







- Hbase数据模型
- Hbase架构
- Hbase传统关系数据库的区别
- Hive的体系结构
- HIve部署类型
Hbase数据模型


• 表中仅有一行数据,行的唯一标识为com.cnn.www,对这行数据的每一次逻辑修改都有一个时间戳关联对应。
• 表中共有四列:contents:html,anchor:cnnsi.com,anchor:my.look.ca,mime:type,每一列以前缀的方式给出其所属的列族。
元素由行健、列(<列族>:<限定符>)和时间戳唯一确定,元素中的数据以字节码的形式存储,没有类型之分。
行键是数据行在表中的唯一标识,并作为检索记录的主键。
在Hbase中访问表中的行有三种方式:通过单个行键访问,给定行键的范围访问,全表扫描。
Hbase提供了两个版本的回收方式:
1.对每个数据单元,只存储指定个数的最新版本;
2.保存最近一段时间内的版本(如七天),客户端可以按需查询。
物理模型
概念模型中的一个行进行分割并按照列族存储。
表中的空值是不被存储的;如果没有指名时间戳,则返回指定列的最新数据值;可以随时向表中的任何一个列添加新列,而不需要事先声明。

Hbase架构
Hbase采用master/slave架构,主节点运行的服务称为HMaster,从节点服务称为HRegionServer,底层采用HDFS存储数据。

1) Client
Client端使用Hbase的RPC机制与HMaster和HRegionServer进行通信。
2) ZooKeeper
存储了ROOT表的地址、HMaster的地址和HRegionServer地址。
3) HMaster
Hbase主节点,将Region分配给HRegionServer,协调HRegionServer的负载并维护集群状态。
4) HRegionServer
HRegionServer主要负责响应用户I/O请求,向HDFS文件系统中读写数据。
Hbase和关系型数据库的区别:
· Hbase只提供字符串这一种数据类型,其他数据类型的操作只能靠用户自行处理,而关系型数据库有丰富的数据类型;
· Hbase数据操作只有很简单的插入、查询、删除、修改、清空等操作,不能实现表与表关联操作,而关系型数据库有大量此类SQL语句和函数;
· Hbase基于列式存储,每个列族都由几个文件保存,不同列族的文件是分离的,关系型数据库基于表格设计和行模式保存;
· Hbase修改和删除数据实现上是插入带有特殊标记的新纪录,而关系型数据库是数据内容的替换和修改;·Hbase为分布式而设计,可通过增加机器实现性能和数据增长,而关系型数据库很难做到这一点。
Hive
Hive是一个构建在Hadoop上的数据仓库框架,它起源于Facebook内部信息处理平台。
设计目的:让Facebook内精通SQL(但Java编程相对较弱)的分析师能够以类SQL的方式查询存放在HDFS的大规模数据集。
Hive 基本框架
Hive包含Shell环境、元数据库、解析器和数据仓库的组件,其体系结构如图所示:

用户接口:包括HiveShell、Thrift客户端、Web接口。
Thrift服务器:包括HiveShell、Thrift客户端、Web接口。
元数据库:Hive元数据(如表信息)的集中存放地。
解析器:将Hive语句翻译成MapReduce操作。
Hadoop:底层分布式存储和计算引擎。
Hive部署
按照元数据库(Metastore)存储位置的不同,分为:内嵌模式、本地模式和完全远程模式。

内嵌模式
此模式是安装时的默认部署模式,此时元数据存储在一个内存数据库Derby中,并且所有组件(如数据库、元数据服务)都运行在同一个进程内。这种模式下,一段时间内只支持一个活动用户。但这种模式配置简单,所需机器较少。

本地模式
此模式是Hive元数据服务依旧运行在Hive服务主进程中,但元数据存储在独立数据库中(可以是远程机器),当涉及元数据操作时,Hive服务中的元数据服务模块会通过JDBC和存储于DB里的元数据数据库交互。

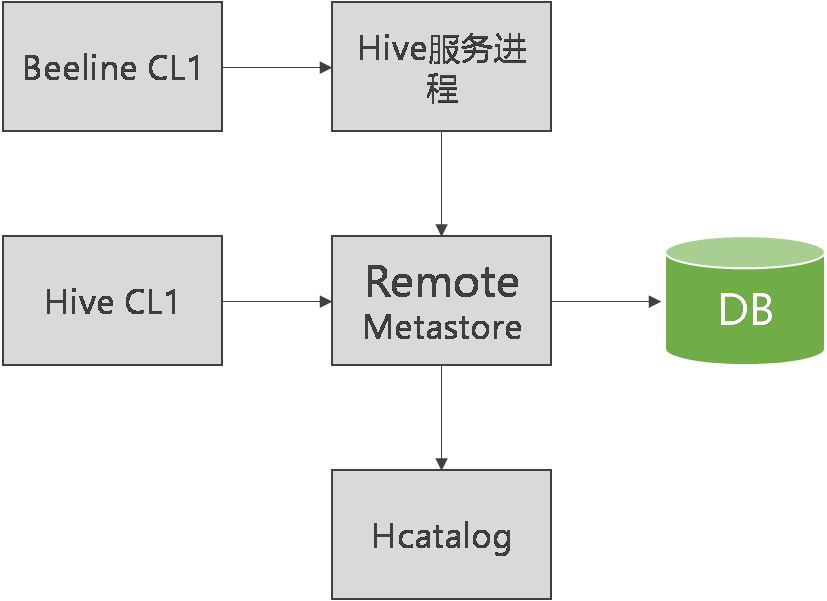
完全远程模式
元数据服务以独立进程运行,并且元数据存储在一个独立的数据库里。















 456
456

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









