







1. 分析页面内容数据格式
-
打开 https://36kr.com/
-
按F12(或 在网页上右键 --> 检查(Inspect))
-
找到网页上的Network(网络)部分
-
鼠标点击网页页面,按 Ctrl + R 刷新网页页面,可以看到 NetWork(网络)部分会刷新出很多的网络信息
-
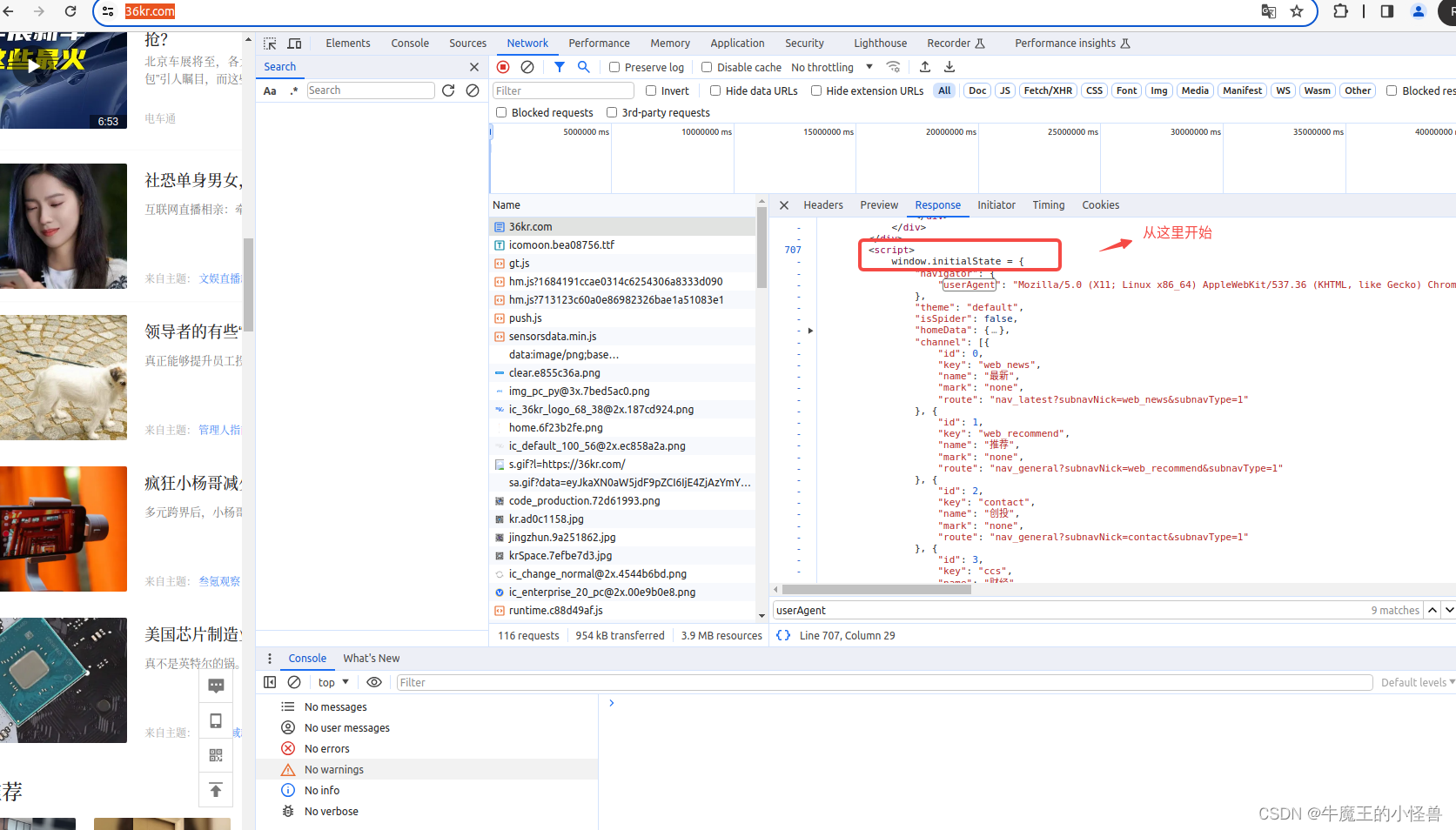
在Name 列,找到 36kr.com 条目,右侧自动显示网页的相关内容:Headers, Preview, Response … …
-
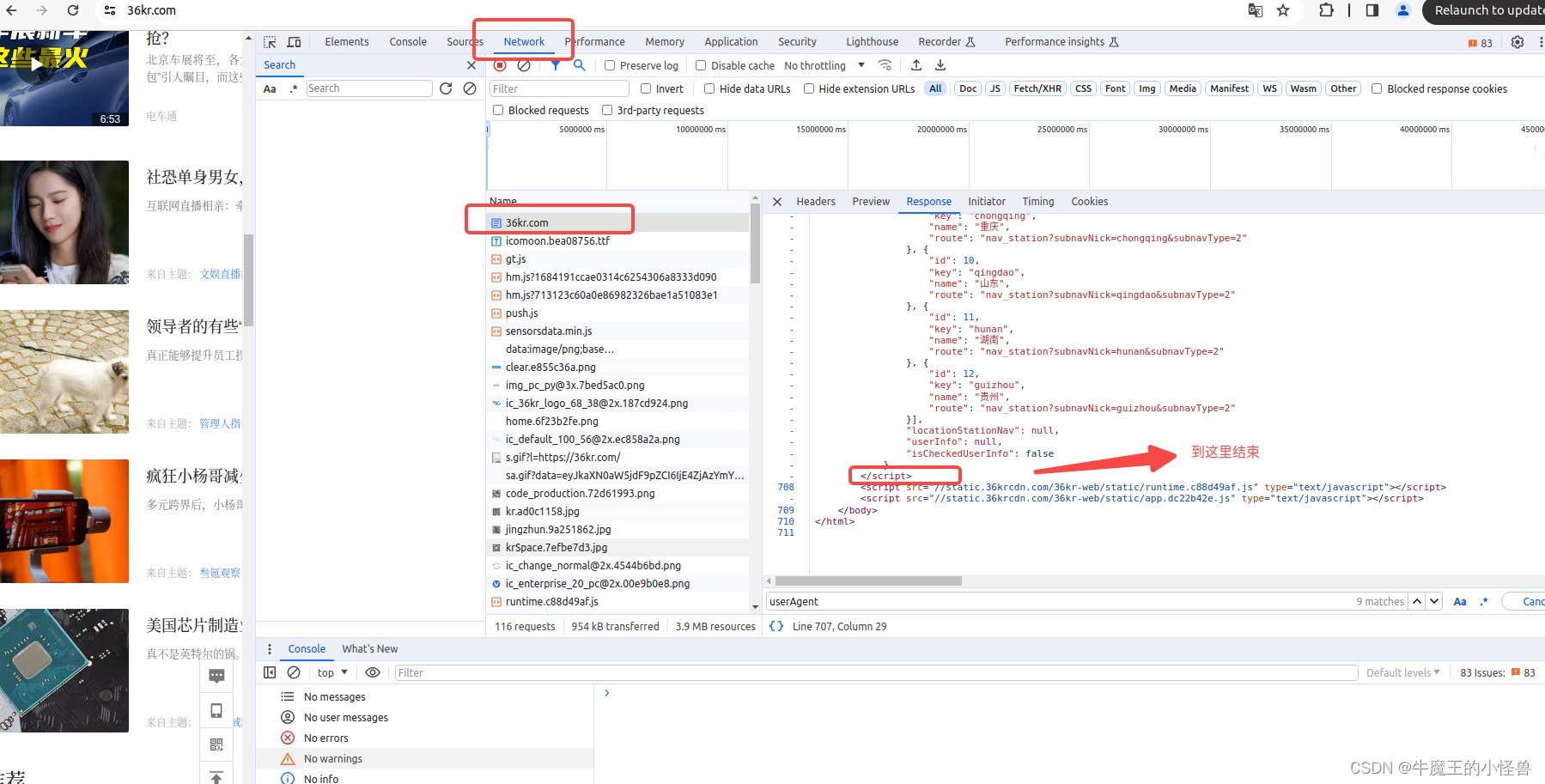
分析Response内容,所需要关心的内容,位于整个html页面的下面
2. 使用re.findall方法,爬取新闻
要点:从 之间的数据都是json数据。 json.loads会自动将false转为False, true转为True
import re
import requests
import json
# URL路径
url = "https://36kr.com/"
response = requests.get(url)
str1 = response.content.decode()
# 查找,使用正在表达式->取数组的第一个
result = re.findall("<script>window.initialState=(.*?)</script>", str1)[0]
# 先写入到本地,再查看
with open("36kr.json", "w", encoding="utf-8") as f:
f.write(result)
# 加载json转换成python类型
json_result = json.loads(result)
print(json_result)
# pretty print the data: 其中 json.dumps() 对数据格式进行了美化:
print(json.dumps(json_result, indent=4))
print(f'data.theme = {json_result["theme"]}')
print(f'data.isSpider = {json_result["isSpider"]}')
for item in json_result["channel"]:
print(f'name = {item["name"]}, '
f'key = {item["key"]} ')
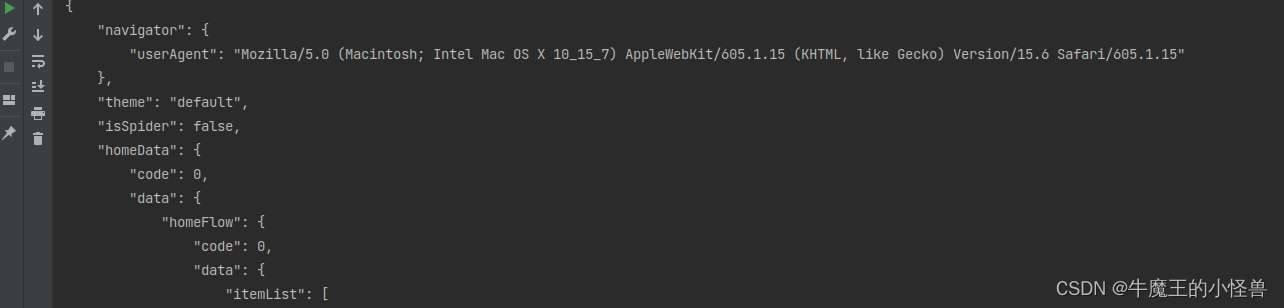
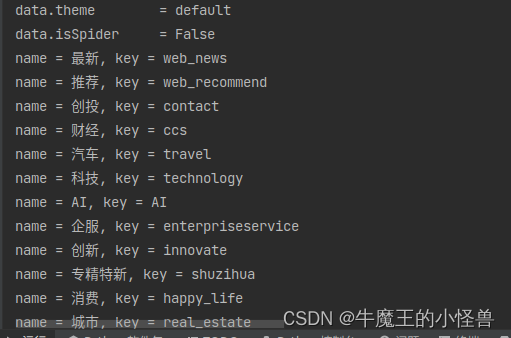
运行结果:
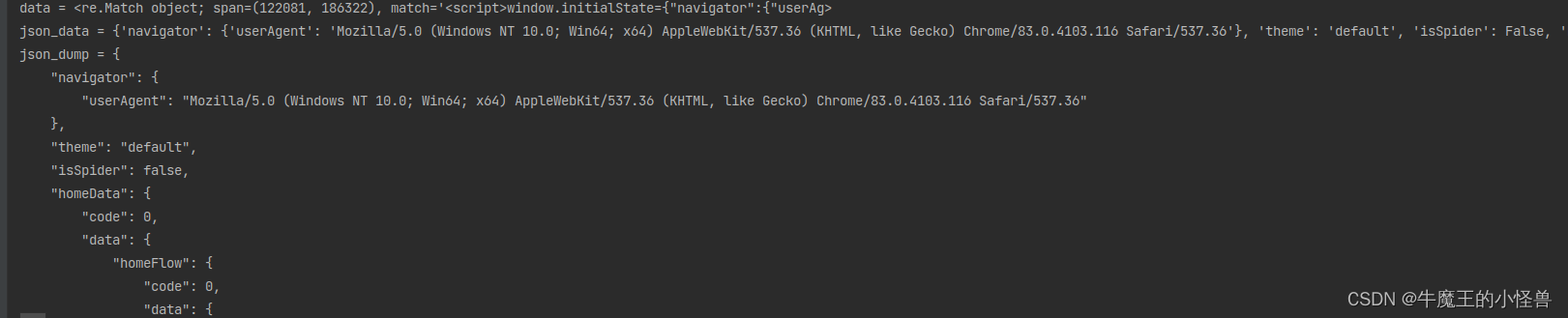
3. 使用re.search 方法,爬取新闻
要点:从 之间的数据都是json数据。 json.loads会自动将false转为False, true转为True
import re
import json
import requests
# URL路径
url = "https://36kr.com/"
html_doc = requests.get(url).text
data = re.search(r"<script>window.initialState=(.*?)</script>", html_doc)
print(f"data = {data}")
json_result = json.loads(data.group(1))
print(f"json_data = {json_result}")
# pretty print the data:
print(f"json_dump = {json.dumps(json_result, indent=4)}")
print(f'data.theme = {json_result["theme"]}')
print(f'data.isSpider = {json_result["isSpider"]}')
for item in json_result["channel"]:
print(f'name = {item["name"]}, '
f'key = {item["key"]} ')
运行结果:


















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











