









目录
参考
SpringCloud之链路追踪Sleuth与Zipkin集成
一、前言
当一个分布式系统服务多了之后,前端访问接口可能涉及到多个服务调用链路
随着服务的越来越多,对调用链的分析会越来越复杂
当前端访问接口出现问题的时候,我们如何快速定位是哪个服务出现故障比较麻烦
链路追踪的出现正是为了解决这种问题。
二、Spring Cloud Sleuth
概述
Spring Cloud Sleuth 是Spring Cloud 实现了分布式链路跟踪解决方案。分布式链路追踪(Distributed Tracing),就是将一次分布式请求还原成调用链路,进行日志记录,性能监控并将一次分布式请求的调用情况集中展示。比如各个服务节点上的耗时、请求具体到达哪台机器上、每个服务节点的请求状态等等。
Sleuth 提供了以下功能:
- 链路追踪:通过 Sleuth 可以很清楚的看出一个请求都经过了那些服务,可以很方便的理清服务间的调用关系等。
- 性能分析:通过 Sleuth 可以很方便的看出每个采样请求的耗时,分析哪些服务调用比较耗时,当服务调用的耗时随着请求量的增大而增大时, 可以对服务的扩容提供一定的提醒。
- 数据分析:对于频繁调用一个服务,或并行调用等,可以针对业务做一些优化措施。
- 可视化错误:对于程序未捕获的异常,可以配合 Zipkin 查看。
Sleuth主要由三部分组成:Span、Trace、Annotation;
-
Trace: 由一组Trace Id相同的Span串联形成一个树状结构。为了实现请求跟踪,当请求到达分布式系统的入口端点时,只需要服务跟踪框架为该请求创建一个唯一的标识(即TraceId),同时在分布式系统内部流转的时候,框架始终保持传递该唯一值,直到整个请求的返回。那么我们就可以使用该唯一标识将所有的请求串联起来,形成一条完整的请求链路。
-
Span: 代表了一组基本的工作单元。为了统计各处理单元的延迟,当请求到达各个服务组件的时候,也通过一个唯一标识(SpanId)来标记它的开始、具体过程和结束。通过SpanId的开始和结
束时间戳,就能统计该span的调用时间,除此之外,我们还可以获取如事件的名称。请求信息等
元数据。 -
Annotation: 用它记录一段时间内的事件,内部使用的重要注释:
cs(Client Send)客户端发出请求,开始一个请求的生命
sr(Server Received)服务端接受到请求开始进行处理, sr-cs = 网络延迟(服务调用的时间)
ss(Server Send)服务端处理完毕准备发送到客户端,ss - sr = 服务器上的请求处理时间
cr(Client Reveived)客户端接受到服务端的响应,请求结束。 cr - sr = 请求的总时间
实现原理
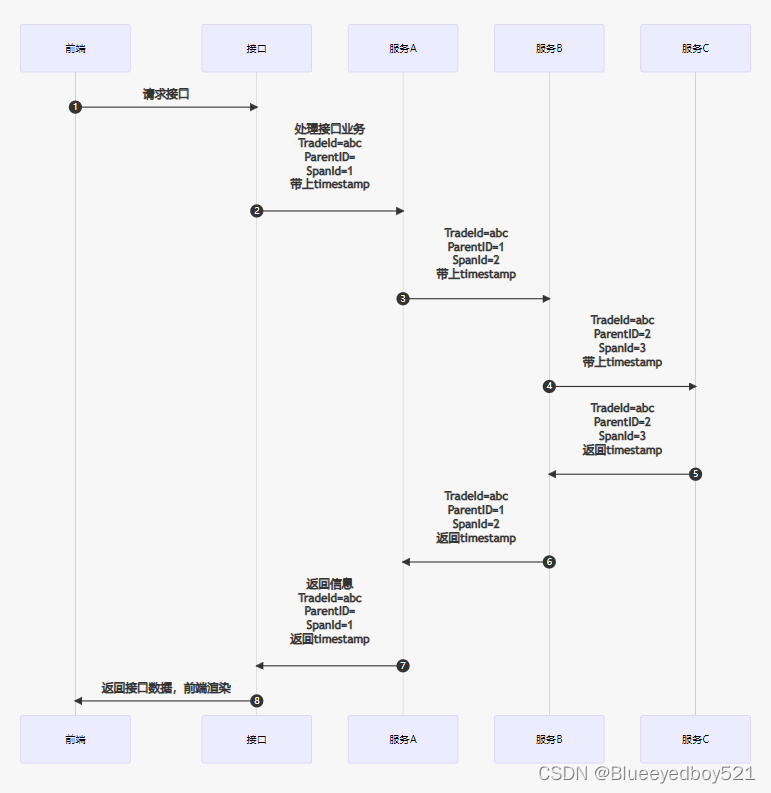
我们可以在代码中看到TradeId与SpanId,如下图
我们模拟了服务 A -> B -> C 的调用链路,分别产生的日志如下:
2021-09-21 02:18:36.494 DEBUG [a-service,14aa6f21d700f377,14aa6f21d700f377,true] 40619 --- [nio-7000-exec-7] org.apache.tomcat.util.http.Parameters : Set encoding to UTF-8
2021-09-21 02:18:36.524 DEBUG [b-service,14aa6f21d700f377,828df12c1c851367,true] 40622 --- [nio-8000-exec-6] org.apache.tomcat.util.http.Parameters : Set encoding to UTF-8
2021-09-21 02:18:36.571 DEBUG [c-service,14aa6f21d700f377,ebd9892f8756801d,true] 40626 --- [nio-9000-exec-7] org.apache.tomcat.util.http.Parameters : Set encoding to UTF-8
可以发现,按调用时间先后顺序分别是 A 到 C 依次出现。因为是一次完整业务处理,TraceId 都是相同的,SpanId 却各不相同,这些日志都已经被 Sleuth 导出,正常被 ZipKin 收集展示。
三、Zipkin
zipkin是一款开源的分布式实时数据追踪系统(Distributed Tracking System),基于 Google Dapper的论文设计而来,由 Twitter 公司开发贡献。
它有助于收集对服务架构中的延迟问题进行故障排除所需的计时数据。功能包括收集和查找这些数据。
1、zipkin核心组成
- Collector:收集器组件
它主要用于处理从外部系统发送过来的跟踪信息,将这些信息转换为Zipkin内部处理的Span格式,以支持后续的存储、分析、展示等功能。 - Storage:存储组件
它主要对处理收集器接收到的跟踪信息,默认会将这些信息存储在内存中,我们也可以修改此存储策略,通过使用其他存储组件将跟踪信息存储到 数据库或es 中。 - RESTful API:API组件
它主要用来提供外部访问接口。比如给客户端展示跟踪信息,或是外接系统访问以实现监控等。 - Web UI:UI组件
基于API组件实现的上层应用。通过UI组件用户可以方便而有直观地查询和分析跟踪信息。

- Zipkin 分为两端,一个是 Zipkin 服务端,一个是 Zipkin 客户端
- 客户端也就是微服务的应用,客户端会配置服务端的 URL 地址
- 一旦发生服务间的调用的时候,会被配置在微服务里面的 Sleuth 的监听器监听,并生成相应的 Trace 和 Span 信息发送给服务端。
- 发送的方式有两种:1、消息总线如:(ACTIVEMQ、RABBIT、KAFKA)、2、HTTP的方式
2、sleuth与zipkin的关系
Sleuth已经将每个请求从开始调用到完成的每一步都进行了记录, 但是这些log信息会很分散,使用起来不太方便,就需要有一个工具可以将这些信息进行收集和汇总,并且显示可视化的结果,便于分析和定位。
sleuth的作用是在系统中自动埋点并把数据发送给zipkin,zipkin的作用是存储这些数据并展现。
四、搭建环境
1、搭建Zipkin单机环境
Github源码地址:https://github.com/openzipkin/zipkin
最快的入门方法是获取最新发布的服务器可执行 jar。请注意,Zipkin 服务器需要最低 JRE 8。
Jar下载地址:https://search.maven.org/remote_content?g=io.zipkin&a=zipkin-server&v=LATEST&c=exec
1.1、配置数据库
zipkin数据默认存储在内存中的,如果重启了数据就没有了
可以把数据存在第三方工具中,如:mysql、elasticsearch、等
存储到MySQL
创建数据库,并导入初始化sql脚本
初始化sql脚本在:https://github.com/openzipkin/zipkin/blob/master/zipkin-storage/mysql-v1/src/main/resources/mysql.sql
注意:
数据库只能是5.7否则报错如下
org.mariadb.jdbc.internal.com.send.authentication.SendGssApiAuthPacket could not be instantiated
引用Provider org.mariadb.jdbc.internal.com.send.authentication.SendGssApiAuthPacket could not be instantiated · Issue #3372 · openzipkin/zipkin · GitHub
The problem has been solved. The solution is that my mysql version is 8.0, and the program runs normally after switching to 5.7. Thank you very much for your reply
1.2、docker启动镜像
#获取镜像
docker pull openzipkin/zipkin
#简易运⾏镜像
docker run -d -p 9411:9411 --name zipkin --net=mynet openzipkin/zipkin
# 配置mysql
docker run -d --name zipkin \
--net=mynet \
-p 9411:9411 \
-e STORAGE_TYPE=mysql \
-e MYSQL_HOST=mysql \
-e MYSQL_TCP_PORT=3306 \
-e MYSQL_DB=zipkin \
-e MYSQL_USER=demo \
-e MYSQL_PASS=123456 openzipkin/zipkin
# 完整配置
docker run -d --name zipkin -p 9411:9411 -e zipkin.collector.rabbitmq.addresses=Rabbitmq的IP地址 -e zipkin.collector.rabbitmq.username=guest -e zipkin.collector.rabbitmq.password=guest -e STORAGE_TYPE=mysql -e MYSQL_HOST=Mysql 的IP地址 -e MYSQL_TCP_PORT=3306 -e MYSQL_DB=zipkin -e MYSQL_USER=root -e MYSQL_PASS=123456 openzipkin/zipkin
访问:http://192.168.0.44:9411/zipkin/
1.3、jar包方式启动
# wget 下载jar包,并重命名为:zipkin.jar
wget -O zipkin.jar 'https://search.maven.org/remote_content?g=io.zipkin&a=zipkin-server&v=LATEST&c=exec'
# 上面是下载,下面这个也是,官方的快速执行脚本,其实也是下载和上面差不多。
# curl -sSL https://zipkin.io/quickstart.sh | bash -s
# 启动zipkin
java -jar zipkin.jar
1.4、以ES的方式启动zipkin。
# 我设置ES_INDEX_SHARDS 分片,发现并没有效果,默认是5个主分片,每个分片1个副本分片
# 设置用户与密码:ES_USERNAME、ES_PASSWORD
# 还有其他的选项可以参考Github链接:https://github.com/openzipkin/zipkin/tree/master/zipkin-server#elasticsearch-storage
# java -jar zipkin-server-2.23.2-exec.jar --STORAGE_TYPE=elasticsearch --ES_INDEX_SHARDS=3 --ES_INDEX_REPLICAS=1 --ES_HOSTS=http://127.0.0.1:9400,http://127.0.0.1:9500,http://127.0.0.1:9600
# 最终我直接以这样运行了,我就试了ES_INDEX_SHARDS、ES_INDEX_REPLICAS 这两个参数
# 不知道为什么不生效,所以我启动的时候就没加了
# ES_HOSTS 我试了只填一个IP也可以,写集群的所有IP也可以
java -jar zipkin-server-2.23.2-exec.jar --STORAGE_TYPE=elasticsearch --ES_HOSTS=http://127.0.0.1:9400
最后ES自动生成索引zipkin-span-当天日期
2、引入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin</artifactId>
</dependency>
3、添加配置信息
server:
port: 30003
spring:
cloud:
nacos:
# 注册中心
discovery:
server-addr: http://NACOS地址:8848
# 配置中心
config:
server-addr: ${spring.cloud.nacos.discovery.server-addr}
file-extension: yaml
shared-configs[0]:
data-id: ams-common.yaml
refresh: true
application:
name: demo-c
sleuth:
sampler: #采样器
probability: 1 #采样率,采样率是采集Trace的比率,默认0.1
rate: 10000 #每秒数据采集量,最多n条/秒Trace
zipkin:
sender:
type: web #Spring Cloud Sleuth 针对 Web 组件的配置项,例如说 SpringMVC
service:
name: ${spring.application.name}
base-url: http://zipkin:9411/ #设置zipkin服务端地址
注意配置项:
- spring.sleuth.sampler.probability 是指采样率,假设在过去的 1 秒服务产生了 10 个 Trace,如果采用默认采样率 0.1 则代表只有其中1条会被发送到 Zipkin 服务端进行分析整理,如果设为 1,则 10 条 Trace 都会被发送到服务端进行处理。
- spring.sleuth.sampler.rate 指每秒最多采集量,说明每条最多允许采集多少条 Trace,超出部分将直接抛弃。
4、调用获取token接口
edevp-auth日志如下:
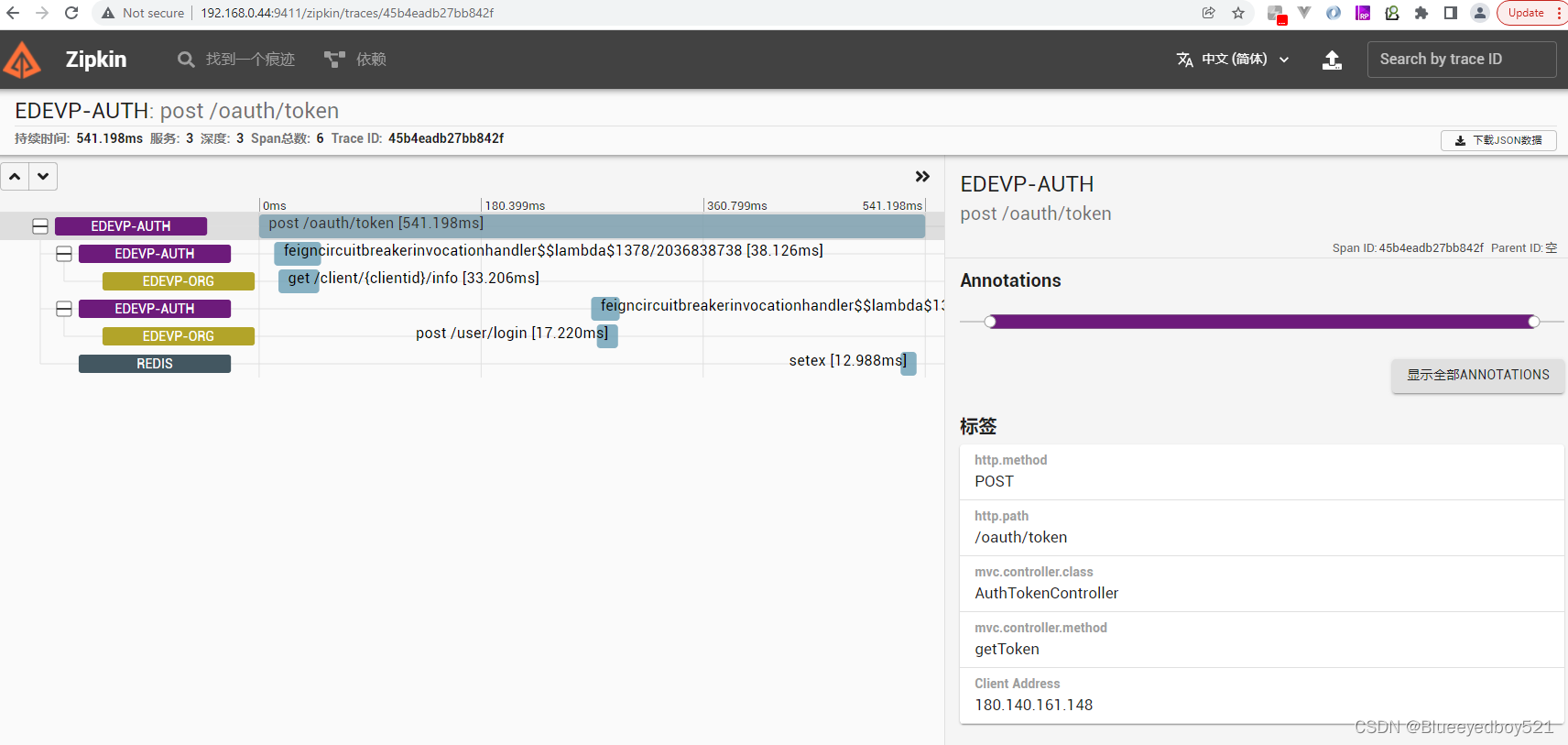
2022-08-24 10:55:45.493 INFO [edevp-auth,2c2e17e072ccb7d1,2c2e17e072ccb7d1] 26212 --- [nio-8201-exec-1] [180.140.161.148] POST:/oauth/token [未知] c.e.c.security.web.AuthTokenController : 调动feign获取客户端id:pc
然后打开 Zipkin 服务端 UI 界面 http://192.168.0.44:9411,查看调用链路。
如果点击对应的“依赖”,还可以看到更详细的拓扑关系内容。
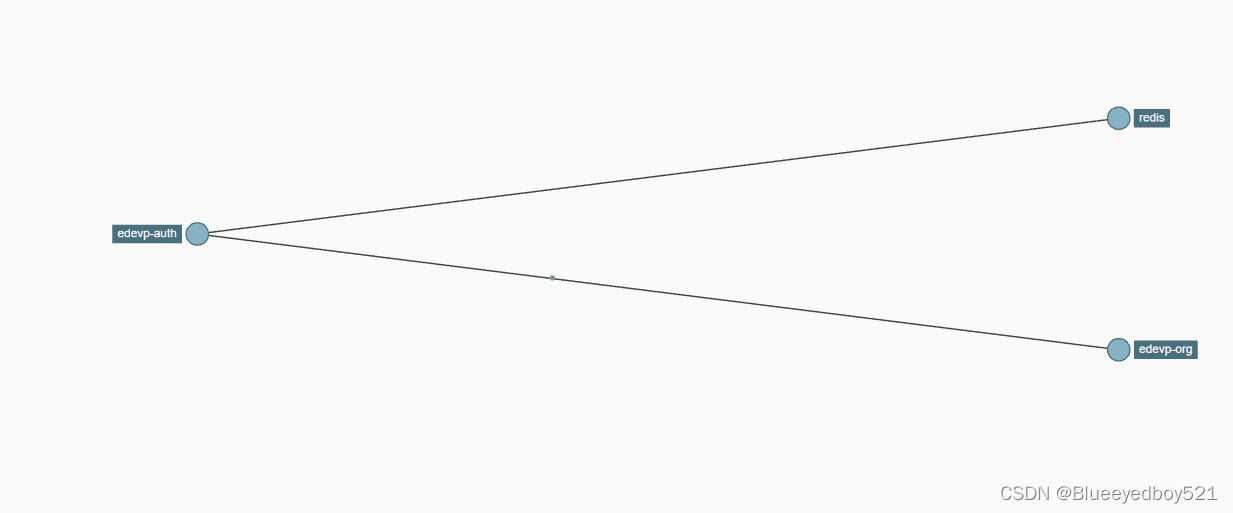
如果我们主动停掉服务edevp-org 呢,会是什么样的情况呢?
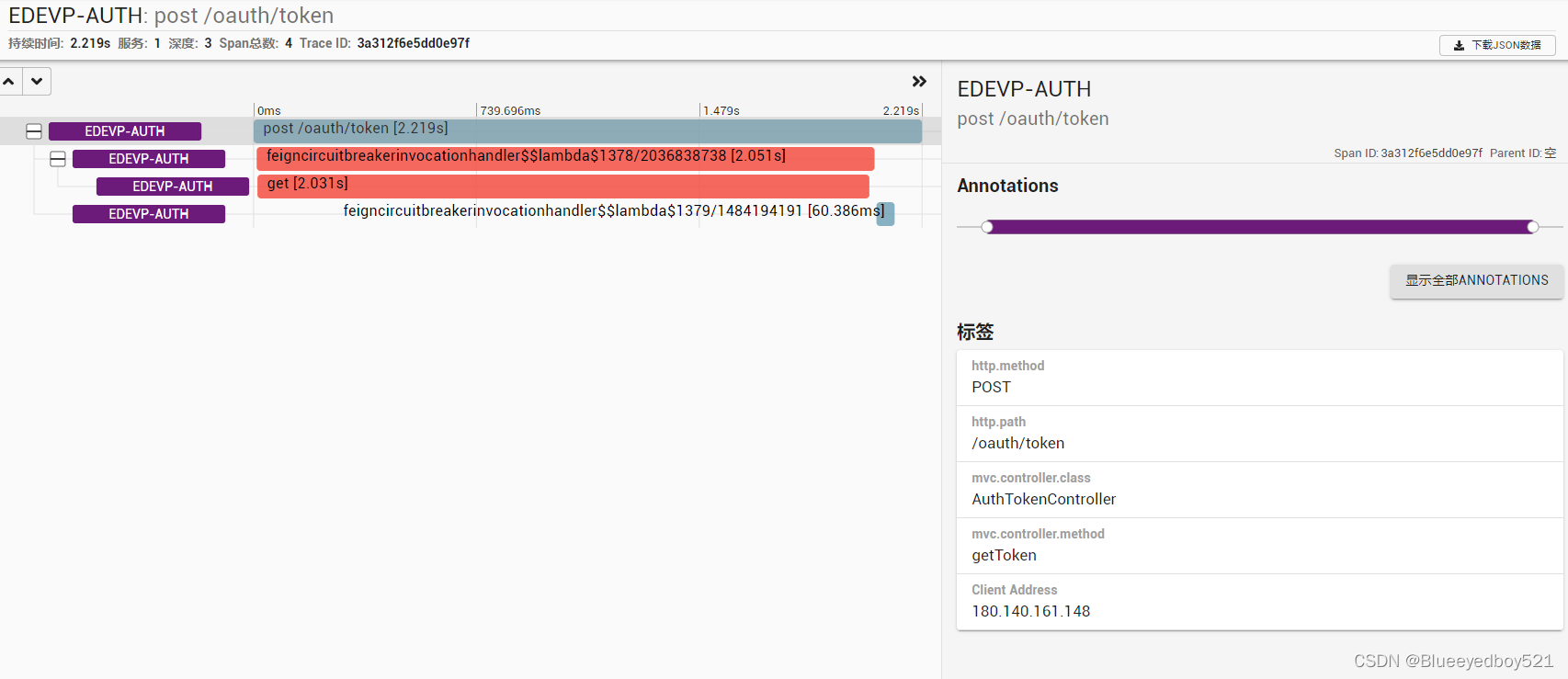
我们可以看到 Zipkin 已经在 error 里面提示故障原因了,说明服务 edevp-org 没有可用的实例导致处理失败。
















 2039
2039











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









