最初是为纯文本到图像(T2I)任务设计的,其输入主要由文本提示和噪声图像的嵌入组成。然而,当尝试引入多图像条件(例如参考图像)时,直接将多图像作为输入可能会导致模型训练不稳定或性能下降。这是由于多图像条件的加入会改变模型的收敛分布,使得模型难以适应复杂的多模态输入。为了解决这一问题,论文提出了一种渐进式跨模态对齐的训练方法,并将其分为两个阶段进行优化:
单主题训练阶段(Stage I)
目标 :
使模型掌握处理单图像条件输入的能力,能够生成与参考图像高度一致的结果。
方法 :
采用单主体数据对预训练的 T2I 模型进行微调。在这一过程中,输入内容涵盖文本提示、噪声图像嵌入以及单一参考图像嵌入。
效果 :
经过此阶段训练,模型学会了如何将参考图像的信息有效融入到图像生成环节,从而能够精准地生成与参考图像相匹配的单主体图像。
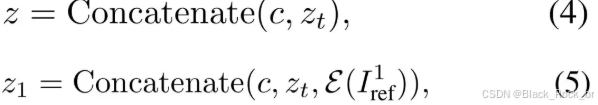
多主题训练阶段(Stage II)
- 目标:使模型具备处理多图像条件输入的能力,生成与多个参考图像一致的高质量结果。
- 方法:在单主题训练的基础上,引入多主体数据对进行进一步训练。输入内容包括文本提示、噪声图像嵌入以及多个参考图像的嵌入信息。
- 效果:经过该阶段的训练,模型能够有效处理包含多个参考图像的复杂输入,并生成与所有参考图像特征一致的多主题图像。
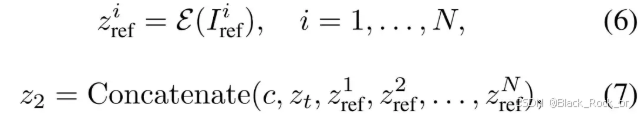
论文通过从简单到复杂的训练范式,让模型能够逐步适应多图像条件的输入,避免直接引入多图像条件导致的训练不稳定。
通用旋转位置嵌入(UnoPE)
在处理多图像条件时,DiT需要整合多个参考图像的嵌入信息。然而,直接采用原始的位置索引可能会引发以下两个问题:首先,模型可能对参考图像的空间结构(例如物体的位置和布局)产生过度依赖,而忽视文本提示中所蕴含的语义信息;其次,不同参考图像之间可能存在语义差异,这可能导致模型在生成目标图像时出现属性混淆的情况。
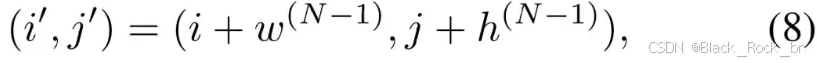
论文提出了一种通用旋转位置嵌入(UnoPE)方法,通过动态调整位置索引,引导模型更加聚焦于文本特征的学习,而非单纯复制参考图像的空间结构。这种方法有效提升了模型对文本条件的理解能力,同时避免了生成过程中对参考图像结构的过度依赖。
实验结果
实验设置
数据生成 :借助渐进式数据生成框架,成功生成了 230k 组单主体数据对以及 15k 组多主体数据对,为模型训练提供了丰富的数据资源。
训练细节 :以 FLUX.1 预训练模型为基础,采用 LoRA 秩为 512 的训练策略,设置总批次为 16,学习率定为 1e-5,确保模型在训练过程中能够高效且稳定地学习到关键特征。
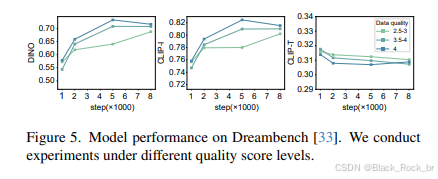
评估指标:选用 DINO 和 CLIP-I 分数来衡量主体一致性,利用 CLIP-T 分数评估文本遵循度,从多个维度全面评估模型的性能表现。

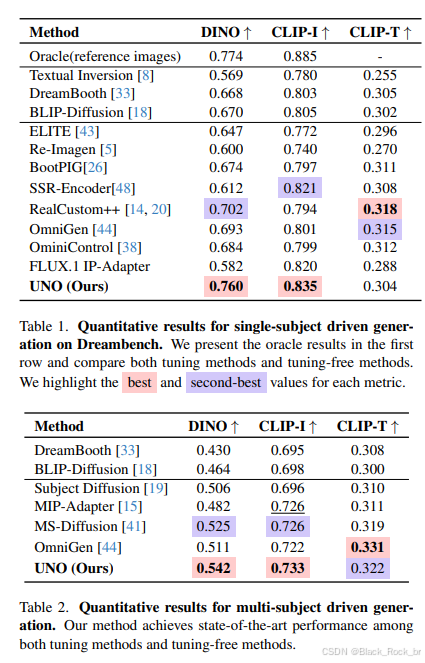
定量指标表现:UNO在DreamBench数据集上树立新标杆
在DreamBench数据集的评估中,UNO模型展现了卓越的性能。在单主题生成任务中,UNO以高达0.760的DINO分数和0.835的CLIP-I分数位居榜首,充分体现了其在细节保留和语义一致性上的优势。而在多主题生成任务中,UNO同样表现出色,取得了0.542的DINO分数和0.733的CLIP-I分数,进一步巩固了其作为当前一致性生成领域最先进(SOTA)方法的地位。这些定量结果验证了UNO在复杂场景下的强大适应能力和生成质量。
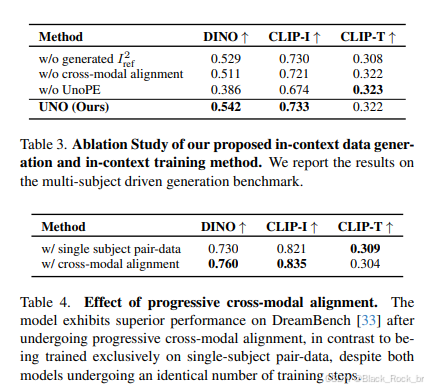
消融实验 :论文通过一系列消融实验,深入探究了渐进式跨模态对齐和 UnoPE 等关键模块对模型性能的影响。实验结果表明,与其它变体相比,这些模块在提升模型性能方面发挥了至关重要的作用。当移除这些模块后,模型的性能出现了显著的下降,进一步凸显了它们在维持模型高效运作和卓越表现中的核心地位。

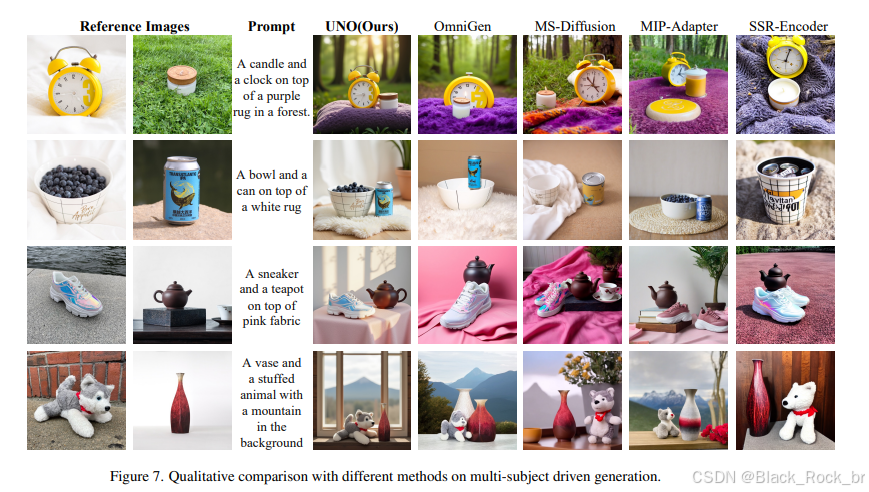
应用案例



结论
本文提出的UNO模型通过引入模型-数据协同进化范式,成功突破了传统定制化图像生成中的数据瓶颈,实现了高质量的单主体与多主体图像生成。实验结果表明,UNO在主题一致性与文本可控性方面均达到了行业领先水平,展现出广泛的应用前景,如虚拟试穿、身份保持以及风格化生成等任务。未来的研究将进一步探索合成数据类型的多样化,以充分挖掘UNO的潜力,为更多应用场景赋能。
arXiv链接:https://arxiv.org/pdf/2504.02160
项目网页:https://bytedance.github.io/UNO/


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









