







目录
一、YOLO-v8下载
yolov8官网地址:https://github.com/ultralytics/ultralytics
直接点击code中的Download ZIP下载即可
二、环境创建
创建yolo环境
通过终端创建新环境:conda create -n yolo python=3.10 其中“yolo”是环境名称,后面是python版本
安装cuda、cudnn和pytorch
Ps:建议按照cuda、cudnn、pytorch的顺序安装
-
cuda官网:
https://developer.nvidia.com/cuda-downloads
可以通过在终端中输入nvidia-smi来查看gpu所支持的cuda版本(可以不在c盘安装)
安装完cuda后,可在终端输入nvcc --version查看是否安装cuda -
cudnn官网:
https://developer.nvidia.com/rdp/cudnn-archive
下载完后发现有三个文件夹,将这三个文件夹复制到cuda的安装目录下,默认的安装目录为:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA
验证安装成功:进入目录(安装目录下的extras\demo_suite目录)C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.3\extras\demo_suite,在cmd中分别执行bandwidthTest.exe和deviceQuery.exe,执行结果为PASS则安装成功 -
pytorch官网:
https://pytorch.org/
按下win+r建输入cmd进入终端,通过指令activate yolo激活yolo环境后,输入pytorch中的安装指令。如:pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
检验:使用以下 Python 代码来查看 PyTorch 的版本和cuda可用性:import torch print(torch.__version__) print("Is CUDA available:", torch.cuda.is_available())
安装yolov8 python官方包(包含了requirement)
一定要在torch安装后再进行安装!!
pip install ultralytics
三、测试yolov8是否可以使用
预训练权重的下载
在yolov8源码的根目录下找到README文件,打开后找到yolov8n模型,并根据链接下载,并放在根目录下
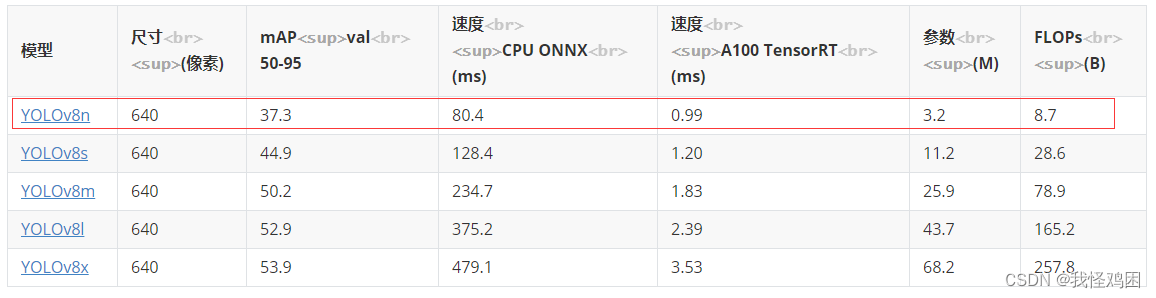
进行预测
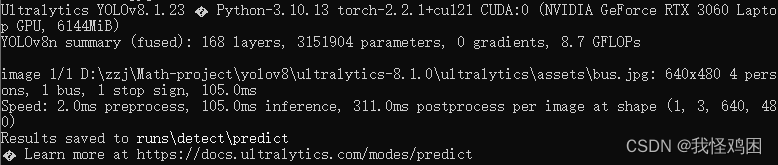
在yolov8根目录下打开cmd,输入下列代码测试:
yolo predict model=yolov8n.pt source='ultralytics/assets/bus.jpg'
结果如下图所示:
然后可以在根目录下找到“runs”文件夹,在runs中的detect\predict文件夹中存放着刚刚预测的结果:
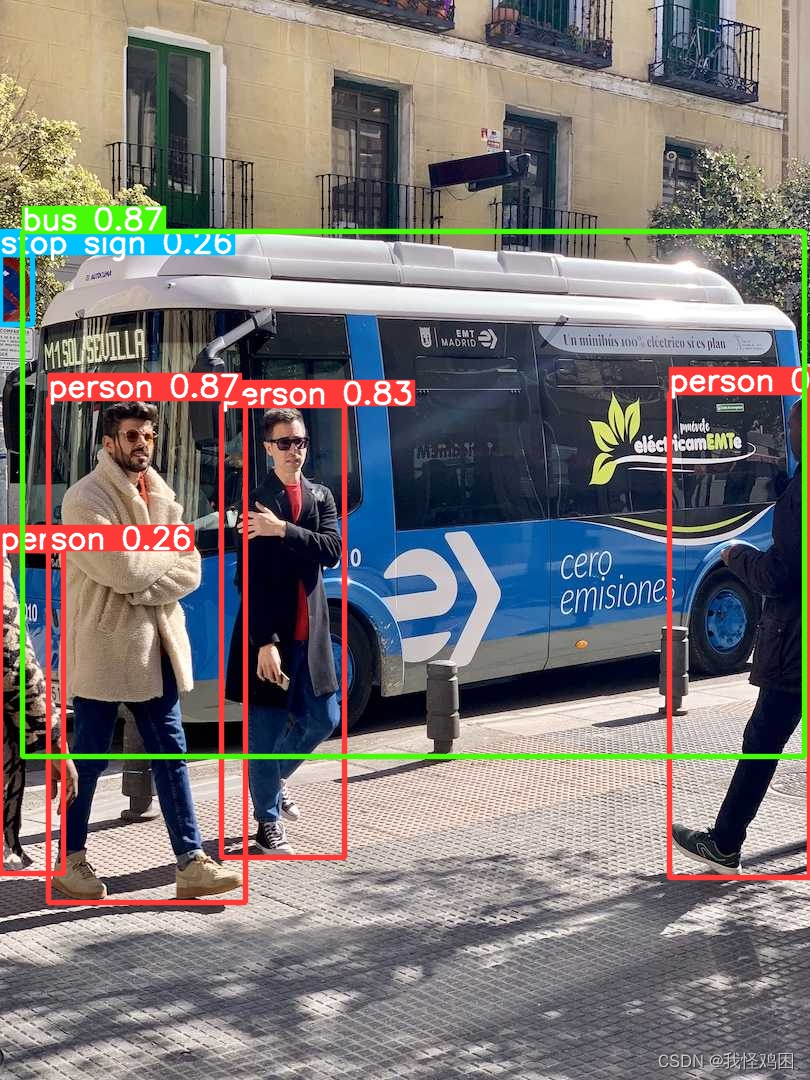
四、建立自己的数据集
数据集标注软件:labelImg
官方下载地址:https://github.com/tzutalin/labelImg
安装:下载完后,cd到labelImg-master文件夹下,在终端输入
conda install pyqt=5
pyrcc5 -o libs/resources.py resources.qrc
conda install lxml
进行安装,通过labelImg.py打开软件
数据集格式
- 文件夹“datasets”
- 文件夹“train”(训练集数据)
- 文件夹“images”(图片)
- 文件夹“labels”(标注)
- classes.txt
- 文件夹“val”(验证集数据)
- 文件夹“images”(图片)
- 文件夹“labels”(标注)
- classes.txt
- data.yaml
- 文件夹“train”(训练集数据)
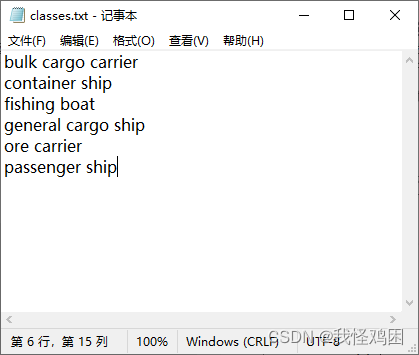
classes.txt:存放数字标签对应的类别,如船舶分类类别:
data.yaml:里面存放数据集的路径、训练集和验证集所在的位置,分类类别,分类数量
ps:yolo会根据图片地址自动找到对应名称的txt地址
path: D:\zzj\Math-project\datasets # dataset root dir
train: train/images/train2024 # train images (relative to 'path')
val: val/images/val2024 # val images (relative to 'path')
test: # test images (optional)
#分类数量
nc: 6
#分类类别
names: ['bulk cargo carrier','container ship', 'fishing boat', 'general cargo ship', 'ore carrier', 'passenger ship']
五、训练数据集
ps:一定要先改yolov8.yaml中nc的值!!!!(nc为分类个数)
路径:ultralytics\cfg\models\v8\yolov8.yaml
在项目中新建train.py:
from ultralytics import YOLO
def main():
model = YOLO("yolov8m.yaml") #加载模型
model.train(data=r"datasets\data.yaml", epochs=100, workers=8, device=0) #训练模型
metrics = model.val() # 在验证集上评估模型性能
if __name__ == '__main__':
main()
其中model.train中的参数如下:
官网给出的解释:https://docs.ultralytics.com/modes/train/
推荐一个训练参数解释的不错的文章:https://blog.csdn.net/qq_37553692/article/details/130898732
| Key | 默认值 | 描述 |
|---|---|---|
model | None | 指定用于训练的模型文件。 |
data | None | 数据集配置文件的路径(例如 coco128.yaml).该文件包含特定于数据集的参数,包括训练数据和验证数据的路径、类名和类数。 |
epochs | 100 | 训练轮数 |
| time | None | 最长训练时间(小时)。如果设置了该值,则会覆盖 epochs 参数,允许训练在指定的持续时间后自动停止。 |
| patience | 100 | 在验证指标没有改善的情况下,提前停止训练所需的训练轮数。当性能趋于平稳时停止训练,有助于防止过度拟合。 |
batch | 16 | 训练的批量大小,表示在更新模型内部参数之前要处理多少张图像。自动批处理 (batch=-1)会根据 GPU 内存可用性动态调整批处理大小。 |
imgsz | 640 | 用于训练的目标图像尺寸。所有图像在输入模型前都会被调整到这一尺寸。影响模型精度和计算复杂度。 |
| save | True | 是否保存训练的检查点和预测结果。当训练过程中保存检查点时,模型的权重和训练状态会被保存下来,以便在需要时进行恢复或继续训练。预测结果也可以被保存下来以供后续分析和评估。 |
save_period | -1 | 保存模型检查点的频率,以 epochs 为单位。值为-1 时将禁用此功能。该功能适用于在长时间训练过程中保存临时模型。 |
resume | False | 从上次保存的检查点恢复训练。自动加载模型权重、优化器状态和历时计数,无缝继续训练。 |
device | None | 指定用于训练的计算设备:单个 GPU (device=0)、多个 GPU (device=0,1)、CPU (device=cpu),或苹果芯片的 MPS (device=mps)。 |
| workers | 8 | 数据加载时的工作线程数。在数据加载过程中,可以使用多个线程并行地加载数据,以提高数据读取速度。这个参数确定了加载数据时使用的线程数,具体的最佳值取决于硬件和数据集的大小。 |
| name | None | 训练运行的名称。用于在项目文件夹内创建一个子目录,用于存储训练日志和输出结果。 |
六、使用训练好的网络进行检测(detect)
from ultralytics import YOLO
#加载模型
model = YOLO(r"best.pt")
#要检测的数据存放的位置
results = model.predict(source=r"WarShip\detect", show=False ,save=True)

















 1925
1925

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









