






为什么需要这个算法?
尽管人体图像动画生成近年来成为研究热点,但现有方法仍存在诸多局限性,尤其是在粗粒度动画的表现上。这些方法在实现精细的整体控制、处理多尺度输入的泛化能力,以及确保长时间视频的时间连贯性方面,仍然面临重大挑战。因此,亟需一种更先进的解决方案来突破这些技术瓶颈。
---
这个算法能做什么?
DreamActor-M1(简称DA-M1)是一种基于DiT(Diffusion in Transformer)框架的创新算法,通过混合引导机制实现了对人体图像动画的高度可控性和逼真表现。只需提供一张参考图像,该算法便能够精准模仿从视频中提取的人类行为动作,并生成高表现力、跨尺度的高质量人类动画视频——无论是肖像级特写、上半身动作,还是全身动态效果。
---
这个算法效果如何?
大量实验结果表明,DA-M1在多个关键指标上均超越了当前最先进的基线方法。它不仅能够生成具有高度表现力的肖像、上身和全身动画,还能确保生成视频在时间维度上的连贯性,同时保留原始参考图像的身份特征并实现高保真输出。这种卓越的性能使得DA-M1成为人体图像动画领域的重要突破。


01-DA-M1背景简介
https://grisoon.github.io/DreamActor-M1/static/videos/2.mov
人体图像动画在视频生成领域备受关注,且在电影制作、广告业以及视频游戏等行业展现出巨大的应用潜力。不过,当前的技术手段大多只能生成较为粗糙的动画效果。在实现细节层面的精准操控(比如自然的眨眼动作、嘴唇的细微颤动)、应对不同尺度输入的适应性(涵盖肖像、上半身、全身等视角)以及维持长时间连贯性(例如服装等非关键部位在长时间内的稳定呈现)等方面,依旧存在诸多亟待攻克的难题。
02-DA-M1算法的核心要点
https://grisoon.github.io/DreamActor-M1/static/videos/1.mov
为了解决复杂场景中的动画生成问题,作者提出了一种基于DiT(扩散变换器)架构的框架DreamActor-M1,通过混合引导机制实现了整体性强、表现力丰富且鲁棒的人体图像动画生成。在运动引导方面,该框架整合了隐式面部表示、3D头部球体以及3D身体骨架信息,形成混合控制信号,从而能够精准驱动面部表情与身体动作,同时确保生成动画的高表现力和身份一致性。
为了应对不同比例和视角的挑战,DreamActor-M1采用渐进式训练策略,利用多分辨率和多比例的数据集进行训练,从而有效处理从肖像到全身视图的各种身体姿势和图像比例。在外观引导方面,作者通过结合连续帧的运动模式与视觉参考信息,确保即使在复杂运动中,不可见区域也能保持长期的时间连贯性,提升了生成视频的真实感和稳定性。
实验结果表明,DreamActor-M1在多个关键指标上显著优于现有的最先进方法,能够为肖像、上半身及全身动画生成提供高度逼真且富有表现力的结果,同时展现出卓越的长期时间一致性和鲁棒性.
03-DA-M1算法的详细流程阐述
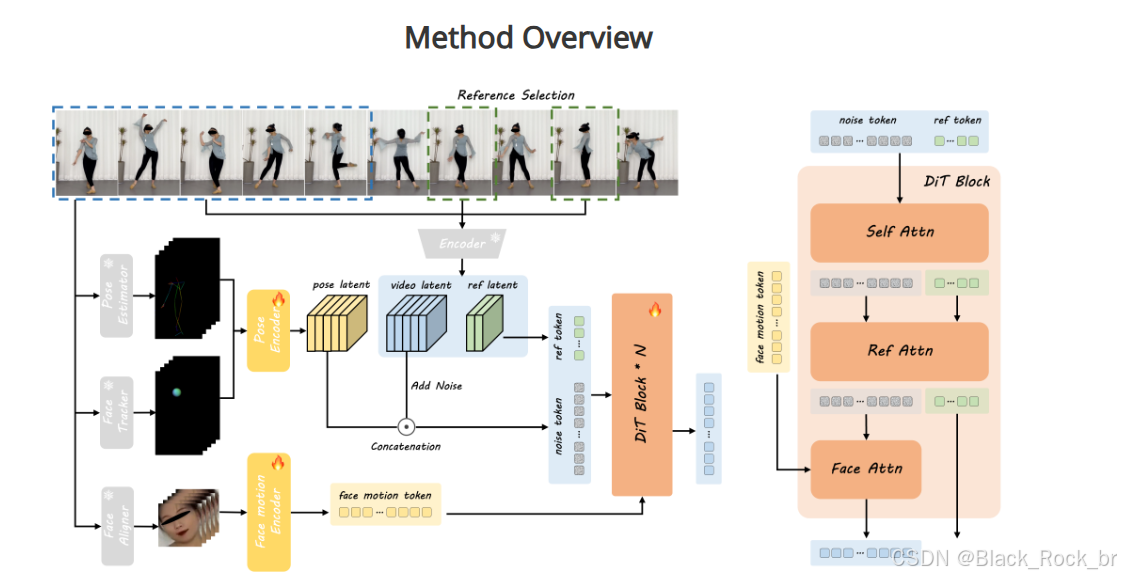
在 DreamActor-M1 算法的训练阶段,整个流程按照以下详细步骤展开:
1. 首先,对驱动帧进行处理,从中提取出身体骨架以及头部球体的相关信息。
2. 然后,借助姿态编码器,将提取到的信息编码成潜在的姿态表示形式。
3. 接下来,把得到的姿态潜特征与噪声视频潜特征沿着通道维度进行结合。其中,视频潜特征是通过采用 3D VAE 对输入全视频中的剪辑进行编码而获得的。此外,面部表情会由面部运动编码器进行额外编码,进而生成隐式的面部表示。
4. 最后,利用编码后的视频潜特征来监督去噪的视频潜特征。在每个 DiT 块内部,面部运动标记通过交叉注意力机制集成到噪声标记分支中;而参考标记所携带的外观信息则通过级联的自注意力(self-Att)以及后续的交叉注意力(ref-Att)注入到噪声标记里。
04-DA-M1 算法实现的详细步骤
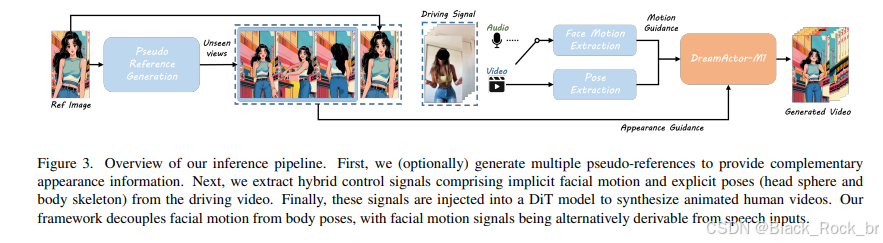
上图呈现了该算法的完整推理过程,具体步骤如下:
1. 首先,作者(可选)创建多个伪引用,以提供互补的外观信息。
2. 然后,作者从驾驶视频中提取混合控制信号,包括隐式面部运动和显式姿势(头部球体与身体骨架)。
3. 最后,将这些信号输入 DiT 模型,以合成动画人类视频。
需要指出的是,该框架将面部运动与身体姿势分开处理,面部运动信号也可以从语音输入中提取。
04.02-算法训练细节

采用预训练的图生视频模型进行初始化,并运用条件训练策略开展预热工作。整个训练过程分为三个阶段,各阶段的训练步数依次为20000步、20000步以及30000步。为了提升模型在面对不同持续时长与分辨率时的泛化性能,在训练阶段,随机从25到121帧的范围内选取采样视频片段的长度,同时将空间分辨率调整至960×640的尺寸范围,且保持原始的纵横比不变。
在所有训练阶段,均利用8个H20 GPU开展训练任务,选用AdamW优化器,将学习率设定为5e-6。在推理环节,每个视频片段包含73帧。为了保障完整视频的一致性,作者以当前片段中的最后一个潜特征作为下一个片段的初始潜特征,把下一个片段的生成过程视作一项图像到视频的生成任务来处理。参考信号和运动控制信号的无分类器制导(cfg)参数均被设置为2.5。
05-DA-M1 算法性能评估与分析
05.01主观效果性能评估方法与应用https://grisoon.github.io/DreamActor-M1/static/videos/pose-3.mov
在位姿迁移任务的生成效果方面,该方法与多个当前顶尖方法(DisPose、MimicMotion、Champ、Animate Anyone)进行了对比。经过细致的观察与深入的分析,可以得出结论:相较于其他基线方法,该方法能够生成具备细粒度运动、身份保持、时间连贯性以及高保真度的结果。
https://grisoon.github.io/DreamActor-M1/static/videos/portrait-3.mov
上述视频展示了该算法与多种最先进的方法(如 LivePortrait、X-Portrait、Skyreels-A1 和 Runway ActOne)在肖像动画任务中的生成效果对比。通过观察与分析可以发现,该算法在肖像驱动方面表现更为出色,能够实现对人像的精准精细控制,生成效果更加惊艳.
05.02 客观效果性能的实证分析
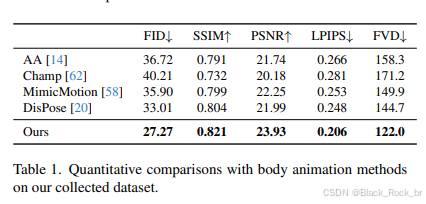
上表呈现了该算法与部分顶尖的身体驱动动画方法(AA、Champ、Mimic Motion、DisPose)在众多客观指标上的定量对比结果。经过细致的观察与深入的分析,可以初步得出以下结论:相较于其他方法,该算法在多项指标上均取得了最优的成绩,各项指标均实现了显著的提升。
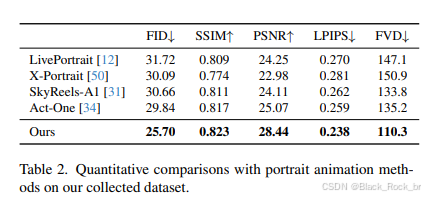
上表呈现了该方法与多个业界领先的肖像动画方法(如 LivePortrait、X-Portrait、SkyReels-A 和 Act-One)在客观指标上的评估结果。通过对比分析可以发现,该方法在多项关键指标上均实现了显著提升,与排名第二的方法拉开了明显差距,展现出卓越的性能优势 .


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









