







转载请声明出处:http://blog.csdn.net/zhongkejingwang/article/details/44132771
KNN即K-Nearest Neighbor,是数据挖掘中一种最简单的分类方法,即要判断某一个样本属于已知样本种类中的哪一类时,通过计算找出所有样本中与测试样本最近或者最相似的K个样本,统计这K个样本中哪一种类最多则把测试样本归位该类。如何衡量两个样本的相似度?可以用向量的p-范数来定义。
假设有两个样本X=(x1, x2, ..., xn),Y=(y1, y2, ..., yn),则他们之间的相似度可以用以下向量p-范数定义:
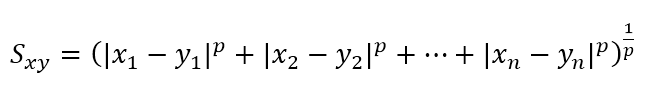
当p=2时即为计算X、Y的欧几里得距离。
本文将介绍用Java实现KNN分类器对Iris数据进行分类。Iris数据如下:
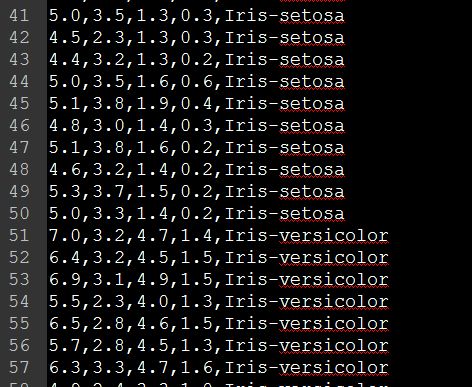
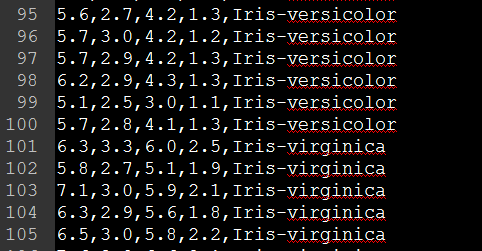
前面四个item是属性,最后一个是类别名,总共有三类。完整的数据集可点击这里下载。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4277
4277











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









