







OpenSmile介绍
- openSMILE(open-source Speech and Music Interpretation by Large-space Extraction)是一个开源工具包,用于语音和音乐信号的音频特征提取和分类。openSMILE广泛应用于情感计算的自动情感识别。openSMILE完全免费用于研究目的。
下载和安装
- 在下述网页下载opensmile的安装包,链接
- 然后进入“/home/public/gl/MultiDetection/alzheimers-dementia-master/opensmile-master/”
- 输入如下指令
bash build.sh
- 运行结果如下
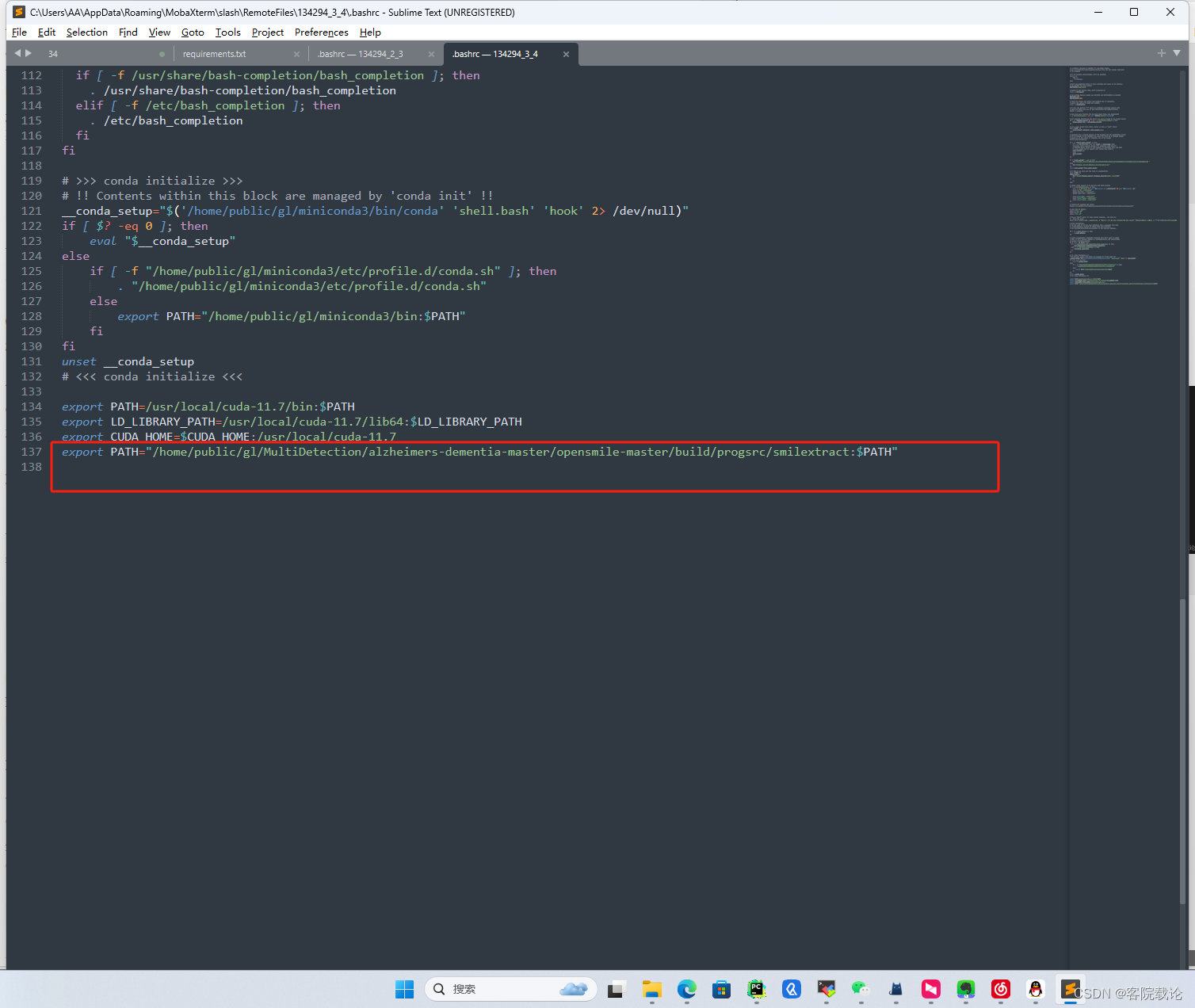
- 将这个二进制执行文件在环境路径中添加。
export PATH="/home/public/gl/MultiDetection/alzheimers-dementia-master/opensmile-master/build/progsrc/smilextract:$PATH"
- 使用如下指令进行设置测试,输出如下
SMILExtract -h
提取特征
格式转换
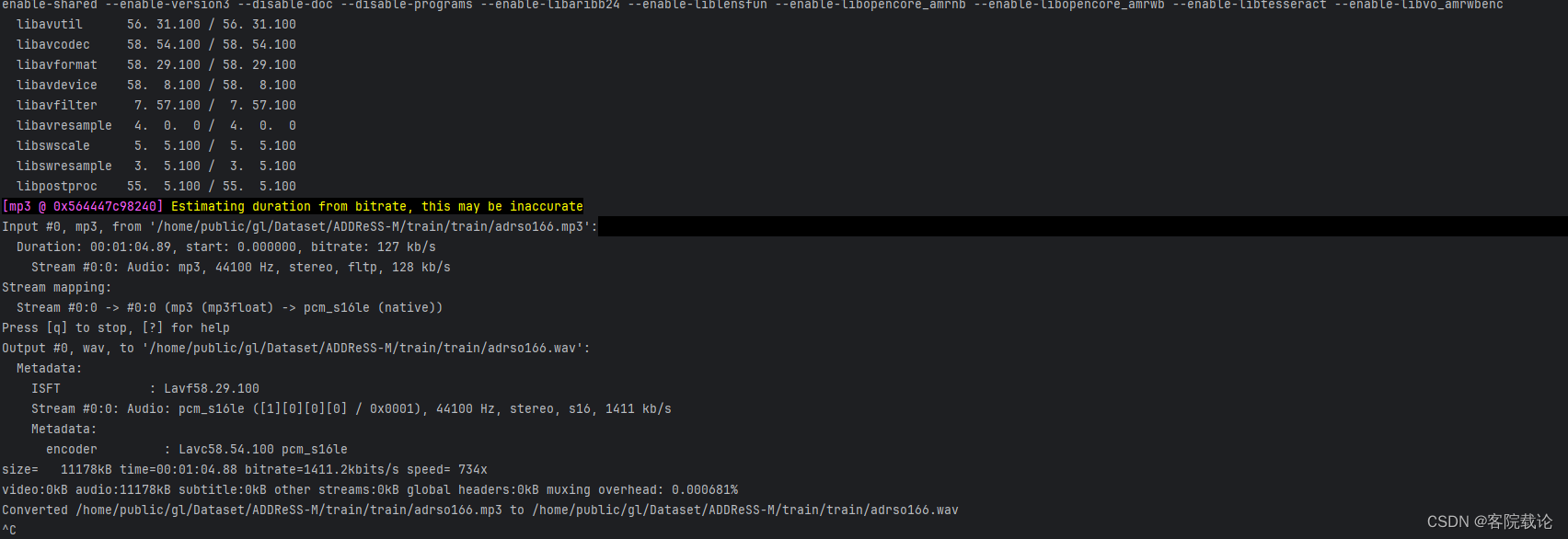
- 我需要处理的是mp3文件,而opensmile仅仅支持处理wav文件,所以这里需要将wav文件转为mp3文件
- 这里需要调用ffmpeg进行格式转换,对应的脚本如下
#!/bin/bash
# 定义搜索和转换的根目录
SEARCH_DIR="/home/public/gl/Dataset/ADDReSS-M/"
# 使用 find 命令查找所有的 .mp3 文件
# 然后使用 while 循环和 read 命令逐一处理它们
find "$SEARCH_DIR" -type f -name "*.mp3" | while IFS= read -r mp3file; do
# 使用参数替换来生成新的 .wav 文件名
wavfile="${mp3file%.mp3}.wav"
# 检查MP3文件是否存在
if [ ! -f "$mp3file" ]; then
echo "The file $mp3file does not exist, skipping."
continue
fi
# 调用 ffmpeg 进行转换
ffmpeg -i "$mp3file" "$wavfile" < /dev/null && echo "Converted $mp3file to $wavfile"
# 如果不需要保留原MP3文件,取消下面一行的注释
# rm "$mp3file"
done
echo "All MP3 files have been converted to WAV format."
- 输出效果如下
特征提取
尝试一
- 这里直接运行了下述脚本,遍历所有的wav文件,并将特征进行保存,脚本代码如下
#!/bin/bash
# openSMILE的配置文件路径
SMILE_CONFIG="/home/public/gl/MultiDetection/alzheimers-dementia-master/opensmile-master/config/is09-13/IS13_ComParE.conf"
# 原始数据集的根目录
SOURCE_DIR="/home/public/gl/Dataset/ADDReSS-M/"
# 特征文件保存的根目录
FEATURE_DIR="./ADDReSS-M_features"
# 创建特征文件的保存目录
mkdir -p "$FEATURE_DIR"
# 递归地查找所有的WAV文件
find "$SOURCE_DIR" -type f -name "*.wav" | while read -r wavfile; do
# 计算相对路径
relative_path="${wavfile#$SOURCE_DIR}"
# 获取不带扩展名的文件名
base_name="$(basename "$relative_path" .wav)"
# 获取不带文件名的目录路径
dir_path="$(dirname "$relative_path")"
# 在特征文件目录中创建相同的目录结构
mkdir -p "$FEATURE_DIR/$dir_path"
# 设置输出文件的完整路径
output_file="$FEATURE_DIR/${dir_path}/${base_name}.csv"
# 使用openSMILE处理WAV文件
SMILExtract -C "$SMILE_CONFIG" -I "$wavfile" -O "$output_file"
echo "Features extracted for $wavfile and saved to $output_file"
done
echo "Feature extraction complete for all WAV files."
- 输出结果如下
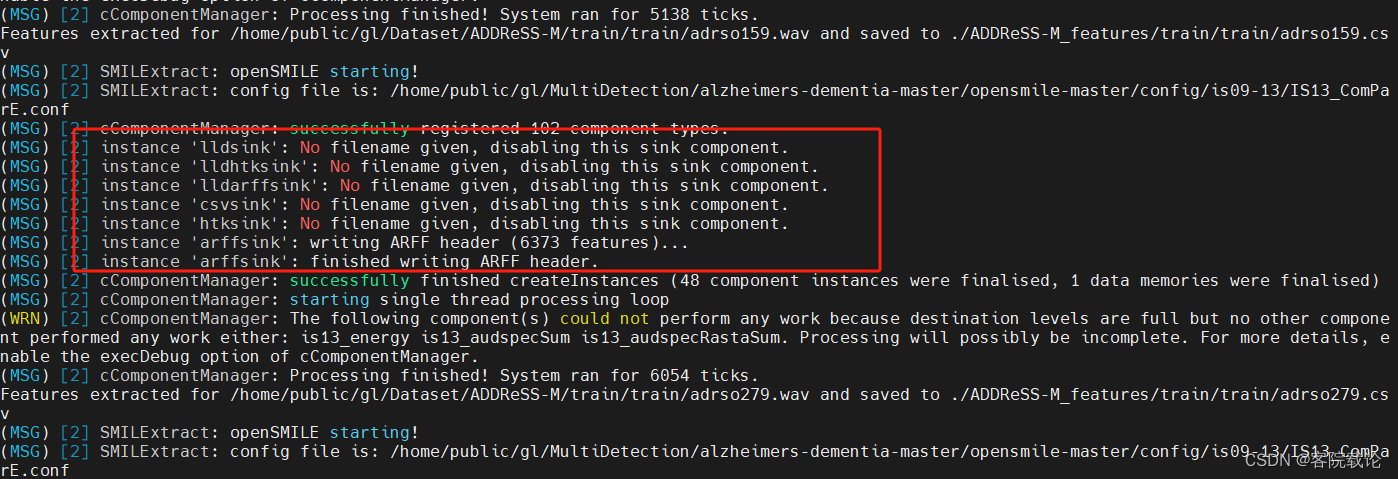
- 比较害怕及格diable对结果有什么影响,这里仔细地搜索相关资料进行学习
- 这个东西是用来设置输出文件样式的,如果我只需要csv的数据并不需要使用

- 这个东西是用来设置输出文件样式的,如果我只需要csv的数据并不需要使用
正常使用手段
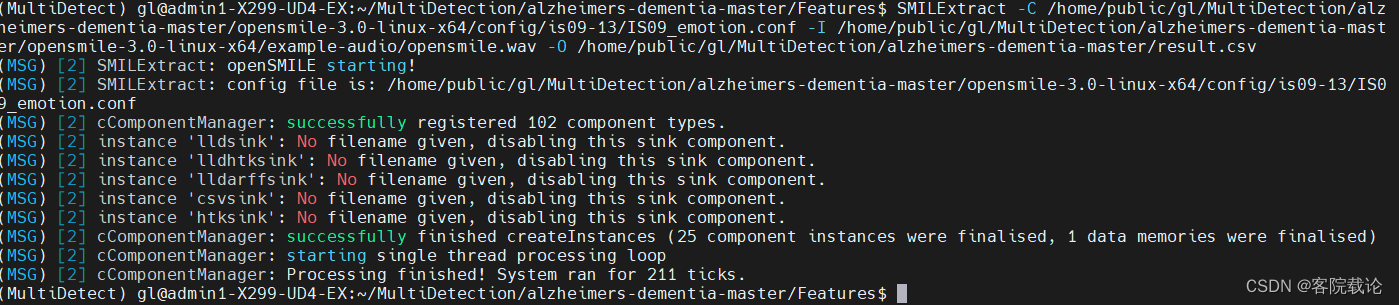
- 需要指定提取音频特征的配置文件、输入文件和输出文件,具体使用样例如下
SMILExtract -C config/demo/demo1_energy.conf(配置文件) -I example-audio/opensmile.wav(输入文件) -O opensmile.energy.csv(输出文件)
- 运行结果如下
- 仅仅收到了MSG,运行成功
- 收到ERROR表示提取失败
创建自己的配置文件
- 我们将使用此函数生成我们的第一个配置文件,该文件将能够读取波形文件、计算帧能量并将输出保存到 CSV 文件。
- 具体指令如下
SMILExtract -cfgFileTemplate -cfgFileDescriptions -configDflt cWaveSource,cFramer,cEnergy,cCsvSink -l 1 2> myconfig/demo1_descriptions.conf
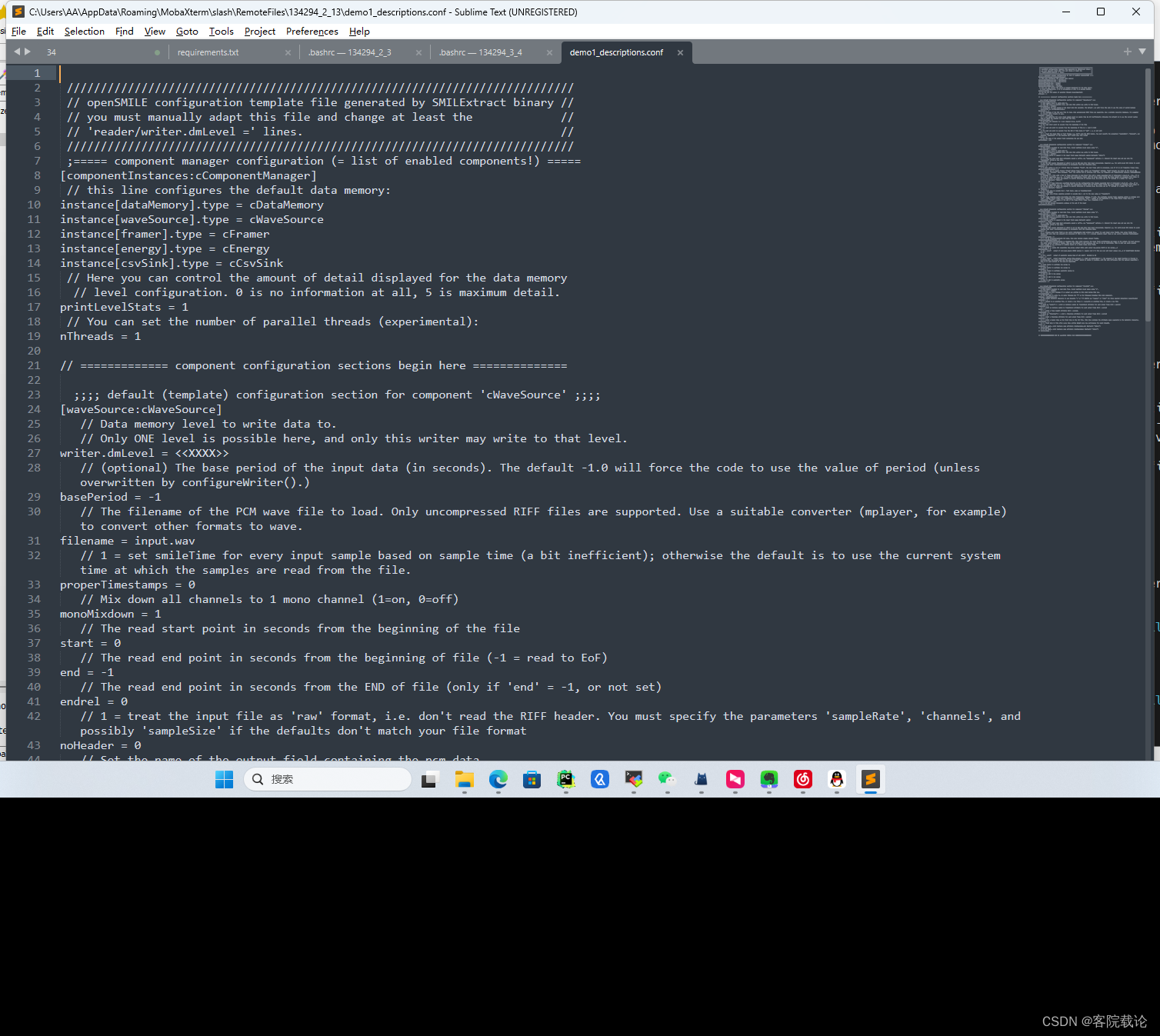
配置文件分析
- 第一部分是基本的配置
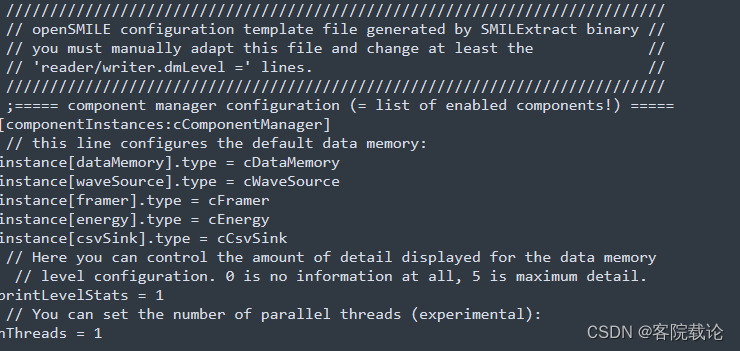
- 第二部分是当前配置文件所对应的不同的组件信息
- 可以在这里修改不同组件的参数,比如说每一帧的长度等
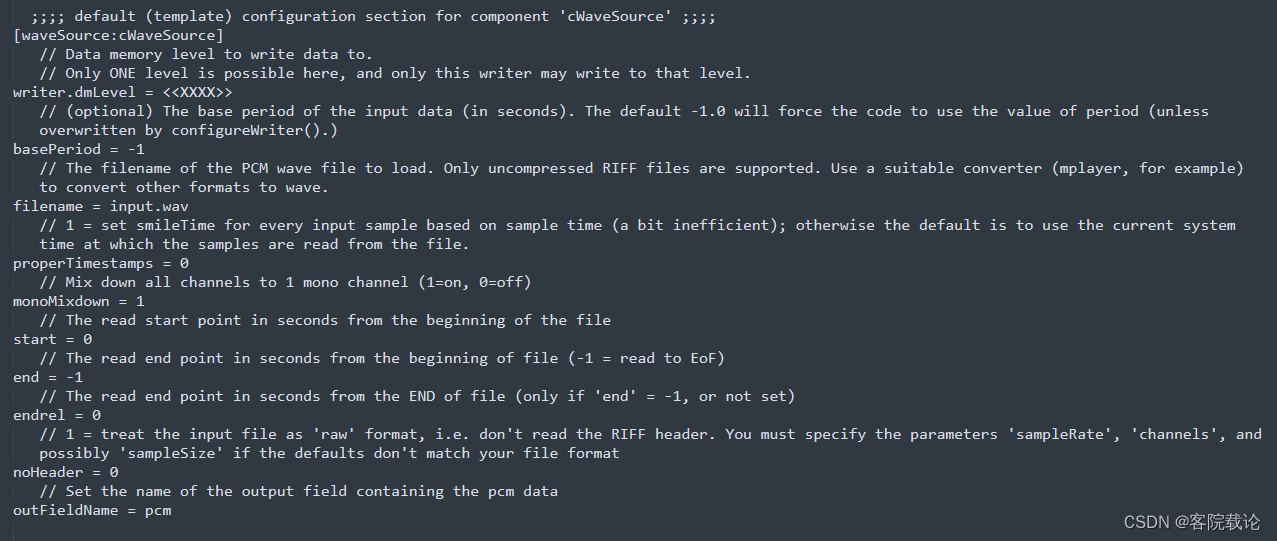
- 可以在这里修改不同组件的参数,比如说每一帧的长度等
常见的特征
-
Chroma features for key and chord recognition
用于键和和弦识别的色度功能 -
MFCC for speech recognition
用于语音识别的 MFCC -
PLP for speech recognition
用于语音识别的 PLP -
Prosody (Pitch and loudness)
韵律(音高和响度) -
The INTERSPEECH 2009 Emotion Challenge feature set
INTERSPEECH 2009 情感挑战赛功能集 -
The INTERSPEECH 2010 Paralinguistic Challenge feature set
INTERSPEECH 2010 副语言挑战赛功能集 -
The INTERSPEECH 2011 Speaker State Challenge feature set
INTERSPEECH 2011 Speaker State Challenge 功能集 -
The INTERSPEECH 2012 Speaker Trait Challenge feature set
INTERSPEECH 2012 Speaker Trait Challenge 功能集 -
The INTERSPEECH 2013 ComParE feature set
INTERSPEECH 2013 ComParE 功能集 -
The MediaEval 2012 TUM feature set for violent scenes detection.
用于暴力场景检测的 MediaEval 2012 TUM 功能集。 -
Three reference sets of features for emotion recognition (older sets, obsoleted by the new INTERSPEECH challenge sets)
用于情感识别的三个参考功能集(较旧的功能集,已被新的 INTERSPEECH 挑战集淘汰) -
Audio-visual features based on INTERSPEECH 2010 Paralinguistic Challenge audio features.
基于INTERSPEECH 2010副语言挑战赛音频特征的视听特征。 -
这里不同特征需要自己去了解,相关说明文档链接\
使用Gnuplot可视化特征
安装
- 为了使用 gnuplot 可视化特征轮廓,您必须安装 gnuplot 4.6 或更高版本。在 Linux 上,gnuplot 既可以通过发行版的包管理器安装(在 Ubuntu 上:), sudo apt-get install gnuplot-nox 也可以从源代码编译(http://www.gnuplot.info)。对于 Windows,gnuplot 二进制文件可从项目网页获得。
使用
- 这里需要写对应的plt脚本,然后调用gnuplot进行执行。具体就给了三个样例,分别是色度、频谱图还有响度曲线等,具体看官网就行。如果要自己画图,还是需要自己写的。
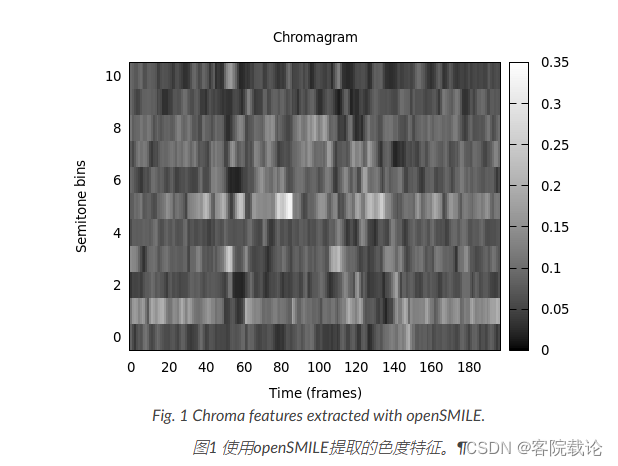
总结
- 关于音频特征,使用opensmile进行提取,还是挺快的,而且使用cpu就行,不需要使用gpu,下面就是尝试不同的音频特征就行。


















 1480
1480

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









