







并查集
岛问题

实现infected过程:
遍历,发现1的话就把该1及其相连的所有1都变成2,遍历过程中发现0和2就跳过
时间复杂度O(n*m)
大的循环每个调用一次
感染过程最多被调用四次
class Solution {
public int numIslands(char[][] grid) {
if(grid==null||grid.length==0||grid[0].length==0){
return 0;
}
int n=grid.length;
int m=grid[0].length;
int res=0;
for(int i=0;i<n;i++){
for(int j=0;j<m;j++){
if(grid[i][j]=='1'){
res++;
infect(grid,i,j,n,m);
}
}
}
return res;
}
public void infect(char[][] grid,int i,int j,int n,int m){
if(i<0||j<0||i>=n||j>=m||grid[i][j]!='1'){//base case
return;
}
grid[i][j]='2';//key point 不会死循环的原因:一上来就把当前位置改成2
infect(grid,i+1,j,n,m);
infect(grid,i-1,j,n,m);
infect(grid,i,j+1,n,m);
infect(grid,i,j-1,n,m);
}
}
进阶:如何设计一个并行算法解决这个问题
可能会出现在大公司的面试场景中
一般的算法都是单线程
假设现在这个题目的二维数组特别大,需要用到并行算法,怎么解决
思路:先假设两个cpu,怎样比一个cpu快
把二维数组分成两块可能会导致岛的数量变多
把分开的边界上的 被感染的点标记,如果两个cpu处理的数据边界上能连起来,则使用并查集union,并使岛的总数量-1
现在的设计当然比一个cpu快,数据量大量减少+一个cpu整合一下边界即可
多个cpu同理:分块并分别收集四个边界信息,相邻的合并即可

引入并查集
两个操作:isSameSet、union
传统的方式速度没法做到很快
- 链表的形式能快速做到union(O(1)),但isSameSet慢
- 哈希表isSameSet快(O(1)),但union慢
并查集要解决的问题:如何将两个操作都实现时间复杂度为O(1)
往上指的图结构
isSameSet:向上找直到不能再找,看最终结果是否一样
union:数量少的顶部连在数量多的顶部
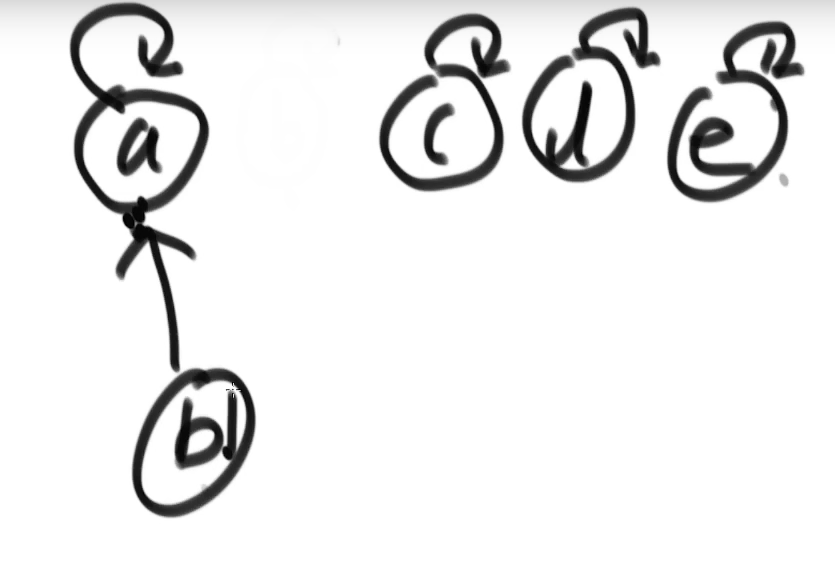
并查集的瓶颈在于向上找的过程链过长
向上找的过程可以优化
向上找的过程将链变成扁平化的,直接指向头节点
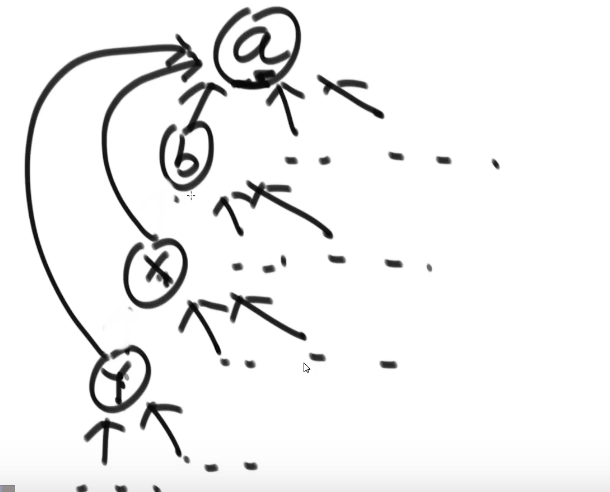
//样本进来会包一层,叫做元素
//包一层的目的是一个样本可能有多个数据
public class Element<V>{
public V value;
public Element(V value){
this.value=value;
}
}
public class UnionFindSet<V>{
public HashMap<V,Element<V>> elementMap;//a->a圈 b->b圈
public HashMap<Element<V>,Element<V>> fatherMap;//value为key的父节点
public HashMap<Element<V>,Integer> sizeMap;//key代表某个集合的代表元素,value表示该集合的大小
//并查集初始化的时候需要样本
public UnionFindSet(List<V> list){
elementMap=new HashMap<>();
fatherMap=new HashMap<>();
sizeMap=new HashMap<>();
for(V value:list){
Element<V> element=new Element<V>(value);
elementMap.put(value,element);
fatherMap.put(element,element);//一开始fa
sizeMap.put(element,1);
}
}
public boolean isSameSet(V a,V b){
if(elementMap.containsKey(a)&&elementMap.containsKey(b)){//保证a和b在并查集中注册过
return findHead(elementMap.get(a))==findHead(elementMap.get(b));
}
return false;
}
//找头节点
public Element<V> findHead(Element<V> element){
Stack<Element<V> path=new Stack<>();//这里不一定要用栈,用一个容器装起来就可以了
while(element!=fatherMap.get(element)){
path.push(element);
element=fatherMap.get(element);
}
while(!path.isEmpty()){//优化
fatherMap.put(path.pop(),element);
}
return element;
}
public void union(V a,V b){
if(elementMap.containsKey(a)&&elementMap.containsKey(b)){
Element<V> aFather=findHead(elementMap.get(a));
Element<V> bFather=findHead(elementMap.get(b));
if(aFather!=bFather){
Element<V> big=sizeMap.get(aFather)>=sizeMap.get(bFather)?aFather:bFather;
Element<V> small=big==aFather?bFather:aFather;
fatherMap.put(small,big);//数量较少的顶端挂在数量较多的顶端下面
sizeMap.put(big,sizeMap.get(aFather)+sizeMap.get(bFather));//sizeMap update
sizeMap.remove(small);//sizeMap delete
}
}
}
}















 225
225











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









