







目录
写在开头
本文我将带领读者一起使用深度学习框架PyTorch逐步搭建深度神经网络。以博主StatQuest的一个基本案例引入,直观感受神经网络是如何成为“万能函数模拟器”的,并简要介绍神经网络前向传播和反向传播的原理,搭建一个非常简易的深度神经网络,并实现一个训练集仅有三个数据点的神经网络参数。此处特别感谢博主StatQuest,他的视频相对通俗简单的描述了许多深度学习领域的模型原理,这里给出其B站账号链接:
【官方双语】一步一步带你用PyTorch构建神经网络!_哔哩哔哩_bilibili
此外还要感谢B站爆肝杰哥的讲解,详解了PyTorch的GPU配置(是为数不多能切实解决问题反的,比错误百出都是相互copy的某些C站博主强多了),并带领我实现了一些具体的神经网络代码。本文是在杰哥讲解之上的总结,其中有一些图片来自其课件,这里也给出他的视频链接:
Python深度学习:安装Anaconda、PyTorch(GPU版)库与PyCharm_哔哩哔哩_bilibili
本文使用的PyTorch为1.12.0版本,Numpy为1.21版本,相近的版本语法差异很小。有关数组的数据结构教程,详见我的上一篇博客:
一、神经网络的基本原理
这块我们简单说一下,就不涉及具体的数学推导了。神经网络号称“万能函数模拟器”,说白了就是通过学习大量样本的输入特征与输出特征的关系,拟合出输入和输出之间的函数方程。简单划分,在整个神经网络实现过程中涉及的步骤如下:
1.划分数据集:将已有(输入,输出)对应关系的数据集划分为训练集和测试集,用于后续的训练与测试。
2.训练网络:用训练集中的数据训练网络,通过不断的前向传播和反向传播的轮回,调整网络内部的参数,最终学习到合适的参数,实现对输入和输出关系的拟合。
3.测试网络:将训练好的网络用测试集测试性能,看看其拟合效果。
4.使用网络:如果测试集表现良好,那么该训练好参数的神经网络就可以用在实际环境中了。
一个全连接的神经网络的结构如下图:
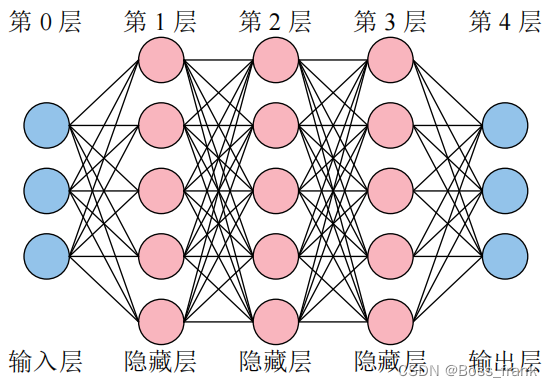
每个圆圈表示一个神经元,注意输入层和输出层神经元的个数对应等于输入特征的个数与输出特征的个数(这个图对应于有三个输入特征、三个输出特征的情况)。 神经网络的构建涉及到许多参数,可分为如下:
参数:通常指网络内部的参数,即此处就指网络中的权重w和偏置b。
超参数:一些其他的外部参数,网路的形状(网络层数、每个层数的节点数)、每个激活函数的类型、学习率、轮回次数、每次轮回训练的样本数等。
前向传播
理想的神经网络是如何实现“万能函数模拟器”的功能呢?说白了,就是将一些非线性的激活函数,经过撕拉抓打扯拽(截取、翻转、伸缩、拼接等),合成一个函数,最终这个函数可以拟合输入和输出的关系。前向传播就是指“输入值”进入神经网络,最终输出一个拟合的“输出值”的过程。以上图为例,将单个样本的3个输入特征送入送入神经网络的输入层后,逐层计算到输出层,最终得到神经网络预测的三个特征。以第一层的第一个神经元为例,计算如下:
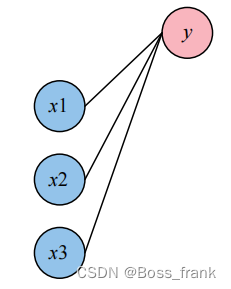
上图中的每根线上都有一个权重w,同时神经元节点也有自己的偏执b,对于这个神经元,其输入和输出的关系是:
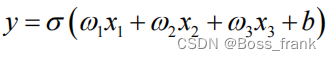
其中的σ是一个非线性的激活函数,比如ReLu,长下面这样:
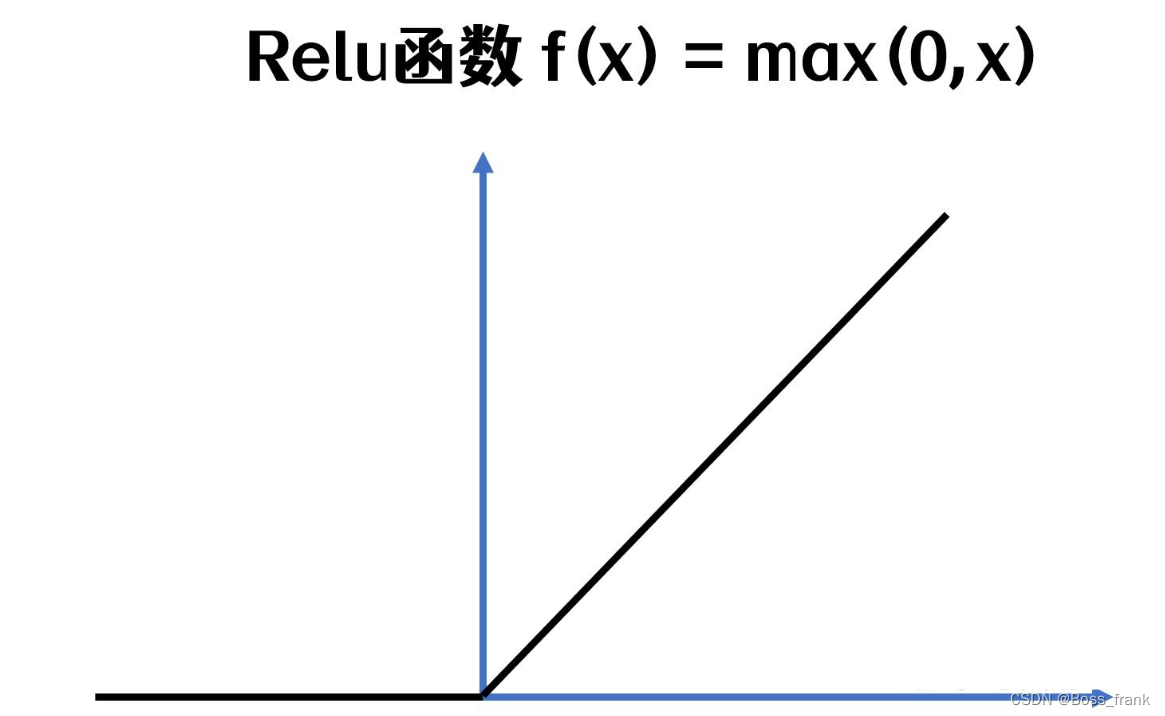
使用非线性激活函数的原因是,本身的方程w1x1+w2x2+w3x3+b是线性的,如果不套一层非线性函数,无论经过多少层网络,都相当于一层线性网络(线性的叠加还是线性)。最终前向传播就是将输入值通过这样一层层运算计算出最终输出值的过程 。
反向传播
神经网络参数的选取直接决定了这个“万能函数模拟器”的拟合效果。那么如何调节这些参数,使得拟合效果好呢?这时候就涉及到反向传播。初始的时候,网络中的参数都是随机的,经过前向传播,会得到一个预测值,这个预测值和实际的输出值会有差距,可以构建一个损失函数来描述这个差距(比如绝对值函数),每次预测都计算当前的损失函数,根据损失函数逐层退回求梯度,目标是使得损失函数的输出最小,此时网络中的参数就是训练好的了。逐层退回求梯度的过程涉及到链式法则,这里不展开说了,有兴趣的小伙伴可以看StatQuest的视频,他给的很详细。总之,反向传播用来优化网络内部参数,使得拟合效果变好。
在这个过程中,需要设定学习率lr,lr越大,则内部参数的优化速度就会变快,但lr过大时,有可能会使得损失函数越过极小值点,在谷底反复横跳,而lr国小,则训练速度可能过慢不易收敛,在网络的训练开始前选择一个合适的学习率还是比较重要的(PyTorch也封装了自动选择学习率的方法)。
最后介绍两个概念,epoch和batch_size:
epoch就是轮次,1个epoch表示全部样本进行一次前向传播与反向传播。
batch_size是一次性喂入网络的训练数据的样本数,在训练网络时,通常分批次将样本喂入网络,降低计算开销。通常batch_size是2的整数次幂。
二、直观感受神经网络构建的函数
这里以StatQuest的案例,以一个只有一层隐藏层的神经网络个为例,看看神经网络是如何拟合出输入与输出的关系的。
数据集
案例是拟合药物服用剂量(Dose)和药效(Output)的关系。数据集(训练集)一共就三个数据点,当剂量很小或很大时(Dose=0 or Dose = 1),药效很差(Effectiveness=0),当剂量适中时(Dose = 0.5),药效才好(Effectiveness = 1),总之就这三个点,如下:
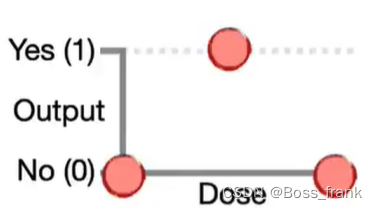
神经网络的结构
那么我们的神经网络的目标,就是拟合出一个合理的函数,其函数图像尽可能同时靠近(尽可能穿过)这三个数据点。 最终拟合出的函数并不唯一,与神经网络的结构,激活函数的选择等都有关系,这里假定选用ReLu作为激活函数,构建的神经网络如下:
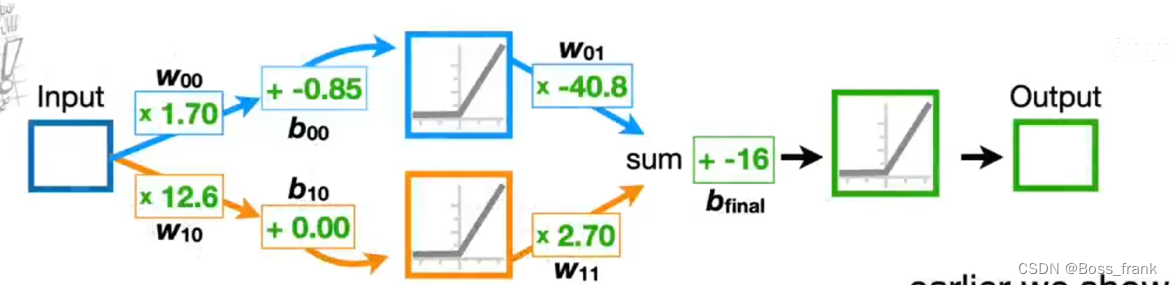
这是一个非常简单的神经网络,输入层和输出层之间只有一个隐藏层,隐藏层只有两个神经元,激活函数采用ReLu,注意由于输入仅有一个特征(剂量Dose),且输出也只有一个特征(药效Effectiveness) ,因此与之对应,输入层和输出层也只有一个神经元。
上图中神经网络的参数(即权重w和偏置b)都已经给出,这是训练好的神经网络(即参数是训练好的),最终我们可以用一个测试集进行测试,得到当剂量在0-1之间每隔0.1进行采样,对应的药效Effectiveness输出,最终可以绘制出这样的函数图像:
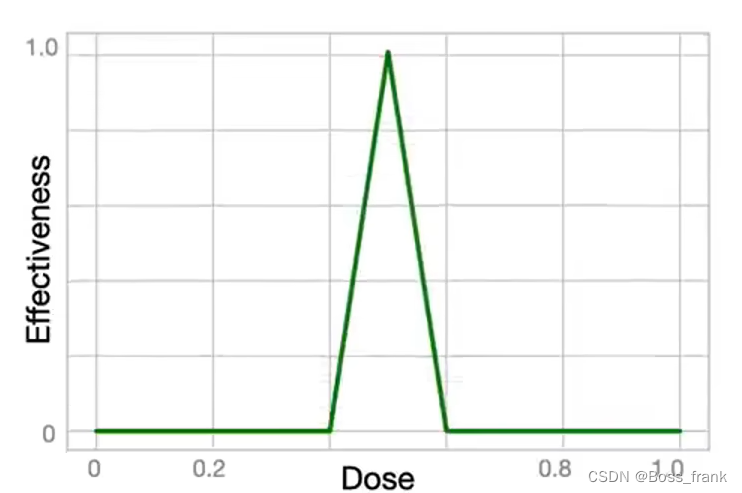
可以看到,这个函数确实能比较好的拟合训练集的参数,本质上讲,这个函数就是由两个非线性的激活函数ReLu经过撕拉抓打扯拽(裁剪、伸缩、翻转、拼接)得到的,至于如何撕拉抓打扯拽,则通过神经网络的参数确定,参数的选择则通过对训练集三个点的反向传播一步一步优化。
PyTorch实现
图中的这个神经网络的参数都是训练优化好的,下面我们简便起见,假设最后一个参数b_final没有优化过,初始化为0,我们尝试用Pytorch实现一下对这个参数的优化,将final_bias初始化为0,看看最终这个-16可否被优化出来的。首先引入一些相关的库:
import torch
import torch.nn as nn
import torch.nn.functional as F
import matplotlib.pyplot as plt
import seaborn as sns其中torch就是PyTorch框架,matplotlib和seaborn都是用来绘图的库。然后我们定义对照着图中的各个参数,搭建神经网络如下:
class BasicNN_train(nn.Module):
def __init__(self):
super().__init__()
self.w00 = nn.Parameter(torch.tensor(1.7), requires_grad=False)
self.b00 = nn.Parameter(torch.tensor(-0.85), requires_grad=False)
self.w01 = nn.Parameter(torch.tensor(-40.8), requires_grad=False)
self.w10 = nn.Parameter(torch.tensor(12.6), requires_grad=False)
self.b10 = nn.Parameter(torch.tensor(0.0), requires_grad=False)
self.w11 = nn.Parameter(torch.tensor(2.7), requires_grad=False)
self.final_bias = nn.Parameter(torch.tensor(0.0), requires_grad=True)
def forward(self, input):
input_to_top_relu = input * self.w00 + self.b00
top_relu_output = F.relu(input_to_top_relu)
scaled_top_relu_output = top_relu_output * self.w01
input_to_bottom_relu = input * self.w10 + self.b10
bottom_relu_output = F.relu(input_to_bottom_relu)
scaled_bottom_relu_output = bottom_relu_output * self.w11
input_to_final_relu = scaled_top_relu_output + scaled_bottom_relu_output + self.final_bias
output = F.relu(input_to_final_relu)
return output神经网络是以类的形式搭建的,这里我们创建类BasicNN_train,继承父类nn.Module即可,然后在构造函数__init__中进行初始化各个参数,这里注意首先要运行super().__init__(),对父类的成员进行初始化,然后再定义神经网络的参数。这里的参数除了最后的final_bias之外都是优化好的,因此只有final_bias的requires_grad参数被设置为True,表示这个参数需要被优化。
紧接着用forward函数定义前向传播过程,这个过程创建了从输入input到输出output的运算过程,相信大家都能看懂代码。
然后我们实例化这个网路,设定epoch=100,即最多进行100次前向和反向传播,定义损失函数就是预测值和实际值的平方误差,当损失函数之和低于0.0001时,我们就停止训练(最多训练100轮次),代码如下:
model = BasicNN_train()
inputs = torch.tensor([0., 0.5, 1.])
labels = torch.tensor([0., 1., 0.])
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
print("优化前的final_bias是:" + str(model.final_bias.data) + '\n')
# 开始训练,最多100轮次
losses = [] # 记录损失函数的变化
for epoch in range(100):
total_loss = 0
for iteration in range(len(inputs)):
input_i = inputs[iteration]
label_i = labels[iteration]
output_i = model(input_i)
loss = (output_i - label_i)**2 # 损失函数:平方误差
loss.backward()
total_loss += float(loss)
if total_loss < 0.0001:
print(f"当前是第{epoch}轮次,已经满足total_loss < 0.0001,结束程序。")
break
optimizer.step()
optimizer.zero_grad()
losses.append(total_loss)
print(f"当前是第{epoch}轮次,此时的final_bias值为{model.final_bias.data},total_loss为{total_loss}")
# 画图
Fig = plt.figure()
plt.plot(range(len(losses)), losses)
plt.xlabel("epochs")
plt.ylabel('loss')
plt.show()这段代码中,我们在每个epochs优化迭代后输出此时优化后的参数final_bias和总损失total_loss。同时最终绘制损失函数的变化曲线。每一轮迭代都会进行反向传播,代码为loss.backward(),这个方法已经在父类nn.Module中实现了,我们无需了解具体细节。另外使用优化器optimizer.step()对待优化参数final_bias进行优化,注意每轮要用代码optimizer.zero_grad()进行梯度清除,记住这么操作就行了。最终的输出结果如下:

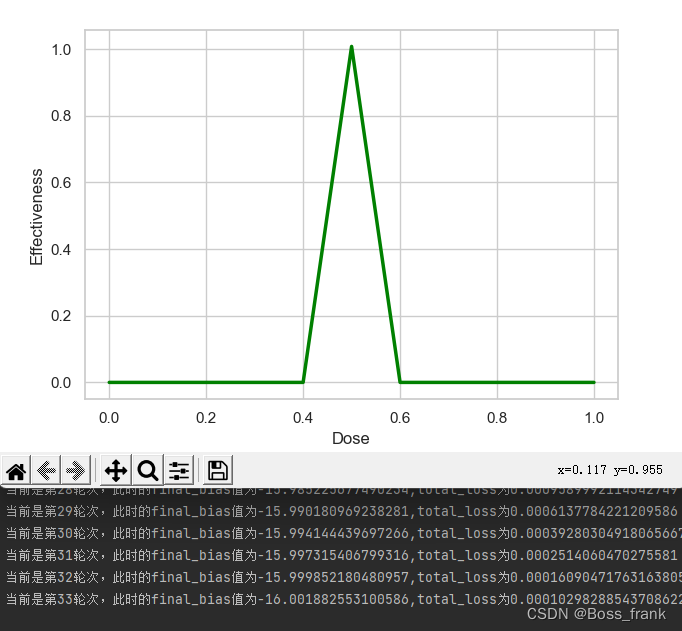
一共34轮训练后,就实现了总损失小于0.001的要求,也看到最终的优化结果final_bia大概是-16,与之前我们的结论一致。 损失函数变化曲线如下:
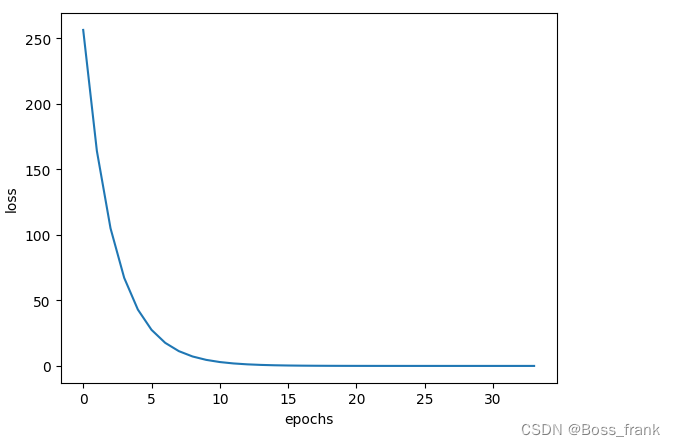
如果我们想每轮输出一个当前的函数图像,即在34轮次的优化中,每轮迭代出的final_bias带入神经网络会绘制出什么样的函数曲线,应该可以看到整个神经网络模拟出的函数曲线也在逐渐逼近训练集的三个点。第1轮迭代之后的函数图像如下:
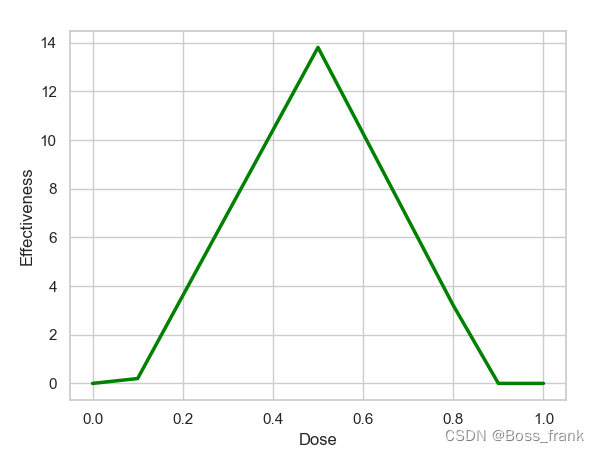
可以看到当Dose=0.5时,输出的有效性Effectiveness在14附近,远远超出了实际值1,此时的损失应该很大,计算得到此时的total_loss为256.32。
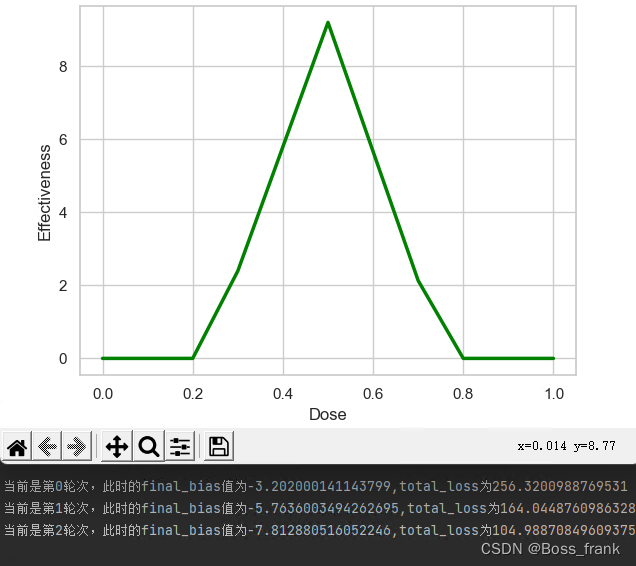
迭代到第3轮完成后,神经网络模拟出的图像变成了如下图,可以直观的看到,此时的图像的峰值已经降到了9左右,total_loss也下降到了104.98:
最终迭代到第34轮次后,即实现了最终的效果:
最后我们给出完整的代码,这个代码会在每个epoch轮次输出此时的参数final_bias值、当前损失total_loss,并绘制当前神经网络拟合出的函数曲线:
import torch
import torch.nn as nn
import torch.nn.functional as F
import matplotlib.pyplot as plt
import seaborn as sns
class BasicNN_train(nn.Module):
def __init__(self):
super().__init__()
self.w00 = nn.Parameter(torch.tensor(1.7), requires_grad=False)
self.b00 = nn.Parameter(torch.tensor(-0.85), requires_grad=False)
self.w01 = nn.Parameter(torch.tensor(-40.8), requires_grad=False)
self.w10 = nn.Parameter(torch.tensor(12.6), requires_grad=False)
self.b10 = nn.Parameter(torch.tensor(0.0), requires_grad=False)
self.w11 = nn.Parameter(torch.tensor(2.7), requires_grad=False)
self.final_bias = nn.Parameter(torch.tensor(0.0), requires_grad=True)
def forward(self, input):
input_to_top_relu = input * self.w00 + self.b00
top_relu_output = F.relu(input_to_top_relu)
scaled_top_relu_output = top_relu_output * self.w01
input_to_bottom_relu = input * self.w10 + self.b10
bottom_relu_output = F.relu(input_to_bottom_relu)
scaled_bottom_relu_output = bottom_relu_output * self.w11
input_to_final_relu = scaled_top_relu_output + scaled_bottom_relu_output + self.final_bias
output = F.relu(input_to_final_relu)
return output
if __name__ == '__main__':
model = BasicNN_train()
inputs = torch.tensor([0., 0.5, 1.])
labels = torch.tensor([0., 1., 0.])
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
print("优化前的final_bias是:" + str(model.final_bias.data) + '\n')
# 开始训练,最多100轮次
for epoch in range(100):
total_loss = 0
for iteration in range(len(inputs)):
input_i = inputs[iteration]
label_i = labels[iteration]
output_i = model(input_i)
loss = (output_i - label_i)**2
loss.backward()
total_loss += float(loss)
if total_loss < 0.0001:
print(f"当前是第{epoch}轮次,已经满足total_loss < 0.0001,结束程序。")
break
optimizer.step()
optimizer.zero_grad()
print(f"当前是第{epoch}轮次,此时的final_bias值为{model.final_bias.data},total_loss为{total_loss}")
# 画图如下
input_doses = torch.linspace(start=0, end=1, steps=11)
output_values = model(input_doses)
sns.set(style="whitegrid")
sns.lineplot(x=input_doses,
y=output_values.detach(),
color='green',
linewidth=2.5)
plt.ylabel('Effectiveness')
plt.xlabel('Dose')
plt.show()
print(f"优化后的final_bias值为:{model.final_bias.data}")
写在最后
本文介绍了神经网络的基本原理,但并没有阐述过多数学细节,关键是理解神经网络可以通过对训练集样本的学习,建立一个从输入值模拟到输出值的过程,即实现对输出-输出关系的函数模拟。神经网络的本质是通过对激活函数的撕拉抓打扯拽(裁剪、翻转、拉伸、拼接),构建出在训练集上拟合良好的从输入值到输出值的函数关系,至于神经网络的参数(即 具体是如何撕拉抓打扯拽的)是通过反向传播,对损失函数的优化进行实现的。
本文的示例在搭建神经网络时较为繁琐,还要手动定义许多参数、构建前向传播的过程,实际上PyTorch已经为我们封装了DNN深度神经网络的搭建。我会在下一篇博客中具体阐述,并实现机器学习领域的Hello world——手写数字识别,敬请期待。
如有本文相关的问题或想共同探讨深度学习、网络安全方面的问题,欢迎各位读者通过评论区或私信的方式与我交流,我一定知无不言。总结不易,还请读者多多点赞关注支持!



















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











