







文章目录
引言
-
之前是不准备写这部分的代码分析,因为这个论文,仅仅是将所有的框架进行组合,实现的效果提高。他所用的三个部分分别是VQ-VAE、HiFi-GAN还有PixelSNAIL,这三部分相关论文还有代码我都看过了,但是直接看他的代码,看起来还是有点困难,所以在重新总结一下。
-
这里将会结合他的论文,重点看看作者在各个部分提出的创新点,在代码中是如何体现的。这里给出个人翻译的论文链接
-
在看具体代码之前,先将之前整理的三部分相关链接列举如下
-
PixelSNAIL
-
VQ-VAE
- 论文+代码:代码
-
HiFi-GAN
-
正文
- 正文部分将直接根据代码进行展开,主要分为以下几个部分
- 数据预处理文件:datasets.py 和 audio2mel.py
- vq-vae模型和特征提取:train_vq-vae.py、vqvae.py、extract_code.py
- pixelSNAIL模型生成和序列生成:pixelsnail.py 和train_pixelsnail.py
- HiFi-GAN声码器:HiFiGanWrapper.py
- 声音生成:inference.py
数据预处理
-
这部分,作者按照如下的流程处理数据
- 读取音频,并比较长度,将所有音频统一到相同长度
- 将相同长度的音频转成mel频谱图
- 这里是作者自定义的转换方式,虽然大致相同,但是在padding过程中,和torchaudio中定义的不一样,所以不能使用torchaudio中的转换方式。
- 创建dataset对象,可以直接使用dataloader进行加载
-
我对这里的代码进行了修改,因为将音频转成mel频谱图需要时间,所以,我直接将所有的音频直接转成nel频谱图进行保存,然后dataset对象是加载mel频谱图对象的。
-
下述文件是见wav文件,保存为npy文件
import librosa
import torch
import torchaudio
from pathlib import Path
import yaml
from easydict import EasyDict
import numpy as np
import torchaudio.transforms as T
# 音频预处理:确保采样率和长度一致
def process_audio(filename, max_length, target_sample_rate):
"""
使用 torchaudio 加载音频文件,并将其长度和采样率统一。
参数:
- filename (str): 音频文件的路径。
- max_length (int): 音频数据的目标最大长度。
- target_sample_rate (int): 目标采样率。
返回:
- np.ndarray: 处理后的音频数据。
"""
# 加载音频文件
waveform, sr = torchaudio.load(filename)
# 如果采样率不同,进行重采样
if sr != target_sample_rate:
resampler = T.Resample(orig_freq=sr, new_freq=target_sample_rate)
waveform = resampler(waveform)
# 选择第一个通道(假设是单声道)
audio = waveform[0].numpy()
# 超过最大长度,截断
if len(audio) > max_length:
audio = audio[0 : max_length]
# 不足最大长度,填充
elif len(audio) < max_length:
audio = np.pad(audio, (0, max_length - len(audio)), 'constant')
return audio
# 音频预处理:将音频转成对应的mel频谱图
def wav2mel(audio_file,yaml_file):
# 加载yaml文件,获取配置信息
with open(yaml_file) as conf:
cfg = EasyDict(yaml.safe_load(conf))
# 加载文件
waveform, sr = torchaudio.load(audio_file)
assert sr == cfg.sample_rate
# 加载mel处理实例
to_mel_spectrogram = torchaudio.transforms.MelSpectrogram(
sample_rate=cfg.sample_rate, n_fft=cfg.n_fft, n_mels=cfg.n_mels,
hop_length=cfg.hop_length, f_min=cfg.f_min, f_max=cfg.f_max)
# 将音频转成对应log-mel频谱图
log_mel_spec = to_mel_spectrogram(waveform).log()
return log_mel_spec
# 提取为对应的mel频谱图
mel_basis = {}
hann_window = {}
def dynamic_range_compression_torch(x, C=1, clip_val=1e-5):
return torch.log(torch.clamp(x, min=clip_val) * C)
def spectral_normalize_torch(magnitudes):
output = dynamic_range_compression_torch(magnitudes)
return output
def mel_spectrogram_hifi(
audio, n_fft, n_mels, sample_rate, hop_length, fmin, fmax, center=False
):
# 将音频转成Pytorch Tensor
audio = torch.FloatTensor(audio)
# 在原来的维度上增加一个维度,用于批处理
audio = audio.unsqueeze(0)
# 检查音频的最大值和最小值是否在[-1, 1]之间
if torch.min(audio) < -1.0:
print('min value is ', torch.min(audio))
if torch.max(audio) > 1.0:
print('max value is ', torch.max(audio))
# 定义全局变量mel_basis和hann_window
global mel_basis, hann_window
if fmax not in mel_basis:
mel_fb = librosa.filters.mel(
sr=sample_rate, n_fft=n_fft, n_mels=n_mels, fmin=fmin, fmax=fmax
)
mel_basis[str(fmax) + '_' + str(audio.device)] = (
torch.from_numpy(mel_fb).float().to(audio.device)
)
hann_window[str(audio.device)] = torch.hann_window(n_fft).to(audio.device)
audio = torch.nn.functional.pad(
audio,
(int((n_fft - hop_length) / 2), int((n_fft - hop_length) / 2)),
mode='reflect',
)
audio = audio.squeeze(1)
spec = torch.stft(
audio,
n_fft,
hop_length=hop_length,
window=hann_window[str(audio.device)],
center=center,
pad_mode='reflect',
normalized=False,
onesided=True,
return_complex=False,
)
spec = torch.sqrt(spec.pow(2).sum(-1) + 1e-9)
mel = torch.matmul(mel_basis[str(fmax) + '_' + str(audio.device)], spec)
mel = spectral_normalize_torch(mel).numpy()
return mel
'''将音频数据集转成对应的mel频谱图数据集并保存到指定路径'''''
def wav2mel_save(root_path,audio_dataset,yaml_file,mel_dataset,clip_val = 1e-5,C = 1):
'''
将数据集下方的所有音频文件转成对应的mel频谱图并保存到指定路径
:param root_path: 数据集所在文件的根目录
:param audio_dataset: 跟目录下方数据集的文件夹名称
:param yaml_file: 配置文件的路径
:param mel_dataset: 需要保存的mel频谱图数据集的根目录
:return:
'''
# 加载eav转成mel的实例对象
# 加载yaml文件,获取配置信息
with open(yaml_file) as conf:
cfg = EasyDict(yaml.safe_load(conf))
# 加载mel处理实例
# to_mel_spectrogram = torchaudio.transforms.MelSpectrogram(center=False,
# onesided=True,normalized=False,pad_mode='reflect',
# sample_rate=cfg.sample_rate, n_fft=cfg.n_fft, n_mels=cfg.n_mels,
# hop_length=cfg.hop_length, f_min=cfg.f_min, f_max=cfg.f_max)
# 处理数据
audio_lengths = []
originRoot = Path(root_path) # 原始音频数据集根目录
targetPath = Path(mel_dataset) # mel频谱图数据集根目录
print('开始处理数据集:', audio_dataset)
for folder in audio_dataset:
cur_folder = originRoot / folder
filenames = sorted(cur_folder.glob('*.wav'))
# 遍历所有wav文件
for filename in filenames:
# 加载wav文件
waveform, sr = torchaudio.load(filename)
# print('sample rate',sr)
# print(cfg.sample_rate)
assert sr == cfg.sample_rate
# 检查音频数据是否在[-1,1]之间
# print('min value is ', torch.min(waveform))
# print('min value is ', torch.max(waveform))
if torch.min(waveform) < -1.0:
print('min value is ', torch.min(waveform))
if torch.max(waveform) > 1.0:
print('max value is ', torch.max(waveform))
# 计算音频长度并且保存
num_samples = waveform.shape[-1] # Assuming shape is (num_channels, num_samples)
audio_length = num_samples / sr
audio_lengths.append(audio_length)
# 处理音频,确保长度和采样率一致
# waveform = process_audio(filename, max_length, target_sample_rate)
# waveform = torch.from_numpy(waveform)
# 将数据的之給你西那个动态压缩到[-clip_val,clip_val]之间,将输出进行正则化
# print(waveform.shape)
# log_mel_spec = to_mel_spectrogram(waveform).clamp(min=clip_val) * C
# log_mel_spec = log_mel_spec.log()
waveform = waveform.numpy()
mel_spec = mel_spectrogram_hifi(
waveform,
n_fft=cfg.n_fft,
n_mels=cfg.n_mels,
hop_length=cfg.hop_length,
sample_rate=cfg.sample_rate,
fmin=cfg.f_min,
fmax=cfg.f_max,
)
# Write to work
(targetPath / folder).mkdir(parents=True, exist_ok=True)
np.save(targetPath / folder / filename.name.replace('.wav', '.npy'), mel_spec)
audio_lengths.sort()
index_20_percent = int(0.6 * len(audio_lengths))
min_length_80_percent = audio_lengths[index_20_percent]
return min_length_80_percent
if __name__ == '__main__':
# 测试wav2mel函数
# audio_file = r'/home/yunlong/PycharmProjects/VAEGenerate/src/SoundAnalysis/ClarifyMode/FSDKaggle2018.audio_train/0a0a8d4c.wav'
# yaml_file = r'/home/yunlong/PycharmProjects/VAEGenerate/src/SoundAnalysis/ClarifyMode/config.yaml'
# print(wav2mel(audio_file,yaml_file).shape)
# 测试wav2mel_save函数,保存的张量是[64,401]
root_path = r'/home/yunlong/PycharmProjects/VAEGenerate/src/Paper/FolySound/DCASEFoleySoundSynthesisDevSet'
audio_dataset = ['DogBark','Footstep','GunShot','Keyboard','MovingMotorVehicle','Rain','Sneeze_Cough']
yaml_file = r'/home/yunlong/PycharmProjects/VAEGenerate/src/Paper/FolySound/config.yaml'
mel_dataset = r'/home/yunlong/PycharmProjects/VAEGenerate/src/Paper/FolySound/work'
print(wav2mel_save(root_path,audio_dataset,yaml_file,mel_dataset))
- 下述文件是加载npy文件,作为dataset类进行保存
def GetData(base_path):
'''
获取filename音频数据集的类、labels对应的标签、num_classes类别数
:param base_path: 数据文件所在文件
:return:
'''
# 加载训练数据和标签
filenames = []
label_indices = []
index_to_label = {}
# Iterate over each subdirectory in the base directory
for index, label_name in enumerate(os.listdir(base_path)):
label_path = os.path.join(base_path, label_name)
# 检查目录是否存在
if os.path.isdir(label_path):
# 保存label和index的对应关系
index_to_label[index] = label_name
# 迭代每一个子目录下的文件
for filename in os.listdir(label_path):
file_path = os.path.join(label_path, filename)
# 检查路径是否是文件
if os.path.isfile(file_path):
filenames.append(file_path)
label_indices.append(index)
return filenames, label_indices, index_to_label
class MelDataset(torch.utils.data.Dataset):
''' 对于数据处理类,要明确他的标签,文件名,以及数据的长度 '''
def __init__(self, filenames, labels, transforms=None,cfg = None):
assert len(filenames) == len(labels), f'Inconsistent length of filenames and labels.'
# 读取配置文件
with open(yaml_file) as conf:
cfg = EasyDict(yaml.safe_load(conf))
self.filenames = filenames
self.labels = labels
self.transforms = transforms
# 计算需要处理的音频的长度
# self.sample_length = int((cfg.clip_length * cfg.sample_rate + cfg.hop_length - 1) // cfg.hop_length)
# print(self.sample_length)
# print(self[0][0].shape[-1])
# 测试第一个 wav 文件的长度
# assert self[0][0].shape[-1] == self.sample_length, f'Check your files, failed to load {filenames[0]}'
# 展示基本信息
# print(
# f'Dataset will yield log-mel spectrogram {len(self)} data samples in shape [1, {cfg.n_mels}, {self[0][0].shape[-1]}]')
def __len__(self):
return len(self.filenames)
def __getitem__(self, index):
'''
返回索引index对应的数据和标签
:param index: 需要找到的数据的索引
:return:
'''
assert 0 <= index and index < len(self)
# 读取数据
log_mel_spec = np.load(self.filenames[index])
def sample_length(log_mel_spec):
return log_mel_spec.shape[-1]
# print(log_mel_spec.shape)
# # 填补数据到特定的长度
# pad_size = self.sample_length - sample_length(log_mel_spec)
# if pad_size > 0:
# offset = pad_size // 2
# log_mel_spec = np.pad(log_mel_spec, ((0, 0), (0, 0), (offset, pad_size - offset)), 'constant')
# print(log_mel_spec.shape)
#
# # 剪裁数据到特定的长度
# crop_size = sample_length(log_mel_spec) - self.sample_length
# if crop_size > 0:
# start = np.random.randint(0, crop_size)
# log_mel_spec = log_mel_spec[..., start:start + self.sample_length]
# print(log_mel_spec.shape)
# 使用数据增强
if self.transforms is not None:
log_mel_spec = self.transforms(log_mel_spec)
# 处理 -inf 的值
if np.isneginf(log_mel_spec).any():
log_mel_spec[np.isneginf(log_mel_spec)] = 0 # 或者你想替换成的任何其他值
# 在第 0 维(最前面)添加一个新的维度,因为 PyTorch 的输入是一个 batch
return torch.Tensor(log_mel_spec), self.labels[index]
vq-vae模型和特征提取
VQ-VAE模型定义
-
VQ-VAE模型是对mel频谱图进行特征提取,将之保存为时频域的码本序列。正常的VQ-VAE是由三部分构成,分别是
- Encoder编码器
- Quantized Layer:矢量量化层
- Decoder解码器
-
而这篇文章中,关于VQ-VAE的创新点在编码器中,他使用了多尺度卷积模式,由多个并行的,不同步长的卷积层提取特征,然后在经过各自对应的残差网络层进行处理,然后将结果进行累加,具体流程图如下。
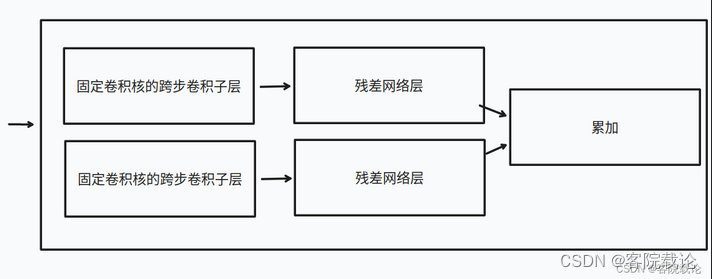
- 在代码中的体现如下
- 看起来很直观,尺度的不同体现在每一个模块的卷积核大小不同,分别是4、2、6、8,然后对应的padding分别是1、0、2、3.借此实现多尺度,分别提取到不同颗粒度下的特征。
class Encoder(nn.Module):
def __init__(self, in_channel, channel, n_res_block, n_res_channel, stride):
super().__init__()
if stride == 4:
blocks_1 = [
nn.Conv2d(in_channel, channel // 2, 4, stride=2, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(channel // 2, channel, 4, stride=2, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(channel, channel, 3, padding=1),
]
blocks_2 = [
nn.Conv2d(in_channel, channel // 2, 2, stride=2, padding=0),
nn.ReLU(inplace=True),
nn.Conv2d(channel // 2, channel, 2, stride=2, padding=0),
nn.ReLU(inplace=True),
nn.Conv2d(channel, channel, 3, padding=1),
]
blocks_3 = [
nn.Conv2d(in_channel, channel // 2, 6, stride=2, padding=2),
nn.ReLU(inplace=True),
nn.Conv2d(channel // 2, channel, 6, stride=2, padding=2),
nn.ReLU(inplace=True),
nn.Conv2d(channel, channel, 3, padding=1),
]
blocks_4 = [
nn.Conv2d(in_channel, channel // 2, 8, stride=2, padding=3),
nn.ReLU(inplace=True),
nn.Conv2d(channel // 2, channel, 8, stride=2, padding=3),
nn.ReLU(inplace=True),
nn.Conv2d(channel, channel, 3, padding=1),
]
for i in range(n_res_block):
blocks_1.append(ResBlock(channel, n_res_channel))
blocks_2.append(ResBlock(channel, n_res_channel))
blocks_3.append(ResBlock(channel, n_res_channel))
blocks_4.append(ResBlock(channel, n_res_channel))
blocks_1.append(nn.ReLU(inplace=True))
blocks_2.append(nn.ReLU(inplace=True))
blocks_3.append(nn.ReLU(inplace=True))
blocks_4.append(nn.ReLU(inplace=True))
self.blocks_1 = nn.Sequential(*blocks_1)
self.blocks_2 = nn.Sequential(*blocks_2)
self.blocks_3 = nn.Sequential(*blocks_3)
self.blocks_4 = nn.Sequential(*blocks_4)
def forward(self, input):
return (
self.blocks_1(input)
+ self.blocks_2(input)
+ self.blocks_3(input)
+ self.blocks_4(input)
)
# return self.blocks_1(input)
- 完整代码如下,其他的并没有什么改进,都是常见的VQ-VAE部分
import torch
from torch import nn
from torch.nn import functional as F
# Copyright 2018 The Sonnet Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ============================================================================
# Borrowed from https://github.com/deepmind/sonnet and ported it to PyTorch
class Quantize(nn.Module):
def __init__(self, dim, n_embed, decay=0.99, eps=1e-5):
super().__init__()
self.dim = dim #
self.n_embed = n_embed
self.decay = decay
self.eps = eps
embed = torch.randn(dim, n_embed)
self.register_buffer("embed", embed)
self.register_buffer("cluster_size", torch.zeros(n_embed))
self.register_buffer("embed_avg", embed.clone())
def forward(self, input):
flatten = input.reshape(-1, self.dim)
dist = (
flatten.pow(2).sum(1, keepdim=True)
- 2 * flatten @ self.embed
+ self.embed.pow(2).sum(0, keepdim=True)
)
_, embed_ind = (-dist).max(1)
embed_onehot = F.one_hot(embed_ind, self.n_embed).type(flatten.dtype)
embed_ind = embed_ind.view(*input.shape[:-1])
quantize = self.embed_code(embed_ind)
if self.training:
embed_onehot_sum = embed_onehot.sum(0)
embed_sum = flatten.transpose(0, 1) @ embed_onehot
self.cluster_size.data.mul_(self.decay).add_(
embed_onehot_sum, alpha=1 - self.decay
)
self.embed_avg.data.mul_(self.decay).add_(embed_sum, alpha=1 - self.decay)
n = self.cluster_size.sum()
cluster_size = (
(self.cluster_size + self.eps) / (n + self.n_embed * self.eps) * n
)
embed_normalized = self.embed_avg / cluster_size.unsqueeze(0)
self.embed.data.copy_(embed_normalized)
diff = (quantize.detach() - input).pow(2).mean()
quantize = input + (quantize - input).detach()
return quantize, diff, embed_ind
def embed_code(self, embed_id):
return F.embedding(embed_id, self.embed.transpose(0, 1))
class ResBlock(nn.Module):
def __init__(self, in_channel, channel):
super().__init__()
self.conv = nn.Sequential(
nn.ReLU(inplace=True),
nn.Conv2d(in_channel, channel, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(channel, in_channel, 1),
)
def forward(self, input):
out = self.conv(input)
out += input
return out
class Encoder(nn.Module):
def __init__(self, in_channel, channel, n_res_block, n_res_channel, stride):
super().__init__()
if stride == 4:
blocks_1 = [
nn.Conv2d(in_channel, channel // 2, 4, stride=2, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(channel // 2, channel, 4, stride=2, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(channel, channel, 3, padding=1),
]
blocks_2 = [
nn.Conv2d(in_channel, channel // 2, 2, stride=2, padding=0),
nn.ReLU(inplace=True),
nn.Conv2d(channel // 2, channel, 2, stride=2, padding=0),
nn.ReLU(inplace=True),
nn.Conv2d(channel, channel, 3, padding=1),
]
blocks_3 = [
nn.Conv2d(in_channel, channel // 2, 6, stride=2, padding=2),
nn.ReLU(inplace=True),
nn.Conv2d(channel // 2, channel, 6, stride=2, padding=2),
nn.ReLU(inplace=True),
nn.Conv2d(channel, channel, 3, padding=1),
]
blocks_4 = [
nn.Conv2d(in_channel, channel // 2, 8, stride=2, padding=3),
nn.ReLU(inplace=True),
nn.Conv2d(channel // 2, channel, 8, stride=2, padding=3),
nn.ReLU(inplace=True),
nn.Conv2d(channel, channel, 3, padding=1),
]
for i in range(n_res_block):
blocks_1.append(ResBlock(channel, n_res_channel))
blocks_2.append(ResBlock(channel, n_res_channel))
blocks_3.append(ResBlock(channel, n_res_channel))
blocks_4.append(ResBlock(channel, n_res_channel))
blocks_1.append(nn.ReLU(inplace=True))
blocks_2.append(nn.ReLU(inplace=True))
blocks_3.append(nn.ReLU(inplace=True))
blocks_4.append(nn.ReLU(inplace=True))
self.blocks_1 = nn.Sequential(*blocks_1)
self.blocks_2 = nn.Sequential(*blocks_2)
self.blocks_3 = nn.Sequential(*blocks_3)
self.blocks_4 = nn.Sequential(*blocks_4)
def forward(self, input):
return (
self.blocks_1(input)
+ self.blocks_2(input)
+ self.blocks_3(input)
+ self.blocks_4(input)
)
# return self.blocks_1(input)
class Decoder(nn.Module):
def __init__(
self, in_channel, out_channel, channel, n_res_block, n_res_channel, stride
):
super().__init__()
blocks = [nn.Conv2d(in_channel, channel, 3, padding=1)]
for i in range(n_res_block):
blocks.append(ResBlock(channel, n_res_channel))
blocks.append(nn.ReLU(inplace=True))
if stride == 4:
blocks.extend(
[
nn.ConvTranspose2d(channel, channel // 2, 4, stride=2, padding=1),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(
channel // 2, out_channel, 4, stride=2, padding=1
),
]
)
elif stride == 2:
blocks.append(
nn.ConvTranspose2d(channel, out_channel, 4, stride=2, padding=1)
)
self.blocks = nn.Sequential(*blocks)
def forward(self, input):
return self.blocks(input)
class VQVAE(nn.Module):
def __init__(
self,
in_channel=1, # for mel-spec.
channel=128,
n_res_block=2,
n_res_channel=32,
embed_dim=64,
n_embed=512,
decay=0.99,
):
super().__init__()
self.enc_b = Encoder(in_channel, channel, n_res_block, n_res_channel, stride=4)
# self.enc_t = Encoder(channel, channel, n_res_block, n_res_channel, stride=2)
# self.quantize_conv_t = nn.Conv2d(channel, embed_dim, 1)
# self.quantize_t = Quantize(embed_dim, n_embed)
# self.dec_t = Decoder(embed_dim, embed_dim, channel, n_res_block, n_res_channel, stride=2)
self.quantize_conv_b = nn.Conv2d(channel, embed_dim, 1)
self.quantize_b = Quantize(embed_dim, n_embed)
# self.upsample_t = nn.ConvTranspose2d(
# embed_dim, embed_dim, 4, stride=2, padding=1
# )
self.dec = Decoder(
embed_dim,
in_channel,
channel,
n_res_block,
n_res_channel,
stride=4,
)
def forward(self, input):
quant_b, diff, _ = self.encode(input)
dec = self.decode(quant_b)
return dec, diff
def encode(self, input):
enc_b = self.enc_b(input)
# enc_t = self.enc_t(enc_b)
quant_b = self.quantize_conv_b(enc_b).permute(0, 2, 3, 1)
quant_b, diff_b, id_b = self.quantize_b(quant_b)
quant_b = quant_b.permute(0, 3, 1, 2)
diff_b = diff_b.unsqueeze(0)
return quant_b, diff_b, id_b
def decode(self, quant_b):
# _dec = self.dec_t(quant_t)
dec = self.dec(quant_b)
return dec
def decode_code(self, code_b):
quant_b = self.quantize_b.embed_code(code_b)
quant_b = quant_b.permute(0, 3, 1, 2)
dec = self.decode(quant_b)
return dec
if __name__ == '__main__':
import audio2mel
from datasets import get_dataset_filelist
from torch.utils.data import DataLoader
train_file_list, _ = get_dataset_filelist()
train_set = audio2mel.Audio2Mel(
train_file_list[0:4], 22050 * 4, 1024, 80, 256, 22050, 0, 8000
)
loader = DataLoader(train_set, batch_size=2, sampler=None, num_workers=2)
model = VQVAE()
a = torch.randn(3, 3).to('cuda')
print(a)
model = model.to('cuda')
for i, batch in enumerate(loader):
mel, id, name = batch
mel = mel.to('cuda')
out, latent_loss = model(mel)
print(out.shape)
if i == 5:
break
特征提取并保存
-
这部分是使用之前训练好的VQ-VAE模型,去将频谱图转成TF领域的码本编码,然后自归模型pixelSNAIL基于此序列进行训练,然后生成新的新的序列。
-
通过自编码器,将数据量很大的音频信号,通过VQ-VAE中的编码器,转成体积较小的时频域编码。
-
具体结构如下
def extract(lmdb_env, loader, model, device):
index = 0
# 设置加载数据的进度条
with lmdb_env.begin(write=True) as txn:
pbar = tqdm(loader)
# 遍历数据
for img, class_id, salience, filename in pbar:
img = img.to(device)
# 将mel频谱图输入编码器输出,转成码本序列
_, _, id_b = model.encode(img)
# id_t = id_t.detach().cpu().numpy()
id_b = id_b.detach().cpu().numpy()
# 将数据保存为对应的序列
for c_id, sali, file, bottom in zip(class_id, salience, filename, id_b):
row = CodeRow(
bottom=bottom, class_id=c_id, salience=sali, filename=file
)
txn.put(str(index).encode('utf-8'), pickle.dumps(row))
index += 1
pbar.set_description(f'inserted: {index}')
txn.put('length'.encode('utf-8'), str(index).encode('utf-8'))
PixelSNAIL自编码器训练
-
这部分是根据之前训练VQ-VAE的编码器encoder,将所有的数据转成对应的码本序列。然后PixelSNAIL将会使用这些码本序列进行训练,生成新的码本序列。
-
这部分主要有两个文件,分别是train_pixelsnail.py和pixelsnail.py文件。这里提前看了train_pixelsnail.py文件,发现作者在模型定义过程中做了一些修改,所以模型的训练阶段和正常的pixelSNAIL不一样,所以先从PixelSNIAL开始分析。
PixelSNAIL模型
-
这里PixelSNAIL模型接受的是vq-vae生成的码本序列,然后生成新的码本序列。关于pixelsnail模型的介绍,具体看一下几篇文章:
-
整个pixelsnail是需要自己实现的就只有三个部分,分别是因果卷积causal conv、残差模块residual block以及因果注意力模块causal attention block。实现之后,就需要将模块进行链接。这部分可以好好看看,别人是如何实现的,和我实现的有什么不同。具体如下图。
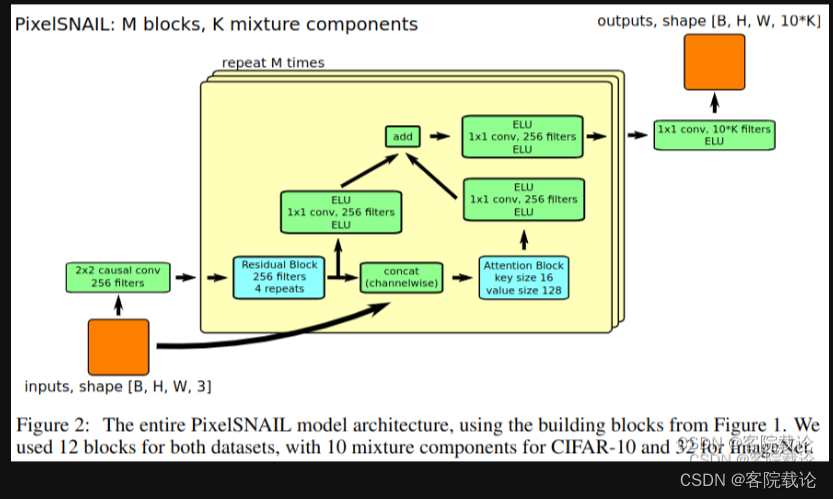
PixelSNAIL总的训练网络
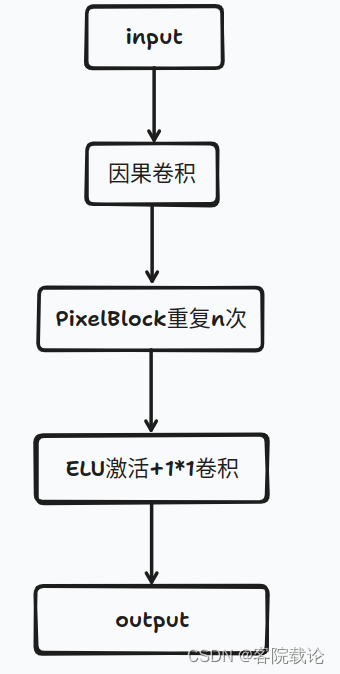
- 这部分网络是完全晚照上述图片进行展开的,主要是最后的一个ELU指数线性单元激活和1*1的权重归一化卷积实现。具体如下
class PixelSNAIL(nn.Module):
def __init__(
self,
shape,
n_class, # code nums
channel,
kernel_size,
n_block,
n_res_block,
res_channel,
attention=True,
dropout=0.1,
n_cond_res_block=0,
cond_res_channel=0,
cond_res_kernel=3,
n_out_res_block=0,
cond_embed_channel=1,
###
n_label=7, # data class nums
embed_dim=2048,
###
):
super().__init__()
height, width = shape
# 这里的类别数是指code的类别数
self.n_class = n_class
self.n_label = n_label
###
# 确定卷积核心
if kernel_size % 2 == 0:
kernel = kernel_size + 1
else:
kernel = kernel_size
# 水平卷积
self.horizontal = CausalConv2d(
n_class, channel, [kernel // 2, kernel], padding='down'
)
# 垂直卷积
self.vertical = CausalConv2d(
n_class, channel, [(kernel + 1) // 2, kernel // 2], padding='downright'
)
# 确定坐标信息矩阵,并将其转换为不可训练的参数
coord_x = (torch.arange(height).float() - height / 2) / height
coord_x = coord_x.view(1, 1, height, 1).expand(
1, 1, height, width
) # shape: torch.Size([1, 1, 20, 86])
coord_y = (torch.arange(width).float() - width / 2) / width
coord_y = coord_y.view(1, 1, 1, width).expand(
1, 1, height, width
) # shape: torch.Size([1, 1, 20, 86])
# print('x', coord_x.shape, 'y', coord_y.shape)
self.register_buffer(
'background', torch.cat([coord_x, coord_y], 1)
) # shape: self.background torch.Size([1, 2, 20, 86])
# 创建多个PixelBlock模块
self.blocks = nn.ModuleList()
for i in range(n_block):
self.blocks.append(
PixelBlock(
channel,
res_channel,
kernel_size,
n_res_block,
attention=attention,
dropout=dropout,
condition_dim=cond_embed_channel,
)
)
# 创建条件信息处理网络
if n_cond_res_block > 0:
self.cond_resnet = CondResNet(
n_class, cond_res_channel, cond_res_kernel, n_cond_res_block
)
###
# 处理条件信息的网络
# input_dim,hidden_dim,output_dim
self.embedNet = EmbedNet(n_label, embed_dim, 20 * 86)
###
# 输出层是多个门控残差块,每个门控残差块的输入通道数为channel,输出通道数为res_channel,卷积核大小为1
out = []
for i in range(n_out_res_block):
out.append(GatedResBlock(channel, res_channel, 1))
out.extend([nn.ELU(inplace=True), WNConv2d(channel, n_class, 1)])
self.out = nn.Sequential(*out)
def forward(self, input, label_condition=None, cache=None):
if cache is None:
cache = {}
batch, height, width = input.shape
# 将所有的输入转换为one-hot编码,因为每一个位置都是一个码字对应的编号,所以n_class对应的就是码字的个数,然后转成one-hot编码
# 修改形状,原来的形状为[batch, height, width,n_class],修改后的形状为[batch, n_class, height, width]
# 同时进行类型转换
input = (
F.one_hot(input, self.n_class).permute(0, 3, 1, 2).type_as(self.background)
)
# 通过移动实现水平和垂直的卷积,也就是因果卷积
horizontal = shift_down(self.horizontal(input))
vertical = shift_right(self.vertical(input))
out = horizontal + vertical
# print('background-1', self.background.shape)
background = self.background[:, :, :height, :].expand(
batch, 2, height, width
) # shape: torch.Size([32, 2, 20, 86])
# print('background-2', background.shape)
if True:
if 'condition' in cache:
condition = cache['condition']
condition = condition[:, :, :height, :]
else:
label = F.one_hot(label_condition, self.n_label).type_as(
self.background
)
# salience = salience_condition.unsqueeze(1)
# condition = torch.cat((label, salience), 2)
condition = label
condition = self.embedNet(condition)
condition = condition.view(-1, 1, 20, 86)
# print(condition.shape) #torch.Size([64, 1, 10, 43])
cache['condition'] = condition.detach().clone()
condition = condition[:, :, :height, :]
# if code_condition is not None:
# embed_condition = (
# F.one_hot(label_condition, self.n_label)
# .type_as(self.background)
# )
# embed_condition = self.embedNet(embed_condition)
# embed_condition = embed_condition.view(-1, 1, 10, 43)
# # print('embed-1', embed_condition.shape)
# embed_condition = F.interpolate(embed_condition, scale_factor=2)
# # print('embed-2', embed_condition.shape)
#
# condition = (
# F.one_hot(code_condition, self.n_class)
# .permute(0, 3, 1, 2)
# .type_as(self.background)
# )
# # condition.shape: torch.Size([32, 512, 10, 43]))
# condition = self.cond_resnet(condition)
# # print(condition.shape)
# condition = F.interpolate(condition, scale_factor=2)
# # print('before', condition.shape)
# condition = torch.cat([condition, embed_condition], 1)
# # print('after', condition.shape)
# # condition.shape: torch.Size([32, 256, 20, 86]))
# cache['condition'] = condition.detach().clone()
# # print(condition.shape)
# condition = condition[:, :, :height, :]
# 通过多个pixelBlock进行卷积,然后输出
for block in self.blocks:
out = block(out, background, condition=condition) # PixelBlock
# 直接ELU激活函数,然后通过一个1*1的卷积核进行卷积,输出通道数为n_class
out = self.out(out)
return out, cache
坐标信息矩阵
-
在这段代码中弄清楚了坐标信息矩阵,并且在notebook中详细实现了一下。这个矩阵为输入的每个位置(即每个像素或特征)创建了一个相对于中心的X和Y坐标,并将这些坐标作为“背景”张量存储起来。这为模型提供了关于每个位置在整个输入中的相对位置的信息。
-
下述为模型中具体实现的代码
coord_x = (torch.arange(height).float() - height / 2) / height
coord_x = coord_x.view(1, 1, height, 1).expand(
1, 1, height, width
) # shape: torch.Size([1, 1, 20, 86])
coord_y = (torch.arange(width).float() - width / 2) / width
coord_y = coord_y.view(1, 1, 1, width).expand(
1, 1, height, width
) # shape: torch.Size([1, 1, 20, 86])
# print('x', coord_x.shape, 'y', coord_y.shape)
self.register_buffer(
'background', torch.cat([coord_x, coord_y], 1)
) # shape: self.background torch.Size([1, 2, 20, 86])
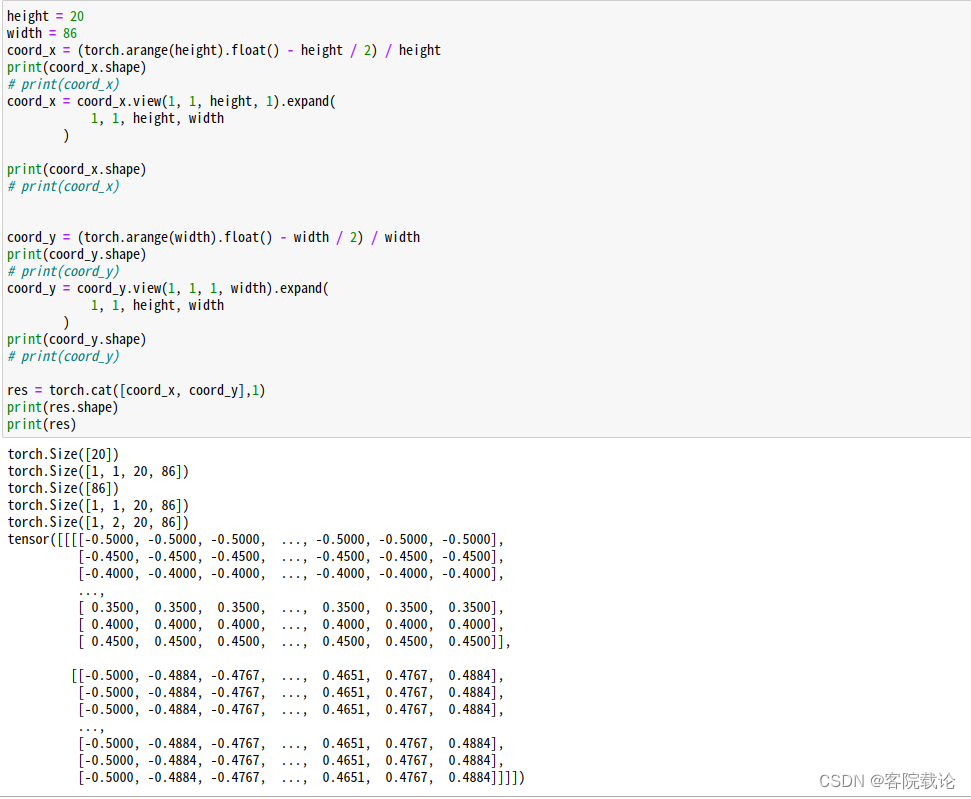
- 首先创建关于height,也就是纵轴的位置坐标信息。数值减去中间值,除以总长度,表示当前位置距离中间坐标的方向 和远近。然后在通过扩散原理,复制到每列。具体矩阵如下。
- 如下图可见,第一行和最后一行,距离中间矩阵最远。

- 同上,创建关于横坐标的位置信息,具体矩阵如下。
- 距离横坐标的中间位置越近,那么绝对值越小,越远,绝对值越大。

- 然后将两个矩阵进行拼接,在通道维度上进行拼接,第一个维度的坐标表示height纵轴的坐标信息,第二个维度的坐标表示width横轴的坐标信息。具体如下

- 总的代码如下
CausalConv2d因果卷积实现
- 这里是平移和掩码卷积同时使用,实现因果卷积。而且这里的掩码卷积并不是使用掩码层,而是将部分卷积层的权重置为0,实现的。
class CausalConv2d(nn.Module):
def __init__(
self,
in_channel,
out_channel,
kernel_size,
stride=1,
padding='downright',
activation=None,
):
super().__init__()
if isinstance(kernel_size, int):
kernel_size = [kernel_size] * 2
self.kernel_size = kernel_size
# 填充顺序是左右上下
if padding == 'downright':
pad = [kernel_size[1] - 1, 0, kernel_size[0] - 1, 0]
# 填充顺序是左右上下
elif padding == 'down' or padding == 'causal':
pad = kernel_size[1] // 2
pad = [pad, pad, kernel_size[0] - 1, 0]
self.causal = 0
if padding == 'causal':
self.causal = kernel_size[1] // 2
self.pad = nn.ZeroPad2d(pad)
# 使用权重归一化卷积
self.conv = WNConv2d(
in_channel,
out_channel,
kernel_size,
stride=stride,
padding=0,
activation=activation,
)
def forward(self, input):
out = self.pad(input)
# 如果是因果卷积,那么最后一行,从第 causal 列开始,全部置零
if self.causal > 0:
self.conv.conv.weight_v.data[:, :, -1, self.causal :].zero_()
out = self.conv(out)
return out
PixelBlock模块
门控残差网络实现GatedResBlock
-
这里就不具体解释,仅仅结合相关代码进行分析即可。
-
这里有一个函数必须得说一下,那就是门控函数GLU(),这里很贴心地给你进行了封装。
- 输入:它期望输入的维度至少为2,其中指定的维度(在这里是 1)的大小应该是偶数。
- 操作:在指定的维度上,它将输入分为两部分,称为 a 和 b。然后,它进行以下计算: o u t p u t = a × σ ( b ) output=a×σ(b) output=a×σ(b),其中 σ 是 Sigmoid 激活函数。
- 输出:输出的大小与原始输入的一半相同(在指定的维度上)。
- 样例:如果你有一个形状为 [batch_size, 2 * channels, height, width] 的输入并使用 nn.GLU(1),那么输出的形状将是 [batch_size, channels, height, width]。
-
说实话,这个代码实现起来确实很简洁,思路很清晰,如果全部自己实现,看起来确实会比较费劲。
class GatedResBlock(nn.Module):
def __init__(
self,
in_channel,
channel,
kernel_size,
conv='wnconv2d',
activation=nn.ELU,
dropout=0.1,
auxiliary_channel=0,
condition_dim=0,
):
super().__init__()
# 确定卷积层以及相关参数
# 就是给函数一个别名,并且冻结部分参数
if conv == 'wnconv2d':
conv_module = partial(WNConv2d, padding=kernel_size // 2)
elif conv == 'causal_downright':
conv_module = partial(CausalConv2d, padding='downright')
elif conv == 'causal':
conv_module = partial(CausalConv2d, padding='causal')
# 定义激活函数和卷积层
self.activation = activation()
self.conv1 = conv_module(in_channel, channel, kernel_size)
# 定义辅助通道数,根据是否有辅助信息决定是否使用辅助通道
if auxiliary_channel > 0:
self.aux_conv = WNConv2d(auxiliary_channel, channel, 1)
self.dropout = nn.Dropout(dropout)
self.conv2 = conv_module(channel, in_channel * 2, kernel_size)
# 定义条件通道数,根据是否有条件信息决定是否使用条件通道
if condition_dim > 0:
# self.condition = nn.Linear(condition_dim, in_channel * 2, bias=False)
self.condition = WNConv2d(condition_dim, in_channel * 2, 1, bias=False)
# 定义门控单元
self.gate = nn.GLU(1)
def forward(self, input, aux_input=None, condition=None):
# 将输入进行一次卷积
out = self.conv1(self.activation(input))
# 判定是否拥有辅助信息
if aux_input is not None:
out = out + self.aux_conv(self.activation(aux_input))
# 二次卷积处理
out = self.activation(out)
out = self.dropout(out)
out = self.conv2(out)
if condition is not None:
# print('condition', condition.shape)
condition = self.condition(condition)
out += condition
# out = out + condition.view(condition.shape[0], 1, 1, condition.shape[1])
out = self.gate(out)
out += input
return out
- 使用门控残差网络,能够增加挽留过模型的容量,又不增加计算的复杂度。
因果注意力机制实现CausalAttention
-
这部分是这个模型的关键部分,是因果卷积和注意力机制的结合。具体分析链接:链接
-
这里关于key、query以及value三个矩阵生成给了详细的过程解答,我也完全看懂了,但是这个理论,这个思想,怎么想出来?实在是难以理解,就算是实验出来的,但是这个想法思路,是按照什么思路想出来的。真的太厉害了。因为用到的很多,这里将这个矩阵的生成过程详细描述一下,首先看一下完整注释之后的代码和专门的因果卷积模块代码
-
下述为PixelBlock和CausalAttention两个模块。
class PixelBlock(nn.Module):
def __init__(
self,
in_channel,
channel,
kernel_size,
n_res_block,
attention=True,
dropout=0.1,
condition_dim=0,
):
super().__init__()
resblocks = []
for i in range(n_res_block):
resblocks.append(
GatedResBlock(
in_channel,
channel,
kernel_size,
conv='causal',
dropout=dropout,
condition_dim=condition_dim,
)
)
self.resblocks = nn.ModuleList(resblocks)
self.attention = attention
if attention:
# 514,256
self.key_resblock = GatedResBlock(
in_channel * 2 + 2, in_channel, 1, dropout=dropout
)
self.query_resblock = GatedResBlock(
in_channel + 2, in_channel, 1, dropout=dropout
)
self.causal_attention = CausalAttention(
in_channel + 2, in_channel * 2 + 2, in_channel // 2, dropout=dropout
)
self.out_resblock = GatedResBlock(
in_channel,
in_channel,
1,
auxiliary_channel=in_channel // 2,
dropout=dropout,
)
else:
self.out = WNConv2d(in_channel + 2, in_channel, 1)
def forward(self, input, background, condition=None):
out = input
# 经历过若干次残差网络之后,输出为out
for resblock in self.resblocks:
out = resblock(out, condition=condition)
# out的形状是[8,256,20,86]
if self.attention:
# 如果是注意力机制,在batch_size维度上进行拼接
# in_channel * 2 + 2, in_channel
# key_cat包含的信息是input、out、background,维度是[8,514,20,86]
key_cat = torch.cat([input, out, background], 1)
key = self.key_resblock(key_cat)
print('resnet key shape',key.shape)
# query的处理方式与key不同,缺少了input的信息
# in_channel + 2, in_channel
query_cat = torch.cat([out, background], 1)
# query的形状[8,258,20,86]
query = self.query_resblock(query_cat)
print('query_shape',query.shape)
# 实现因果注意力机制
# 注意力矩阵的形状为[8, 128, 20, 86]
attn_out = self.causal_attention(query, key)
print('atten_out shape',attn_out.shape)
# 最终的矩阵形状为[8,256,20,86]
out = self.out_resblock(out, attn_out)
print('out shape',out.shape)
else:
bg_cat = torch.cat([out, background], 1)
out = self.out(bg_cat)
return out
class CausalAttention(nn.Module):
def __init__(self, query_channel, key_channel, channel, n_head=8, dropout=0.1):
super().__init__()
# 定义查询、键、值对应层的权重归一化,用来同意他们的输出通道数
self.query = wn_linear(query_channel, channel)
self.key = wn_linear(key_channel, channel)
self.value = wn_linear(key_channel, channel)
# 定义头数和每个头的通道数
self.dim_head = channel // n_head
self.n_head = n_head
# 定义dropout层
self.dropout = nn.Dropout(dropout)
def forward(self, query, key):
# in_channel + 2, in_channel * 2 + 2, in_channel // 2, dropout=dropout
print('causal attention',key.shape)
batch, _, height, width = key.shape
# 定义一个reshape函数,用来将输入的query、key、value进行reshape
def reshape(input):
# 交换维度并且进行reshape
return input.view(batch, -1, self.n_head, self.dim_head).transpose(1, 2)
# 展平查询和键的形状以适应线性映射
print('causal attention query shape',query.shape)
# query shape:[8,258,20,86] = [batch_size,n_class+background_channel, height, width]
# query_flat shape:[8,1720,258] = [batch_size , height*width , n_class+backgound]
query_flat = query.view(batch, query.shape[1], -1).transpose(1, 2)
# key shape:[8,514,20,86] = [batch_size,n_class * 2 +background_channel, height, width]
# key_flat shape:[8,1720,514] = [batch_size , height*width , n_class * 2 +backgound]
key_flat = key.view(batch, key.shape[1], -1).transpose(1, 2)
# 将查询、键、值映射到适当的空间
print('causal attention query_flat shape',self.query(query_flat).shape)
# self.query()、self.key()、self.value()都是nn.Linear()层,实现数据降维,将之映射到128维
# key_flat:[8,1720,258] -> [8,1720,128]
# query_flat:[8,1720,514] -> [8,1720,128]
# 经过reshape之后,变为[batch_size, n_head, height*width, dim_head],也就是[8,8,1720,16]
# 对应的形状为
# query shape:[8, 8, 1720, 16] = [batch_size,n_head, height * width,head_dim]
# key shape:[8, 8, 16, 1720] = [batch_size,n_head , head_dim,height * width]
# value shape:[8, 8, 1720, 16] = [batch_size,n_head, height * width ,head_dim]
query = reshape(self.query(query_flat))
key = reshape(self.key(key_flat)).transpose(2, 3)
value = reshape(self.value(key_flat))
# 计算注意力权重
attn = torch.matmul(query, key) / sqrt(self.dim_head)
print(attn.shape)
# 获取因果遮罩,确保每个位置只关注其之前的位置
mask, start_mask = causal_mask(height * width)
mask = mask.type_as(query)
start_mask = start_mask.type_as(query)
# 将注意力权重与因果遮罩相乘
attn = attn.masked_fill(mask == 0, -1e4)
print(attn.shape)
# 将注意力权重进行softmax处理
attn = torch.softmax(attn, 3) * start_mask
# 对注意力权重进行dropout处理
attn = self.dropout(attn)
print('causal attention attn shape',attn.shape)
# 使用注意力权重得到输出
out = attn @ value
# 调整输出的形状
out = out.transpose(1, 2).reshape(
batch, height, width, self.dim_head * self.n_head
)
out = out.permute(0, 3, 1, 2)
return out
单头自注意力机制和多头自注意力机制
- 单头自注意力机制的简略版
import torch
import torch.nn as nn
import torch.nn.functional as F
class SingleHeadAttention(nn.Module):
def __init__(self, embed_size):
super(SingleHeadAttention, self).__init__()
self.embed_size = embed_size
self.query = nn.Linear(embed_size, embed_size)
self.key = nn.Linear(embed_size, embed_size)
self.value = nn.Linear(embed_size, embed_size)
def forward(self, x):
Q = self.query(x)
K = self.key(x)
V = self.value(x)
attn_weights = torch.matmul(Q, K.transpose(-2, -1)) / (self.embed_size ** 0.5)
attn_weights = F.softmax(attn_weights, dim=-1)
output = torch.matmul(attn_weights, V)
return output
# 使用
x = torch.randn(32, 10, 512) # batch_size=32, seq_length=10, embed_size=512
single_head_attn = SingleHeadAttention(512)
out = single_head_attn(x)
print(out.shape) # torch.Size([32, 10, 512])
- 多头自注意力机制的简略版
class MultiHeadAttention(nn.Module):
def __init__(self, embed_size, num_heads):
super(MultiHeadAttention, self).__init__()
self.embed_size = embed_size
self.num_heads = num_heads
self.head_dim = embed_size // num_heads
self.query = nn.Linear(embed_size, embed_size)
self.key = nn.Linear(embed_size, embed_size)
self.value = nn.Linear(embed_size, embed_size)
self.fc_out = nn.Linear(embed_size, embed_size)
def forward(self, x):
batch_size = x.shape[0]
Q = self.query(x).view(batch_size, -1, self.num_heads, self.head_dim)
K = self.key(x).view(batch_size, -1, self.num_heads, self.head_dim)
V = self.value(x).view(batch_size, -1, self.num_heads, self.head_dim)
attn_weights = torch.einsum("bqhd,bkhd->bhqk", [Q, K]) / (self.embed_size ** 0.5)
attn_weights = F.softmax(attn_weights, dim=-1)
output = torch.einsum("bhqk,bkhd->bqhd", [attn_weights, V]).reshape(batch_size, -1, self.embed_size)
output = self.fc_out(output)
return output
# 使用
x = torch.randn(32, 10, 512) # batch_size=32, seq_length=10, embed_size=512
multi_head_attn = MultiHeadAttention(512, 8)
out = multi_head_attn(x)
print(out.shape) # torch.Size([32, 10, 512])
- 通过上述代码可以看出以下几点
- 无论是query、key还有value,都是来自于输入矩阵,只不过是通过了不同的变换矩阵,并且改变了形状。
- 单头和多头差别在生成矩阵维度,但是总量是一致的。多头的个数 头的维度 = 单头矩阵空间的维度
注意力机制的三个矩阵query、key和value的具体形成过程
- 这里看过了简略版的注意力机制形成过程,现在具体整理一下整个代码中具体形成的逻辑和过程。
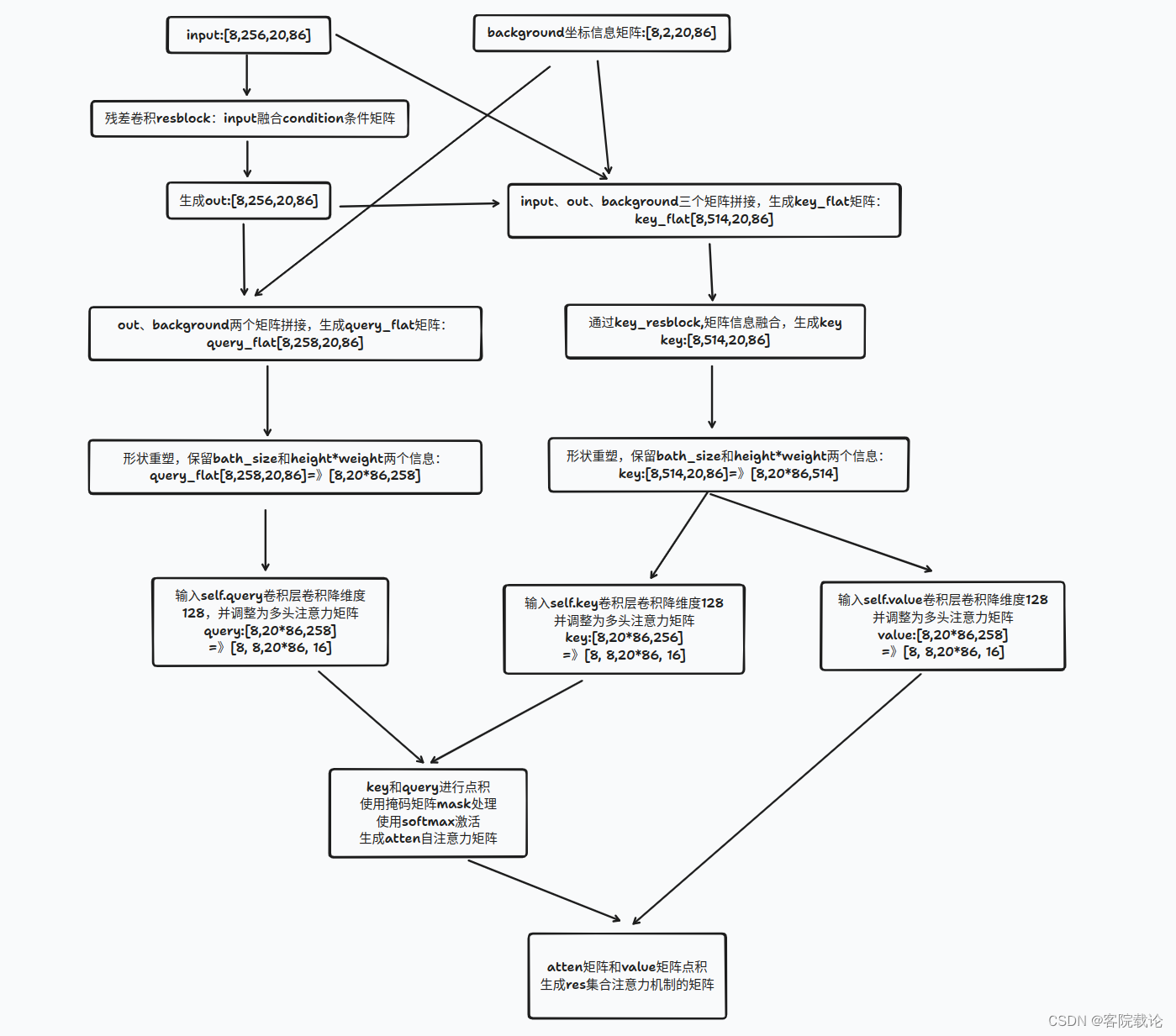
-
可以看到这里的query、key以及value三个矩阵都是使用来自于同一个矩阵,但是会经历各自不同的对应的卷积操作,形成query、key和value.
-
每一次矩阵拼接,都会使用卷积网络,改变通道,实现信息融合。
-
除了原始的输入矩阵可以作为生成query、key和value的依据,还可以增加表示位置信息的background矩阵,作为参考信息,进一步完善索引。
HiFi-GAN声码生成部分
-
这是整个代码的最后一部分,通过PixelSNAIL生成新的序列,然后再有训练好的VQ-VAE中的decoder将序列转成对应的mel频谱图,然后再由HiFi-GAN将之转成对应的波形图,提高声音的准确率。
-
这部分作者是使用HiFi-GAN论文中已经训练好的模型,仅仅使用他的generator,进行声音生成。
-
这里就结合HiFi-GAN的代码进行简单地分析,并不会详细讲解。具体的mel频谱图中的生成器模块结构如下
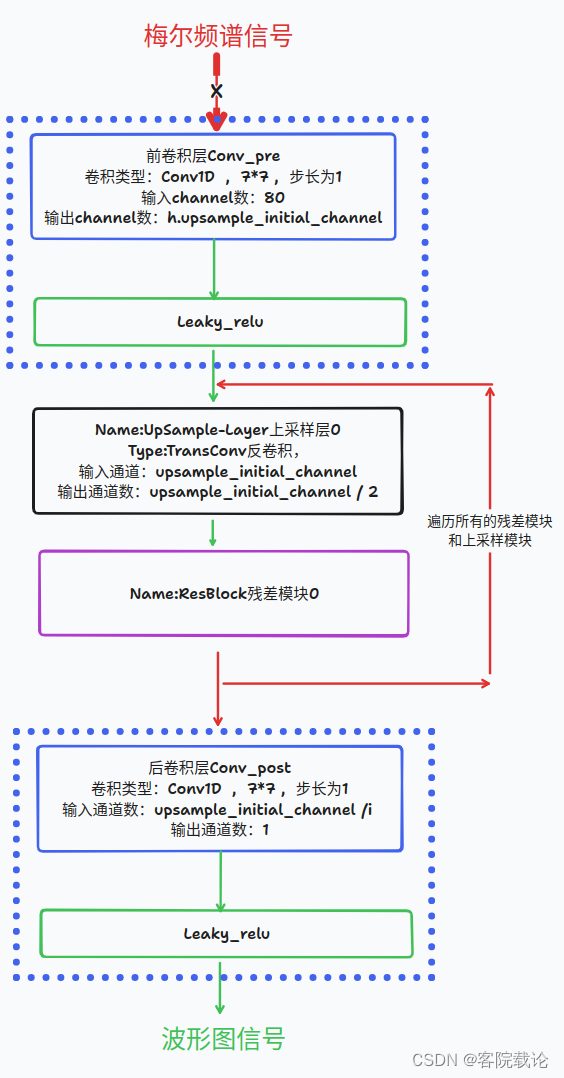
-
这里面有两种残差卷积模块,一个是resnetblock1,还有一个resnetblock2
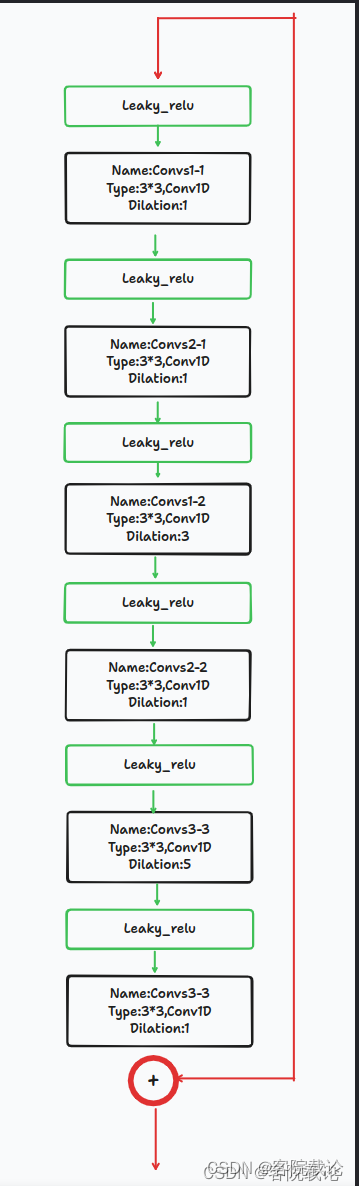
差别就是膨胀卷积的系数问题 -
下述是resnet block1
-
下述是resnetblock2
-
下述为完整代码
class ResBlock1(torch.nn.Module):
def __init__(self, h, channels, kernel_size=3, dilation=(1, 3, 5)):
super(ResBlock1, self).__init__()
self.h = h
self.convs1 = nn.ModuleList(
[
weight_norm(
Conv1d(
channels,
channels,
kernel_size,
1,
dilation=dilation[0],
padding=get_padding(kernel_size, dilation[0]),
)
),
weight_norm(
Conv1d(
channels,
channels,
kernel_size,
1,
dilation=dilation[1],
padding=get_padding(kernel_size, dilation[1]),
)
),
weight_norm(
Conv1d(
channels,
channels,
kernel_size,
1,
dilation=dilation[2],
padding=get_padding(kernel_size, dilation[2]),
)
),
]
)
self.convs1.apply(init_weights)
self.convs2 = nn.ModuleList(
[
weight_norm(
Conv1d(
channels,
channels,
kernel_size,
1,
dilation=1,
padding=get_padding(kernel_size, 1),
)
),
weight_norm(
Conv1d(
channels,
channels,
kernel_size,
1,
dilation=1,
padding=get_padding(kernel_size, 1),
)
),
weight_norm(
Conv1d(
channels,
channels,
kernel_size,
1,
dilation=1,
padding=get_padding(kernel_size, 1),
)
),
]
)
self.convs2.apply(init_weights)
def forward(self, x):
for c1, c2 in zip(self.convs1, self.convs2):
xt = F.leaky_relu(x, LRELU_SLOPE)
xt = c1(xt)
xt = F.leaky_relu(xt, LRELU_SLOPE)
xt = c2(xt)
x = xt + x
return x
def remove_weight_norm(self):
for l in self.convs1:
remove_weight_norm(l)
for l in self.convs2:
remove_weight_norm(l)
class ResBlock2(torch.nn.Module):
def __init__(self, h, channels, kernel_size=3, dilation=(1, 3)):
super(ResBlock2, self).__init__()
self.h = h
self.convs = nn.ModuleList(
[
weight_norm(
Conv1d(
channels,
channels,
kernel_size,
1,
dilation=dilation[0],
padding=get_padding(kernel_size, dilation[0]),
)
),
weight_norm(
Conv1d(
channels,
channels,
kernel_size,
1,
dilation=dilation[1],
padding=get_padding(kernel_size, dilation[1]),
)
),
]
)
self.convs.apply(init_weights)
def forward(self, x):
for c in self.convs:
xt = F.leaky_relu(x, LRELU_SLOPE)
xt = c(xt)
x = xt + x
return x
def remove_weight_norm(self):
for l in self.convs:
remove_weight_norm(l)
class Generator(torch.nn.Module):
def __init__(self, h):
super(Generator, self).__init__()
self.h = h
self.num_kernels = len(h.resblock_kernel_sizes)
self.num_upsamples = len(h.upsample_rates)
self.conv_pre = weight_norm(
Conv1d(80, h.upsample_initial_channel, 7, 1, padding=3)
)
resblock = ResBlock1 if h.resblock == '1' else ResBlock2
self.ups = nn.ModuleList()
for i, (u, k) in enumerate(zip(h.upsample_rates, h.upsample_kernel_sizes)):
self.ups.append(
weight_norm(
ConvTranspose1d(
h.upsample_initial_channel // (2**i),
h.upsample_initial_channel // (2 ** (i + 1)),
k,
u,
padding=(k - u) // 2,
)
)
)
self.resblocks = nn.ModuleList()
for i in range(len(self.ups)):
ch = h.upsample_initial_channel // (2 ** (i + 1))
for j, (k, d) in enumerate(
zip(h.resblock_kernel_sizes, h.resblock_dilation_sizes)
):
self.resblocks.append(resblock(h, ch, k, d))
self.conv_post = weight_norm(Conv1d(ch, 1, 7, 1, padding=3))
self.ups.apply(init_weights)
self.conv_post.apply(init_weights)
def forward(self, x):
x = self.conv_pre(x)
for i in range(self.num_upsamples):
x = F.leaky_relu(x, LRELU_SLOPE)
x = self.ups[i](x)
xs = None
for j in range(self.num_kernels):
if xs is None:
xs = self.resblocks[i * self.num_kernels + j](x)
else:
xs += self.resblocks[i * self.num_kernels + j](x)
x = xs / self.num_kernels
x = F.leaky_relu(x)
x = self.conv_post(x)
x = torch.tanh(x)
return x
def remove_weight_norm(self):
print('Removing weight norm...')
for l in self.ups:
remove_weight_norm(l)
for l in self.resblocks:
l.remove_weight_norm()
remove_weight_norm(self.conv_pre)
remove_weight_norm(self.conv_post)
inference.py系统推理文件
- 这部分是调用之前所有的模型,进行特定类别声音的生成。具体逻辑如下
- 加载vq-vae模型、pixelsnail模型和HiFi-GAN模型
- 声音推理,生成新的声音
from typing import List
from numpy import ndarray
from torch import Tensor
from abc import ABC, abstractmethod
import os
import argparse
import math
import time
import datetime
import torch
from tqdm import tqdm
import soundfile as sf
from vqvae import VQVAE
from pixelsnail import PixelSNAIL
from HiFiGanWrapper import HiFiGanWrapper
class SoundSynthesisModel(ABC):
@abstractmethod
def synthesize_sound(self, class_id: str, number_of_sounds: int) -> List[ndarray]:
raise NotImplementedError
class DCASE2023FoleySoundSynthesis:
def __init__(
self, number_of_synthesized_sound_per_class: int = 100, batch_size: int = 16
) -> None:
self.number_of_synthesized_sound_per_class: int = (
number_of_synthesized_sound_per_class
)
self.batch_size: int = batch_size
self.class_id_dict: dict = {
0: 'DogBark',
1: 'Footstep',
2: 'GunShot',
3: 'Keyboard',
4: 'MovingMotorVehicle',
5: 'Rain',
6: 'Sneeze_Cough',
}
self.sr: int = 22050
self.save_dir: str = "./synthesized"
def synthesize(self, synthesis_model: SoundSynthesisModel) -> None:
# 遍历所有声音类别
for sound_class_id in self.class_id_dict:
# 设置每一个类别合成的样本数量
sample_number: int = 1
# 设置每一个类别合成的样本保存路径
save_category_dir: str = (
f'{self.save_dir}/{self.class_id_dict[sound_class_id]}'
)
os.makedirs(save_category_dir, exist_ok=True)
# 开始合成
for _ in tqdm(
range(
math.ceil(
self.number_of_synthesized_sound_per_class / self.batch_size
)
),
desc=f"Synthesizing {self.class_id_dict[sound_class_id]}",
):
synthesized_sound_list: list = synthesis_model.synthesize_sound(
sound_class_id, self.batch_size
)
# 保存合成的声音为wav文件
for synthesized_sound in synthesized_sound_list:
if sample_number <= self.number_of_synthesized_sound_per_class:
sf.write(
f"{save_category_dir}/{str(sample_number).zfill(4)}.wav",
synthesized_sound,
samplerate=self.sr,
)
sample_number += 1
# ================================================================================================================================================
class BaseLineModel(SoundSynthesisModel):
def __init__(
self, pixel_snail_checkpoint: str, vqvae_snail_checkpoint: str
) -> None:
super().__init__()
# 加载pixelSNAIL模型,用来生成新的编码
self.pixel_snail = PixelSNAIL(
[20, 86],
512,
256,
5,
4,
4,
256,
dropout=0.1,
n_cond_res_block=3,
cond_res_channel=256,
)
self.pixel_snail.load_state_dict(
torch.load(pixel_snail_checkpoint, map_location='cpu')['model']
)
self.pixel_snail.cuda()
self.pixel_snail.eval()
# 加载vqvae模型,用来解码新的编码
self.vqvae = VQVAE()
self.vqvae.load_state_dict(
torch.load(vqvae_snail_checkpoint, map_location='cpu')
)
self.vqvae.cuda()
self.vqvae.eval()
self.hifi_gan = HiFiGanWrapper(
'./checkpoint/hifigan/g_00935000',
'checkpoint/hifigan/hifigan_config.json',
)
@torch.no_grad()
def synthesize_sound(self, class_id: str, number_of_sounds: int) -> List[ndarray]:
'''
合成声音的具体函数,输入类别id和需要合成的声音数量,返回合成的声音列表
:param class_id: 合成声音的类别编号
:param number_of_sounds: 合成声音的数量
:return:
'''
# 用来存储合成的声音
audio_list: List[ndarray] = list()
# 指定合成声音的特征的形状
feature_shape: list = [20, 86]
#一个零张量,其形状与feature_shape相匹配,用于存储由PixelSnail模型生成的令牌。
vq_token: Tensor = torch.zeros(
number_of_sounds, *feature_shape, dtype=torch.int64
).cuda()
cache = dict()
# 通过两个嵌套的循环,逐像素地生成vq_token。
for i in tqdm(range(feature_shape[0]), desc="pixel_snail"):
for j in range(feature_shape[1]):
# 使用PixelSnail模型生成下一个令牌的概率分布。
out, cache = self.pixel_snail(
vq_token[:, : i + 1, :],
label_condition=torch.full([number_of_sounds, 1], int(class_id))
.long()
.cuda(),
cache=cache,
)
# 对PixelSnail的输出应用softmax,得到下一个令牌的概率分布。
prob: Tensor = torch.softmax(out[:, :, i, j], 1)
# 从概率分布中采样一个令牌,并将其存储在vq_token中。
# 从当前行抽取一个令牌,然后将其存储在vq_token中。每一行选择一个
vq_token[:, i, j] = torch.multinomial(prob, 1).squeeze(-1)
# 音频解码
pred_mel = self.vqvae.decode_code(vq_token).detach()
# 通过HiFi-GAN模型生成音频
for j, mel in enumerate(pred_mel):
audio_list.append(self.hifi_gan.generate_audio_by_hifi_gan(mel))
return audio_list
# ===============================================================================================================================================
if __name__ == '__main__':
start = time.time()
parser = argparse.ArgumentParser()
parser.add_argument(
'--vqvae_checkpoint', type=str, default='./checkpoint/vqvae/vqvae.pth'
)
parser.add_argument(
'--pixelsnail_checkpoint',
type=str,
default='./checkpoint/pixelsnail-final/bottom_1400.pt',
)
parser.add_argument(
'--number_of_synthesized_sound_per_class', type=int, default=100
)
parser.add_argument('--batch_size', type=int, default=16)
args = parser.parse_args()
dcase_2023_foley_sound_synthesis = DCASE2023FoleySoundSynthesis(
args.number_of_synthesized_sound_per_class, args.batch_size
)
dcase_2023_foley_sound_synthesis.synthesize(
synthesis_model=BaseLineModel(args.pixelsnail_checkpoint, args.vqvae_checkpoint)
)
print(str(datetime.timedelta(seconds=time.time() - start)))
总结
- 这次算是完全复现了,加上对应的评测方法。这些代码算是第二次看了,有了很深的理解。

















 1125
1125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









