







目录
写在开头
近期准备重学操作系统,感觉还是有很多细节的知识点有必要掌握。上篇文章主要讲解了进程的创建与并发关系,详情见:
【操作系统】以fork()为例详解进程的创建过程与父子进程关系-CSDN博客
本文将在上一篇博客的基础上,讨论操作系统能够进行计算调度的最小单位——线程的创建与并发问题。 线程是进程的具体执行流,是进程的实际执行单位,一个进程中可以包含多个线程以实现并发。本文将通过一些C语言代码实验说明线程的创建方式、并发执行、内存共享情况。并以蒙特卡洛法估算pi(3.14159265...)值为例,体会多线程的在多核编程的时间优势。
本文主要基于杨一涛老师的操作系统教程,许多展示理论的图片都源于该课程。杨老师对于操作系统的讲解深入浅出,很适合初学者学习(唯一的缺点可能就是课程的录制稍显粗糙,屏闪严重),教程详见:
【操作系统原理】考研 408 必备,坚持看完两集,学不会找 up 主_哔哩哔哩_bilibili
1.线程的创建
在C语言中,可以通过pthread库中的pthread_create函数创建线程,下面我们编写一个非常简单的C语言代码实现线程的创建,代码helloThread.c如下:
#include <sys/types.h>
#include <unistd.h>
#include <stdio.h>
#include <pthread.h>
// define thread func
void* threadFunc(void* arg){
printf("In new thread\n");
}
int main(){
pthread_t tid;
// create thread func
pthread_create(&tid, NULL, threadFunc, NULL);
// waiting for specified thread ending
pthread_join(tid, NULL);
printf("In main thread\n");
return 0;
}
下面对这段代码进行讲解:
- 函数threadFuc就是创建的线程要执行的函数,传递参数类型和返回值都是void*指针。这个实验里我们的操作特别简单,就是打印一句"In new thread"即可,并不需要针对传递参数,也没有返回值。
- main函数中首先定义了线程号tid,其数据类型是pthread_t,这个数据类型和进程号的pid_t类型,本质都是int,只不过在sys/types.h中进行了重新封装。
- pthread_create函数用于创建线程,有四个参数,第一个参数是线程号的地址,也就是&tid,第二个参数是线程的属性地址(thread attribute address),这里不用管直接填写NULL即可。第三个参数是要执行的任务地址,也就是该线程要执行的函数的地址,我们要让线程执行threadFunc,于是就填写这个函数名(函数名也就是地址),第四个参数是传递给函数的参数所在的地址,由于此处我们无需传递任何参数,因此填写NULL即可。
- pthread_join函数用于等待指定的线程结束,如果不添加这个,主线程不会等待子线程结束,一旦主线程结束,子线程也会挂掉。该函数有两个参数,第一个是线程的ID号,第二个参数是一个用户定义的指针,用来存储被等待线程的返回值,由于此处没有返回值,填写NULL即可。
然后代码写好后编译为可执行文件helloThread,其中-l参数用来指定程序要链接的pthread库:
gcc helloThread.c -o helloThread -l pthread这里我试了一下,我的kali好像不用加-l pthread也能正常编译,可能是编译器做了优化吧。编译好后运行即可:

main函数和threadFunc中都输出的对应内容,而且貌似是执行了子线程threadFunc,然后主线程才输出了In main thread。
2.主线程与子线程的结束顺序
pthread_join( )函数,以阻塞的方式等待thread指定的线程结束。当函数返回时,被等待线程的资源被收回。如果线程已经结束,那么该函数会立即返回。如果此处我们将pthread_join函数注释掉,则主线程不会等待子线程结束,为了保证子线程执行的慢一点,我们可以在函数threadFunc中加个sleep,代码helloThread1.c如下:
#include <sys/types.h>
#include <unistd.h>
#include <stdio.h>
#include <pthread.h>
// define thread func
void* threadFunc(void* arg){
sleep(1);
printf("In new thread\n");
}
int main(){
pthread_t tid;
// create thread func
pthread_create(&tid, NULL, threadFunc, NULL);
// waiting for specified thread ending
// pthread_join(tid, NULL);
printf("In main thread\n");
return 0;
}如代码所示,此时主线程main不会等待子线程threadFunc执行完成才结束,会在threadFunc执行sleep的时候,主线程就结束了,因此子线程也就不复存在,不会输出"In new thread"了。将上述代码编译运行helloThread1如下:

3.线程之间的数据共享与并发执行
接下来我们创建多个线程,理解多个线程之间的并发执行关系,并通过对一个全局变量的操作反应线程之间的数据段共享的特点,代码helloThreads2如下:
#include <sys/types.h>
#include <unistd.h>
#include <stdio.h>
#include <pthread.h>
// global var
int value = 100;
// define thread func
void* hello(void* arg){
for (int i = 0; i < 3; ++i){
printf("Hello! (%d)\n", value++);
sleep(1);
}
}
void* world(void* arg){
for (int i = 0; i < 3; ++i){
printf("World! (%d)\n", value++);
sleep(2);
}
}
int main(){
pthread_t tid1, tid2;
// create thread func
pthread_create(&tid1, NULL, hello, NULL);
pthread_create(&tid2, NULL, world, NULL);
// waiting for specified thread ending
pthread_join(tid1, NULL);
pthread_join(tid2, NULL);
printf("In main thread! value = %d\n", value);
return 0;
}
这段代码首先定义了一个全局变量value,然后定义了两个子线程hello和world,函数hello会输出hello,同时修改并打印value的值,函数world则输出world,也会修改并打印value的值,我们在两个函数(两个线程)中添加了sleep,延长代码的执行时间,期望能看到并发的效果,编译后输出的结果如下:
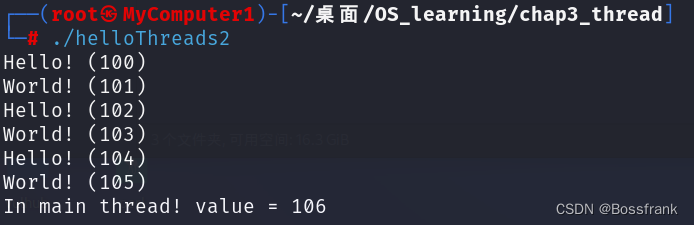
可以看到两点:首先,字符串Hello和World是交替打印的,并不是打印完3个Hello才打印World,体现了多线程的并发关系。同时也可以看到,value的值是不断+1的,也就是说主线程和tid1,tid2是共享同一个value的。这是因为全局变量会存储在数据data段,而对于一个进程的多个线程,其data段是共享的,如下图:

像全局变量、静态变量这种存储在data段的数据,会被一个进程中的多个线程共享,而如果每个线程中定义了局部变量,则局部变量会存储在栈中,每个线程的栈是分别的,不会共享,因此局部变量是不会共享的。
读者也可以回忆一下我的上一篇博客,对于进程的fork(),内存是完全独立不共享的,这里就体现出了线程比进程更节省内存资源,同时线程间通信也比进程间通信容易得多(线程可通过共享的内存传递信息)。
4.蒙特卡洛法求pi(单线程)
原理非常简单,如下图:
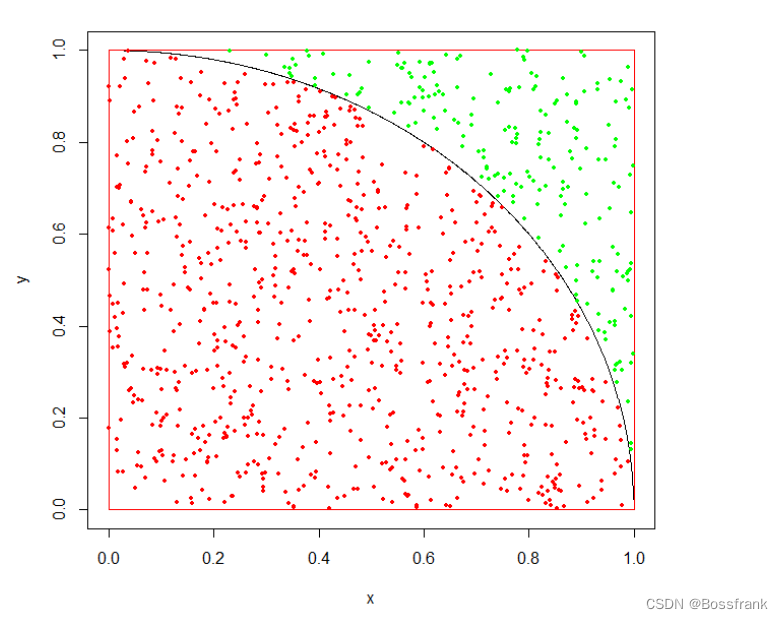
简单理解就是在1*1面积的方块上随机撒很多很多的点,则pi值近似为4*(扇形内的点数/总点数)。MonteCarlo2.c代码如下:
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
#include <pthread.h>
#include <stdlib.h>
#include <time.h>
double calculate_pi(int intervals){
unsigned int seed = time(NULL);
int circle_points = 0;
int square_points = 0;
double pi;
for (int i = 0; i < intervals*intervals; ++i){
double rand_x = (double)rand()/RAND_MAX; //随机在x方向确定坐标,范围[0,1]
double rand_y = (double)rand()/RAND_MAX;
if ((rand_x*rand_x + rand_y*rand_y) < 1)
{
circle_points++; //处在扇形内部的点数
}
square_points++; //所有的点数
}
pi = (double)(4.0*circle_points)/square_points; //估算pi值,注意数据类型转换
printf("circle_points: %d, square_points: %d, The estimated PI is: %lf\n",\
circle_points, square_points, pi);
return pi;
}
int main(){
clock_t start, delta; // 计算用时
start = clock(); //起始时间
#pragma omp parallel for num_threads(10)
for (int i=0; i<10; ++i){ //进行十次蒙特卡洛模拟,每次随机撒的点数不同
calculate_pi(1000*(i+1));
}
delta = clock() - start; //用时=当前时间-起始时间
printf("The time taken in total: %lf seconds\n", (double)delta/CLOCKS_PER_SEC);
return 0;
}这段代码没啥好讲的,就是定义了个函数calculate_pi用于估计pi值,参数intervals的平方是撒点的个数。主函数对calculate_pi函数调用了10次。运行结果如下:
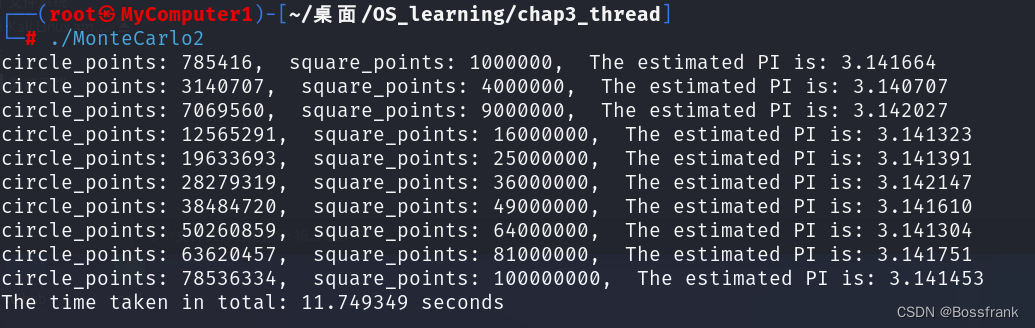
大概总用时是11.75s。 注意此处我们是单线程,并没有用pthread_create创造多线程模拟,接下来我们将使用多线程,并对结果进行对比。
5.蒙特卡洛法求pi(多线程)
这里我们把上一段代码改进为多线程的形式,理解多线程在多核下的时间优势。修改后的代码MonteCarlo3.c如下:
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
#include <pthread.h>
#include <stdlib.h>
#include <time.h>
void* calculate_pi(void* arg){
unsigned int seed = time(NULL);
int circle_points = 0;
int square_points = 0;
int intervals = *((int*)arg); //How to pass the arguments?
double pi;
for (int i = 0; i < intervals*intervals; ++i){
double rand_x = (double)rand_r(&seed)/RAND_MAX;
double rand_y = (double)rand_r(&seed)/RAND_MAX;
if ((rand_x*rand_x + rand_y*rand_y) < 1)
{
circle_points++;
}
square_points++;
}
pi = (double)(4.0*circle_points)/square_points;
printf("circle_points: %d, square_points: %d, The estimated PI is: %lf\n",\
circle_points, square_points, pi);
pthread_exit(0); //相当于return 0;
}
int main(){
clock_t start, delta;
double time_used;
start = clock();
pthread_t calculate_pi_threads[10]; //tid array
int args[10]; //thread parameters array
for (int i=0; i<10; ++i){ //多线程的创建方法
args[i] = 1000*(i+1);
pthread_create(calculate_pi_threads+i, NULL, calculate_pi, args+i);
}
for (int i=0; i<10; ++i){ //等待子线程结束
pthread_join(calculate_pi_threads[i], NULL);
}
delta = clock() - start;
printf("The time taken in total: %lf seconds\n", (double)delta/CLOCKS_PER_SEC);
return 0;
}
注意看主函数中,我们定义了线程编号tid的数组calculate_pi_threads[10],还定义了传递的参数args[i],通过10次pthread_create()函数创建10个不同的线程分别模拟蒙塔卡罗。
- pthread_create()函数的第一个参数是tid的地址,也就是每个数组元素calculate_pi_threads[i]的地址,即calculate_pi_threads+i,第二个参数是NULL,第三个参数传递要执行的函数地址,也就是函数calculate_pi,最后一个参数是给函数calculate_pi传递的参数的地址,也就是args[i]的地址args+i。
- 这里顺便提一下函数calculate_pi的传参方式,函数体中有一行int intervals = *((int*)args);,由于arg本身是void类型的指针,而intervals是一个整型,因此要先将void类型的指针通过强制类型转换(int*)转换为int型的指针,即(int*)args是个int 型的指针,再通过*即可取出指针指向的值,换句话说,*((int*)args)就是个整型的数。
- 最后再执行10次pthread_join( )函数,以阻塞的方式等待thread指定的线程(calculate_pi)结束,传递的参数就是tid本身calculate_pi_thread[i]和NULL。
另外顺道一提,这里用了rand_r函数,此处不能用rand()函数,因为如果用rand函数,所有的线程会共用一个随机数生成器,多线程就白搭了。不过这不是本文重点,读者有兴趣可以自己查一下rand()和rand_r()的区别。
我们运行这个编译后的代码MonteCarlo3,并输出运行时间:
gcc MonteCarlo3.c -o MonteCarlo3 -l pthread
time ./MonteCarlo3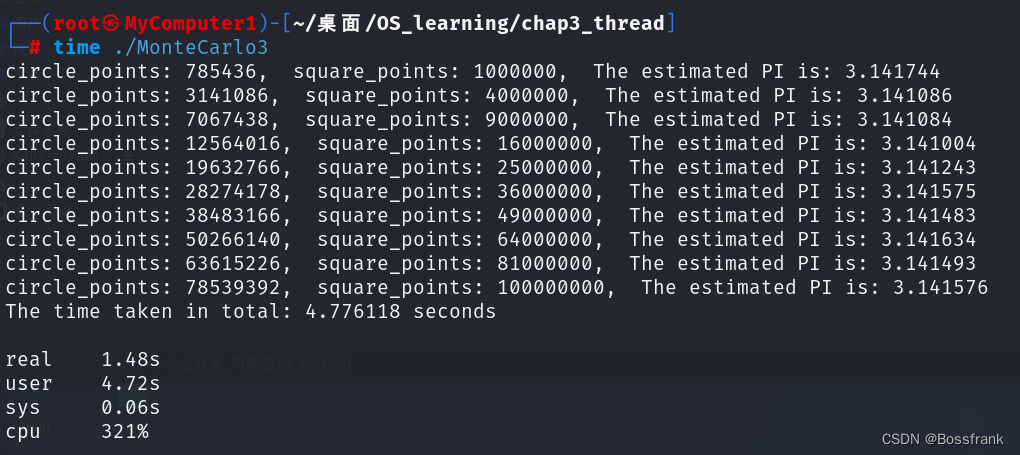
我的虚拟机是4核心的,如下图:
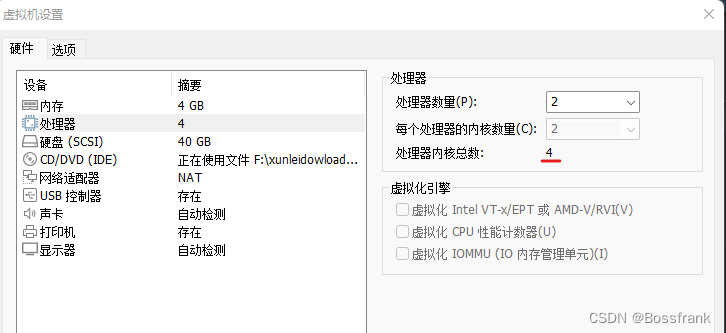
对于我这个4核心的CPU,可以发现程序结束的很快,大概只要1.5s程序就结束了,time工具可以显示这个进程的运行情况。real表示程序运行的真实时间,user表示在用户态运行的时间(所有的线程运行时间之和),sys表示了内核态的执行时间,往往是内核切换的一些开销,多线程的开销会大一些。如果我们运行上一节单线程蒙塔卡罗的代码,结果如下:
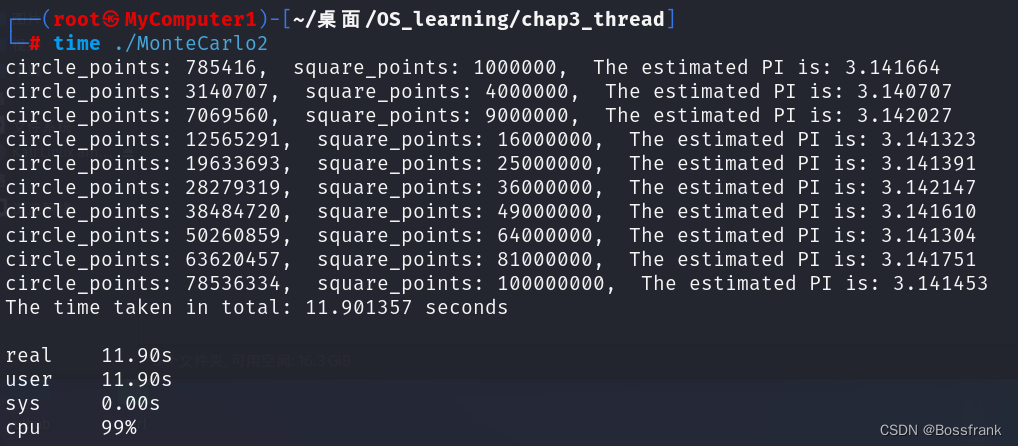
可看到在单线程模式下,真实时间基本就是用户态的时间,内核的时间基本上就是0。对比两种情况,总结一个表格如下:
| 单线程(单核) | 多线程(4核) | |
|---|---|---|
| 运行时间 | 11.9s | 1.48 |
| 用户态时间 | 11.9s | 4.72 |
| 内核态时间 | 0s | 0.06s |
| CPU利用率 | 99% | 321% |
多线程的运行时间明显小于单线程,同时内核态的时间由于存在CPU调度的问题,会略比单核情况高,同时多线程多核情况下的CPU利用率也高于100%
明显可看到,对于多核的情况,多核编程机制让应用可以更有效地将自身的多个执行任务(并发的多个线程)分散到不同的处理器上运行,以实现近似的并行计算。
写在最后
操作系统还真是门挺重要的课程,以前没有系统学习过,现在感觉欠下的东西都得补,无论是实际项目还是求职,都会有很多操作系统的知识点。本文以C语言实验为例,讨论操作系统能够进行计算调度的最小单位——线程的创建与并发问题。 线程是进程的具体执行流,是进程的实际执行单位,一个进程中可以包含多个线程以实现并发。本文将通过一些C语言代码实验说明线程的创建方式、并发执行、内存共享情况。并以蒙特卡洛法估算pi值为例,体会多线程的在多核编程的时间优势。
以后还会不定期更新一些计算机基础的文章,网安的文章也会慢慢更新,近期准备找工作,可能也会开辟一些新的方向,如果各位读者有什么问题也欢迎评论区指出,我一定知无不言。
















 3484
3484











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









