







引言
在深度学习领域,大型语言模型(LLMs)因其强大的自然语言处理能力而备受关注。然而,这些模型的推理效率往往受限于计算资源。NVIDIA的TensorRT-LLM库提供了一种解决方案,通过优化LLMs在NVIDIA GPU上的推理性能,使得这些模型能够更快地响应。
本文将详细介绍如何自定义和实现TensorRT-LLM模型的过程,NVIDIA的资深工程师讲解具体实现自定义的课程。

A:大语言的模型范式------数据流与自定义模型的责权范围定义。
B:TensorRT-LLMde 基本框架:
我们来实现最简单的自定义模型:
-
创建自定义模型目录:
- 在TensorRT-LLM的
tensorrt_llm/models目录下新建一个目录,比如命名为yuxin,用于存放自定义模型的代码。
- 在TensorRT-LLM的
-
定义模型类:
- 在新建的目录中创建一个
model.py文件,定义自定义模型的类。图片中展示了一个名为YuxinConfig的配置类和一个名为YuxinTransformer的模型类。
- 在新建的目录中创建一个
-
在
__init__.py中注册模型:- 在
tensorrt_llm/models/__init__.py文件中导入自定义模型,并在MODEL_MAP中注册该模型,以便TensorRT-LLM能够识别并使用它。
- 在
-
创建配置文件:
- 在任意位置创建一个
config.json文件,定义模型的配置参数,如架构名称、层数、隐藏层大小、词汇表大小等。
- 在任意位置创建一个
-
构建模型引擎:
- 使用命令行工具
trtllm-build,根据config.json文件构建TensorRT引擎。命令行示例如下:trtllm-build \ --model_config yuxin-test/config.json \ --output_dir engine_yuxin \ --kv_cache_type disabled
这一步会根据配置文件构建并优化模型,生成TensorRT引擎。
- 使用命令行工具
-
运行模型:
- 使用Python脚本
examples/run.py运行模型,并通过命令行参数指定分词器目录、引擎文件、输入文本等。图片中展示了一个运行模型的命令行示例:python3 examples/run.py \ --tokenizer_dir /models/llama-7b-hf/ \ --engine_dir engine_yuxin \ --input_text "my name is" \ --max_output_len 10
这个命令会加载模型引擎并进行推理,输出结果。
- 使用Python脚本
-
使用Llama的分词器:
- 图片中提到,尽管这是一个自定义模型,但仍然可以借用Llama模型的分词器(tokenizer)来处理输入文本。
总结来说,这张图片提供了一个使用TensorRT-LLM创建和运行自定义模型的步骤指南,包括创建模型类、注册模型、定义配置文件、构建引擎、运行模型等关键步骤。
C:TensorRT-LLM的基本框架
Checkpoint规范
-
模型初始化:
- 在模型的
__init__()方法中,可以通过读取文件来初始化模型的权重,而不是每次随机初始化。
- 在模型的
-
统一规范:
- 遵守统一的规范可以让TensorRT-LLM框架自动完成权重加载的工作,简化代码。
-
模型信息存储:
- 模型的配置信息和权重应该存放在特定的目录中。
config.json文件用于存放超参数等配置信息,而rank(i).safetensors文件用于存放每个GPU的权重。
- 模型的配置信息和权重应该存放在特定的目录中。
-
使用trtllm-build命令:
- 在使用
trtllm-build命令构建模型时,只需指定checkpoint目录,TensorRT-LLM将自动加载和解析其中的文件
- 在使用
-
查看safetensors文件:
- 编写一个
dump.py脚本,用于查看safetensors文件中包含的tensors。
- 编写一个
-
执行dump.py:
- 使用命令
python dump.py model-00001-of-00002.safetensors来查看指定的safetensors文件。
- 使用命令
-
输出结果:
- 输出显示了文件中包含的tensors,包括它们的名称、数据类型和形状。例如,
model.Layers.θ.Input_Layernorm.weight是一个torch.float16类型的tensor,形状为torch.Size([4096])。
- 输出显示了文件中包含的tensors,包括它们的名称、数据类型和形状。例如,
-
safetensors文件结构:
safetensors文件中的tensor名称遵循层级结构,类似于文件路径,这使得它们在面向对象编程中易于嵌套和访问。
代码片段
dump.py脚本的代码片段展示了如何使用safetensors库来打开和读取safetensors文件中的tensors。
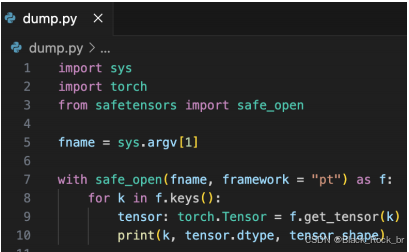
如何使用safetensors文件来管理和查看模型权重。通过遵守这些规范,可以简化模型的构建和部署过程。同时,dump.py脚本提供了一个实用工具,用于检查和验证safetensors文件中的内容。
D:Tensor自动加载原理
-
变量名称一致性:
- 在C++编译后的代码中,变量只有地址没有名称,而在Python中,变量即使在运行时也可以用名称访问。为了实现Tensor自动加载,
safetensors文件中的tensor名称需要与Python代码中的变量名称以及层级关系保持一致。
- 在C++编译后的代码中,变量只有地址没有名称,而在Python中,变量即使在运行时也可以用名称访问。为了实现Tensor自动加载,
-
自动加载实现:
- 自动加载的相关实现位于
PretrainedModel类的load()方法中。这个方法会搜索当前对象以及递归搜索其子孙对象中的所有Parameter对象,并从safetensors文件中找到对应名称的tensor,然后为其赋值。
- 自动加载的相关实现位于
生成safetensors文件
-
生成随机权重:
- 通过
gen_rand_weights.py脚本生成一个包含随机权重的safetensors文件。这个文件被TensorRT-LLM识别,但里面并没有模型需要的权重。
- 通过
-
执行构建命令:
- 使用
trtllm-build命令尝试构建模型引擎,但由于缺少必要的tensor,会抛出RuntimeError。
- 使用
错误原因分析
-
缺少必要tensor:
- 错误信息指出缺少
transformer.vocab_embedding.weight和lm_head.weight这两个tensor,这是因为在模型定义中,这两个是唯一的Parameter对象。
- 错误信息指出缺少
-
模型定义:
YuxinTransformer类定义了一个Transformer模型,其中vocab_embedding是一个Embedding对象,它有一个weight字段作为Parameter对象。YuxinForCausalLM类继承自DecoderModelForCausalLM,它包含一个transformer和一个lm_head。lm_head是一个Linear对象,由于在实例化时传入了bias=False,所以只有weight字段是Parameter对象。
Tensor自动加载实践 -如何在TensorRT-LLM框架中生成、构造和加载模型权重,以及如何通过构建和运行模型来验证权重的正确性。通过这个实践,可以确保模型的权重被正确地初始化并用于推理。
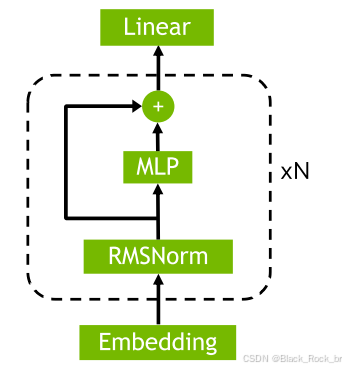
在TensorRT-LLM框架中构建和复用内建模块的指南,特别是如何实现一个类似于LLaMA的模型结构。通过使用框架提供的优化模块,可以简化模型的构建过程,并提高模型的性能。
在TensorRT-LLM框架中实现多层模型的指南,特别是如何通过使用ModuleList或DecoderLayerList来解决TensorRT-LLM自动加载机制的问题。通过这种方式,可以确保每一层的参数都能被正确加载,从而实现一个完整的多层模型。
E:Checkpoint预处理:以下两个步骤
config.json预处理
权重预处理
课程第二部分:多卡部署-当模型大到单GPU无法容纳时,TensorRT-LLM中模型可以使用张量(Tensor)并行或流水线(Pipeline)并行,以将整个模型分布到多张GPU上。
我们用随机权重构建这个模型:
trtllm-build \
--model_config yuxin-test/config.json \
--output_dir engine_yuxin \
--kv_cache_type disabled
实现张量并行-张量并行将模型纵向切分,一个操作(OP)都被分片到多卡上。一个被分片的OP,其权重均分到各GPU上,各GPU执行完相同操作后,互相交换
各自分片结果,从而得到完整的结果,再执行后续OP。
由此可见,张量并行是细粒度并行,对每一个OP都是可感知的,因此,TensorRT-LLM的几乎所有内建模块都可以传入tp_size、tp_group等参数,控
制其张量并行行为。
在实现自定义模型时,支持张量并行是很简单的,对代码结构几乎不会有影响,只要在内建模块的构造函数中传入相应的tp_size、tp_group以及tp_rank等参数即可。
流水线并行将模型横向切分,每个GPU按顺序掌管模型中连续的若干层。当收到一个输入时,第一张GPU先执行,当hidden_states经过了第一张
GPU上的所有层处理后,便发送给第二张GPU。如此递推,直到在最后一张GPU上得到结果。
由此可见,流水线并行对OP是不可见的,并不改变OP的行为,它是组织层面的变化,需要用户在自定义模型中显式实现。


最后总结今天课程的重点:
-
TensorRT-LLM的基本框架:
- 介绍了如何使用TensorRT-LLM框架来优化大型语言模型的推理性能,包括模型的转换、保存、加载和运行。
-
TensorRT-LLM模型自定义与实现:
- 详细阐述了如何自定义TensorRT-LLM模型,包括创建模型类、注册模型、定义配置文件、构建引擎、运行模型等关键步骤。
-
TensorRT-LLM的基本框架:Checkpoint规范:
- 解释了模型权重的存储和加载规范,以及如何使用
safetensors文件来管理和查看模型权重。
- 解释了模型权重的存储和加载规范,以及如何使用
-
TensorRT-LLM的基本框架:Tensor自动加载原理:
- 描述了TensorRT-LLM如何通过匹配
safetensors文件中的tensor名称和Python代码中的变量名称来自动加载模型权重。
- 描述了TensorRT-LLM如何通过匹配
-
TensorRT-LLM的基本框架:Tensor自动加载实践:
- 提供了一个完整的示例,展示了如何在TensorRT-LLM框架中生成、构造和加载模型权重,以及如何通过构建和运行模型来验证权重的正确性。
-
TensorRT-LLM的丰富模块:复用内建模块:
- 介绍了如何复用TensorRT-LLM中提供的内建模块,如RMSNorm、Self-Attention等,来构建模型的各个组件。
-
TensorRT-LLM的丰富模块:实现多层模型:
- 展示了如何在TensorRT-LLM中实现多层模型,特别是如何使用
ModuleList或DecoderLayerList来构建和组织模型的层。
- 展示了如何在TensorRT-LLM中实现多层模型,特别是如何使用
-
多卡部署:流水线并行:
- 详细介绍了在TensorRT-LLM中实现多卡部署的流水线并行方法,包括如何在不同的GPU之间分配模型层和数据,以及如何实现数据在GPU之间的发送和接收。
-
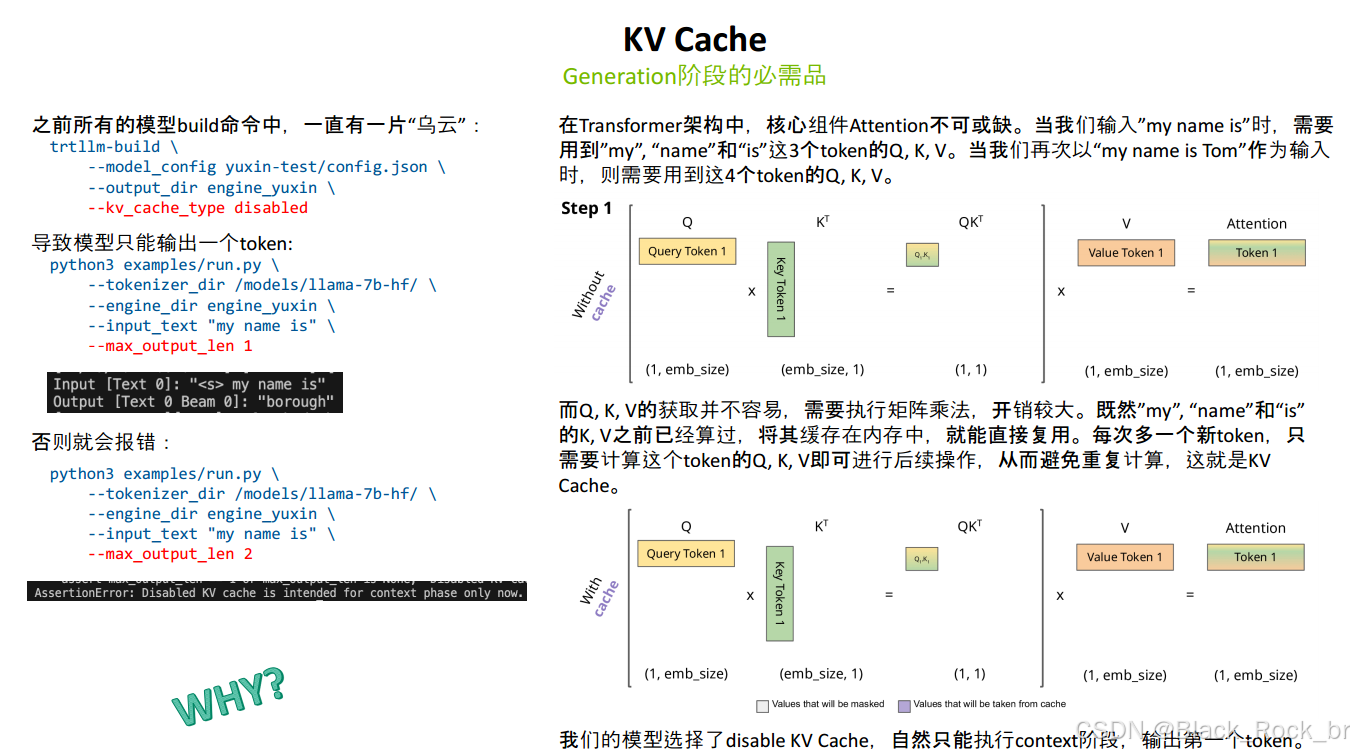
KV Cache:Generation阶段的必需品:
- 解释了KV Cache的重要性,它如何通过缓存已计算的K和V来避免重复计算,从而提高模型在生成阶段的效率。
-
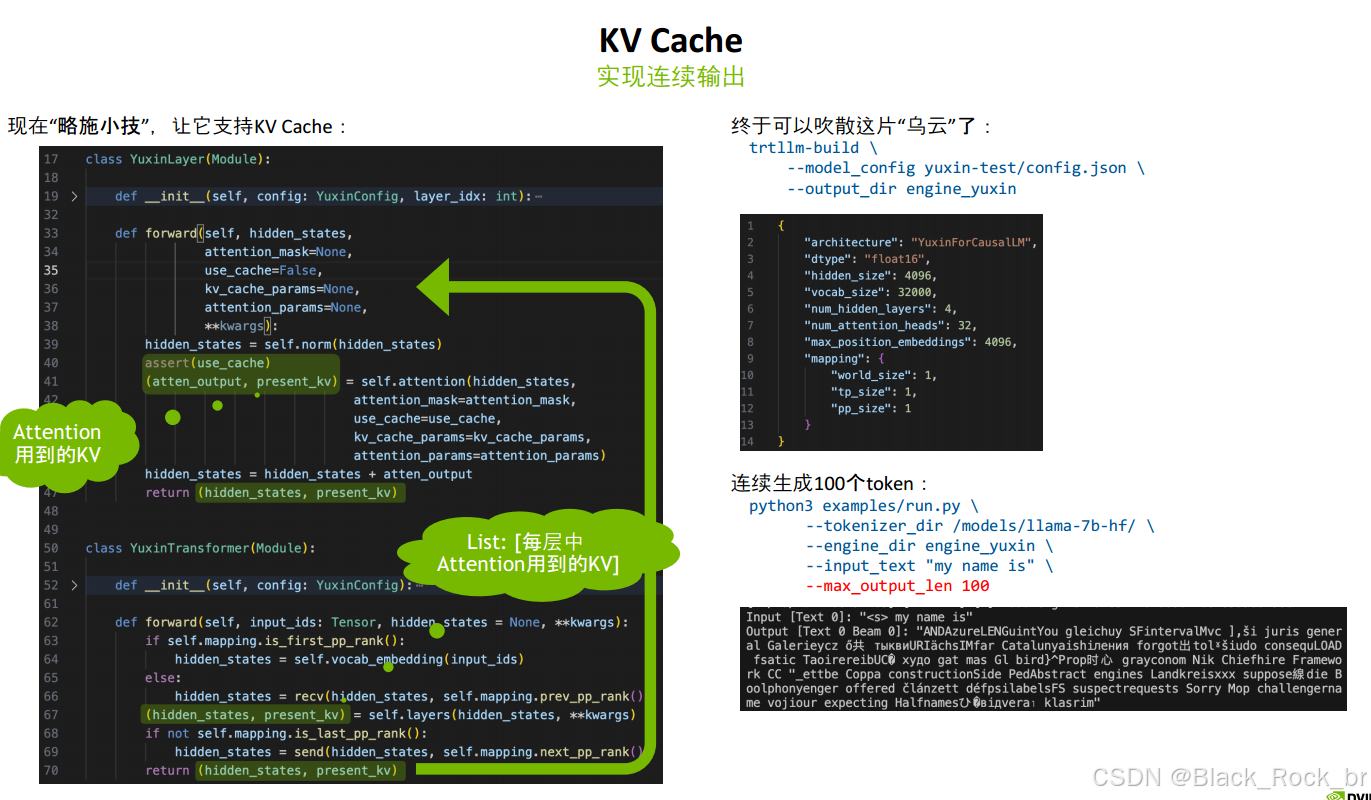
KV Cache:准备实验模型:
- 展示了如何构建一个使用Attention模块的模型,并在模型中准备KV Cache的使用。
-
KV Cache:实现连续输出:
- 介绍了如何修改模型以支持KV Cache,从而实现连续生成多个token的能力
这是今天课程全部的重点知识,梳理,应用点全部关键。
谢谢大家观看。

















 1443
1443

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









