









问题描述:
曾经用简单的深度优先搜索方法、递归的形式对马踏棋盘进行搜索,运行效率不甚理想。(博客见马踏棋盘之递归实现)。
所以现在用贪心算法将其优化了一下。
问题解析:
主要的思想没有变,还是用深度优先搜索,只是在选下一个结点的时候做了贪心算法优化,其思路如下:
从起始点开始,根据“马”的走法,它的下一步的可选择数是有0—8个的。
我们知道,当下一步的可选择数为0的时候,进行回溯。当下一步的可选择数有1个的时候,我们直接取那一步就行了。但是如果下一步的可选择数有多个的时候呢?
在上一篇博客中,我们是任意取一个的,只要它在棋盘内,且未遍历就可以了。
但其实我们怎么选下一步,对搜索的效率影响是非常大的!
先介绍一下“贪心算法”。百科里面的定义是:贪心算法(又称贪婪算法),是指在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,他所做出的仅是在某种意义上的局部最优解。它只考虑局部的最优,从而让总体也最优。就我们这个马踏棋盘来说,我们每走一步都取最优的那个选择,从而让整体的算法也最优。
但是我们选择下一步的时候(假设有a、b、c、d四个点可以选择),怎样选才算是最优呢?
答案是:哪一个点的下一步少,就选哪一个。
我们选择a、b、c、d之中的某一个点作为下一步,选哪个比较好,就看哪个点的后续下一步比较少。例如:马走到a点后的下一步有3个选择;而b的下一步有2个;c有1个,d有2个。那么我们的最优选择是:c点!
为什么要这样选呢?网上的解释是:“选择最难走的路,才能走的远”呜。。。好像太抽象了。
我的理解是:有些选择的后续下一步很少,例如c点,如果不先遍历它的话以后可能会很难遍历到它。
甚至极端一点的情况是,如果现在不遍历它,以后都遍历不到了。遍历不成功的时候只能回溯,一直回溯到此刻的点,然后选了c点以后才能完成,这就浪费了大量的时间。
下面放出所有代码,详细的解释后面再补上:
<pre name="code" class="cpp">#include<stdio.h>
#include<time.h>
#define H 3 // 代表对下一步的排序只取出最小的2个,而不是对8个都排序,这样可以节省很多时间
int fx[8] = {-2,-1,1,2,2,1,-1,-2}, fy[8] = {1,2,2,1,-1,-2,-2,-1}, f[8] = {-15,-6,10,17,15,6,-10,-17};
// fx[] 和 fy[] 表示马在二维的八个方向,给二维坐标x和y用;f[]表示一维的八个方向,给数组a用。
int dep = 1; // dep 为递归的深度,代表在当前位置马已经走了多少步
int count, z = 0, zz = 0; // count 表示目标要多少种解法,而 z 记录当前算出了多少种解法,zz 记录在运算中回溯的次数
int out[100001][8][8], F[8], a[64]; // out[][][] 记录所有的遍历路径,a[] 用一维数组记录 8*8 棋盘中马的遍历路径
// 输入起始坐标,对存放遍历路径的数组a进行初始化
int Prepare()
{
int i, j, n;
printf("请输入起始点的坐标:\n");
printf("x=");
scanf("%d", &i);
printf("\by=");
scanf("%d", &j);
printf("你要的解的数目count=");
scanf("%d", &count);
n = i * 8 + j - 9; // 将起始点的二维坐标 x、y 转化成一维坐标 n ,从而方便数组 a[64] 的路径记录
for(i = 0; i<64; i++) // a[64] 存放在 8*8 方格中马的遍历路径,搜索之前先进行清零初始化
a[i] = 0;
a[n] = 1;
return n;
}
// Sortint() 函数对点 n 的下一步进行“后续下一步可选择数”的排序,结果保存在 b[][] 里面
// c 表示前驱结点在结点 n 的哪个位置。
void Sorting(int b[64][H], int n, int c)
{
int i, j, x, y, m1, m2, k, k1, l=1, xx, yy;
if(c != -1)
c = (c + 8 - 4) % 8;
for(i=0; i<8; i++) //对于当前节点的八个方向
{
F[i] = -1; //F记录八个方向的下一步的再下一步有多少个
m1 = n + f[i];
x = n / 8 + fx[i];
y = n % 8 + fy[i]; //这是下一步的坐标
if(c!=i && x>=0 && x<8 && y>=0 && y<8 && a[m1]==0) //如果下一步存在
{
F[i]++;
for(j=0; j<8; j++) //对于下一步的八个方向
{
m2 = m1 + f[j];
xx = x + fx[j];
yy = y + fy[j]; //这是再下一步的坐标
if(xx>=0 && xx<8 && yy>=0 && yy<8 && a[m2]==0) //如果再下一步存在
F[i]++;
}
}
}
b[n][0] = -1;
for(i=1; i<H; i++)
{
k = 9;
for(j=0; j<8; j++)
{
if(F[j]>-1 && F[j]<k)
{
k = F[j];
k1 = j;
}
}
if(k < 9)
{
b[n][l++] = k1;
F[k1] = -1;
b[n][0] = 1;
}
else
{
b[n][l++] = -1;
break;
}
}
}
// 搜索遍历路径
void Running(int n)
{
int i, j, k;
int b[64][H], s[64]; // b[][] 用来存放下一步的所有后续结点排序
s[0] = n;
Sorting(b, n, -1);
while(dep >= 0)
{
if(b[n][0]!=-1 && b[n][0]<H && b[n][b[n][0]]!=-1)
{
k = b[n][b[n][0]];
b[n][0]++;
n += f[k];
Sorting(b, n, k);
a[n] = ++dep;
s[dep-1] = n;
if(dep == 64)
{
for(i=0; i<8; i++)
for(j=0; j<8; j++)
out[z][i][j] = a[i*8+j];
z++;
if(z == count)
{
printf("\n完成!!\n");
printf("回溯的次数:%d\n", zz);
break;
}
}
}
else
{
dep--;
zz++;
a[n] = 0;
n = s[dep-1];
}
}
}
// 输出所有的遍历路径
void Output()
{
int i, j, k;
printf("\n\n输入'1'展示详细遍历,输入'0'退出程序:");
scanf("%d", &count);
if(count)
{
for(i=0; i<z; i++)
{
printf("第%d个解:\n", i+1);
for(j=0; j<8; j++)
{
for(k=0; k<8; k++)
printf("%3d", out[i][j][k]);
printf("\n");
}
}
}
}
void main()
{
int n;
double start,finish;
n = Prepare();
start = clock();
Running(n);
finish = clock();
printf("运行时间:%.3f秒\n",(finish-start)/1000);
Output();
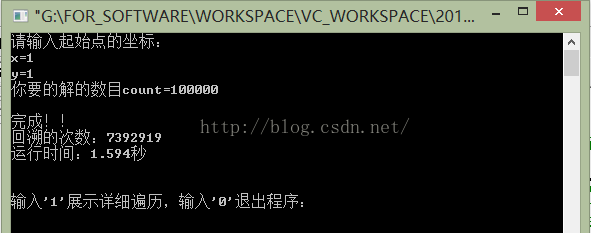
} 运行结果如下(VC6.0、32位win8系统 + i7-3612QM处理器,如果使用VS时间会长一点):
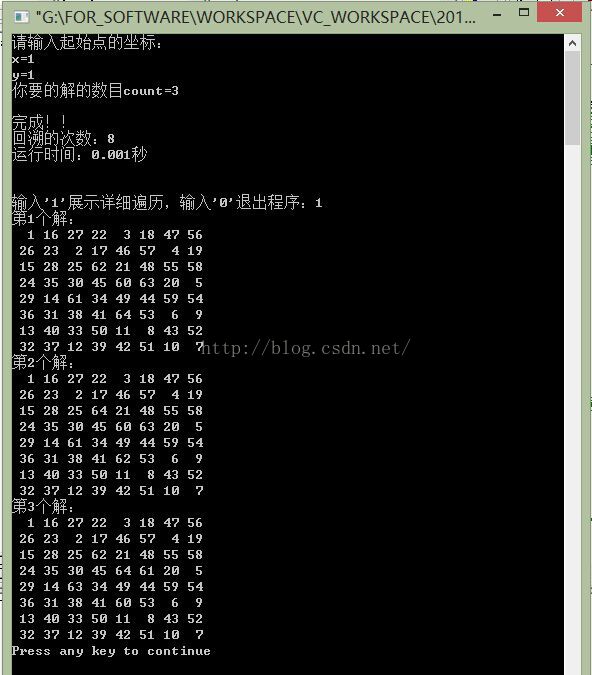
测试了一下:十万条路径,耗时1秒多!!!效率比普通的深度优先搜索不知道高了多少倍!
备注:
以上代码是四个月前写的,现在才整理出来。打击很大,当初不注意代码的格式和备注,现在看自己写的代码看到头晕脑炸,自食其果!以后必须注重写代码的风格,注意写上必须的备注,连自己写的代码的看不懂,真真可笑。一直看了好久终于看明白各个函数 各个变量的作用了,也改了一些格式,写了一些备注,到现在正的看不下去了。先把文章放出来,缓一阵再回来完善。
转载请注明出处,谢谢!(原文链接:http://blog.csdn.net/bone_ace/article/details/41579957)

















 438
438

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









