







 本文详细介绍如何使用Python爬虫抓取手机尺寸信息,通过数据清洗与解析,生成可用于机器学习的数据集。涵盖爬虫技术、数据处理及数据可视化的全过程。
本文详细介绍如何使用Python爬虫抓取手机尺寸信息,通过数据清洗与解析,生成可用于机器学习的数据集。涵盖爬虫技术、数据处理及数据可视化的全过程。
前言
机器学习很重要的一部分就是数据,因此可以通过爬虫爬取一些数据。爬取完数据之后,需要对数据进行清洗,使其成为能够被我们利用的数据集。这里我爬取了一个手机尺寸的网站,准备计算得到其高宽信息,并生成了一个数据集。后面会根据这个数据集进行一下分类操作。
当然现在如果把爬虫爬到的数据用于商业,现在很多时候是不合法的,还是要注意点。
准备工作
这里使用的是python 3.6进行实现的,需要安装如下一些库:
beautifulsoup4
requests
lxml
tensorflow
scikit-learn
pandas
matplotlib
这些库一部分是后面四个是用于分类的,可以先不下。我们这边就使用了requests+beautifulsoup+lxml爬取数据并进行结构分析。
主要工作
发送请求下载页面
可以直接解析页面,但保险起见还是先下载下来然后在进行处理比较好,不然重复请求别人的网页也不是很好也没什么必要,所以写了一个从txt中读取保存页面的函数。
因为有好几个页面,所以循环调用了好次,将页面都保存为txt文件。主要函数如下:
PAGES = ['index', 'pad', 'watch', 'computer', 'display']
def get_page_content_crawler(url, page_name):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36',
}
url = url % page_name
page_content = requests.get(url=url, headers=headers)
page_content.encoding = 'utf-8'
content = page_content.text
save_page_content2txt(content, page_name)
return content
except:
s = sys.exc_info()
print("Error '%s' happened on line %d" % (s[1], s[2].tb_lineno))
return "ERROR"
def get_page_content_from_txt(page_name):
with open('%s.txt' % page_name, 'r') as f:
html = f.read()
soup = BeautifulSoup(html, 'lxml') # 采用lxml进行解析
return soup
def save_page_content2txt(content, page_name):
with open('%s.txt' % page_name, 'w') as f:
for i in content:
f.write(i)
读取页面并解析
页面如下所示,是一个表格:
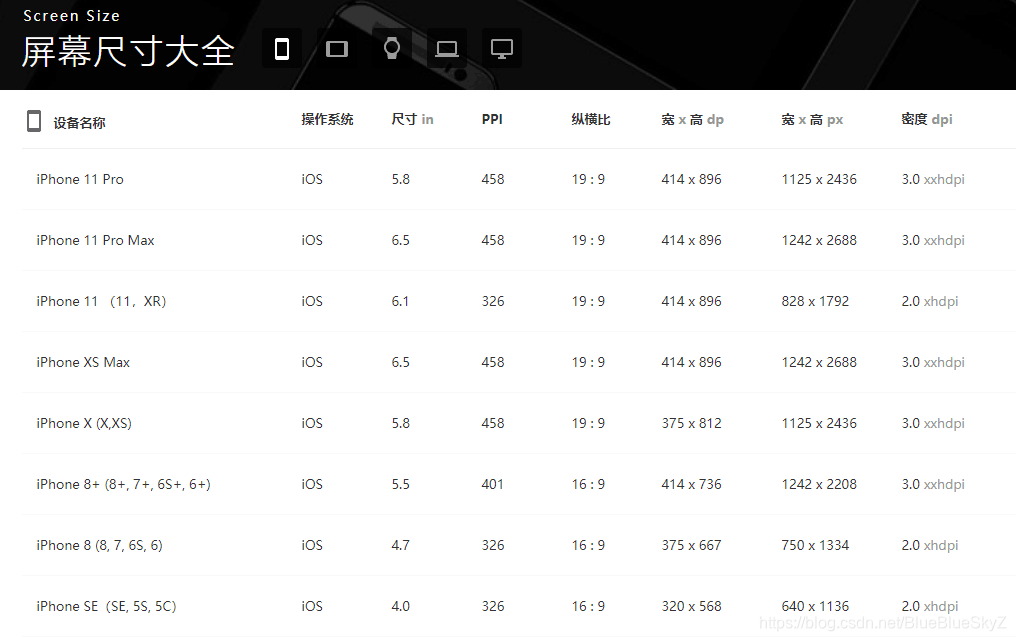
分析网页html的结构如下,可以发现有且仅有一个tbody,而每个设备的信息都是存在一个tr里面的,相关信息也是有对应的class。
<tbody>
<tr>
<td class="td01" valign="middle">iPhone 11 Pro</td>
<td class="td02" valign="middle">iOS</td>
<td class="td03" valign="middle">5.8</td>
<td class="td04" valign="middle">458</td>
<td class="td05" valign="middle">19 : 9</td>
<td class="td06" valign="middle">414 x 896</td>
<td class="td07" valign="middle">1125 x 2436</td>
<td class="td08" valign="middle">3.0
<font class="gray01">xxhdpi</font>
</td>
</tr>
......
因此撰写结构分析的代码:
def extract_content2excel(soup, page_name):
all_devices = soup.find('tbody')
one_device = all_devices.find_all_next('tr')
with open('%s.csv' % page_name, 'w') as f:
writer = csv.writer(f)
header = ['name', 'device_os', 'size', 'ppi', 'aspect_ratio', 'wh_dp', 'wh_px', 'dpi']
writer.writerow(header)
for device in one_device:
name = device.find('td', class_='td01').text
device_os = device.find('td', class_='td02').text.replace(' ', '')
size = device.find('td', class_='td03').text.replace(' ', '')
ppi = device.find('td', class_='td04').text.replace(' ', '')
aspect_ratio = device.find('td', class_='td05').text.replace(' ', '')
wh_dp = device.find('td', class_='td06').text.replace(' ', '')
wh_px = device.find('td', class_='td07').text.replace(' ', '')
dpi = device.find('td', class_='td08').text.replace(' ', '').replace('\n', '')
content = [name, device_os, size, ppi, aspect_ratio, wh_dp, wh_px, dpi]
writer.writerow(content)
将其中一些空格去除,然后存入一个csv文件中,多个页面会有多个文件。
生成数据集
整合多个csv文件
csv文件是以逗号为分割符的,有多种方式可以读取。爬取的数据如下,我们可以知道手机屏幕是多少吋,一般是指对角线的长度,而1寸=2.54厘米,因此可以根据尺寸和纵横比计算手机的高和宽。
name,device_os,size,ppi,aspect_ratio,wh_dp,wh_px,dpi
iPhone 11 Pro,iOS,5.8,458,19:9,414x896,1125x2436,3.0xxhdpi
iPhone 11 Pro Max,iOS,6.5,458,19:9,414x896,1242x2688,3.0xxhdpi
iPhone 11 (11,XR),iOS,6.1,326,19:9,414x896,828x1792,2.0xhdpi
iPhone XS Max,iOS,6.5,458,19:9,414x896,1242x2688,3.0xxhdpi
.......
这里取第三列和第五列的数据即可,根据上面的公式计算得到高和宽:
def read_csv(page_name):
'''
读取csv中的数据
:param page_name:文件的名称
:return: np格式的str list(name, height, width)
'''
with open('%s.csv' % page_name, 'r', encoding='UTF-8') as f:
f_csv = csv.reader(f)
header = next(f_csv) # 忽略表头
device_info = np.empty([0, 3])
for r in f_csv:
if r[2][0] == '-' or r[4][0] == '-': # 清洗数据
continue
height, width = get_wh_from_size(r[2], r[4])
one_device = (r[0], height, width) # 这里会导致height和width转化成str
device_info = np.row_stack((device_info, one_device))
return device_info
def get_wh_from_size(size, aspect_ratio):
'''
解析csv文件中的数据
:param size: 手机尺寸(吋表示对角线)
:param aspect_ratio: 纵横比
:return: 高、宽(单位已经转化为cm)
'''
ratio = map(float, aspect_ratio.split(':'))
height_ratio, width_ratio = list(ratio)
hypotenuse_ratio = math.sqrt(height_ratio**2 + width_ratio**2)
hypotenuse_cm = float(size) * 2.54
height = round((height_ratio * hypotenuse_cm / hypotenuse_ratio), 2)
width = round((width_ratio * hypotenuse_cm / hypotenuse_ratio), 2)
return height, width
可视化并保存数据集
使用添加的方式将每一行保存到data.csv中,这里写的不算特别好,因为每次添加一行都进行了一次文件打开的操作,有点消耗内存,可以考虑所有的存储为array再打开文件。
def draw_scatter():
# 拼接三个数据
devices = []
for page in PAGE:
device_info = read_csv(page)
devices.append(device_info)
all_data = []
for device in devices:
point = (device.T[1], device.T[2])
all_data.append(point)
groups = ('phone', 'pad', 'PC')
colors = ('red', 'blue', 'green')
# Create plot
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
for data, color, group in zip(all_data, colors, groups):
x, y = data
print(group, "的数量是:", len(x))
index = groups.index(group)
save_data_csv(index, list(x.T), list(y.T))
print(x.shape, y.shape)
x = list(map(np.float32, x))
y = list(map(np.float32, y))
ax.scatter(x, y, alpha=1, c=color, edgecolors='none', s=30, label=group)
ax.axis('auto')
plt.title('Device Size Scatter')
plt.legend(loc=2)
plt.xlabel('height')
plt.ylabel('width')
plt.show()
def save_data_csv(label, *paras):
# 添加,newline使得新行无回车
with open('data.csv', 'a+', newline='') as f:
writer = csv.writer(f)
if label == 0:
writer.writerow(['height', 'width', 'label'])
paras = np.array(paras).T
for item in paras:
content = []
for para in item:
content.append(para)
content.append(label)
writer.writerow(content)
最终的数据分布如下:
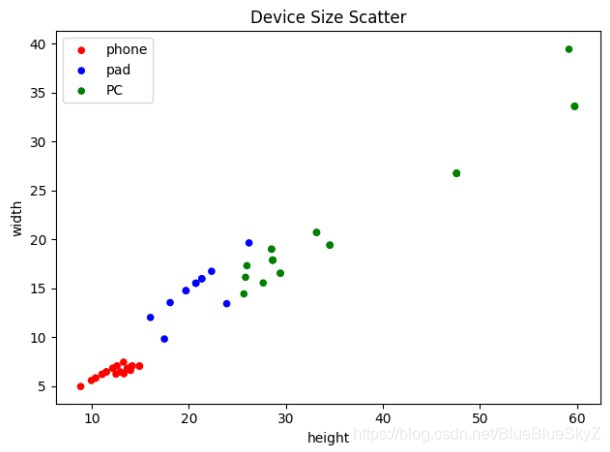
数据格式如下,分为三列进行了保存:
height,width,label
13.31,6.31,0
14.92,7.07,0
14.0,6.63,0
14.92,7.07,0
...
20.73,15.54,1
16.05,12.04,1
21.34,16.0,1
...
25.85,16.15,2
25.68,14.45,2
28.65,17.9,2
完成数据集制作之后我们就可以随意进行操作了。
参考链接
- https://www.jianshu.com/p/47908cd4f424
- https://uiiiuiii.com/screen

















 770
770

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









