






大家久等啦,距离上次写文章,已经有好几个月了,这次博主的女朋友学校项目需要更新使用yolov8,在这里就写一个教程(也算是边学边写文章),她也方便看,大家也可以收藏起来看。如果有哪里写的不好还行评论和@博主哦。
首先的是,这次教学按官网来一步一步教,这样子有助于大家阅读其他的github开源项目有帮助
1.YOLOv8简介
YOLOv8是目标检测领域的最新突破,它继承并优化了前代YOLO模型的设计理念。YOLOv8通过引入深度学习中的前沿技术,如自注意力机制和跨尺度特征融合,实现了对不同大小目标的高效检测。模型的轻量化设计降低了计算资源需求,使得YOLOv8能够在各种硬件平台上快速运行。此外,YOLOv8还增强了模型的泛化能力,使其在多种复杂场景下都能保持稳定的检测性能。
1.1.技术特性与改进点
YOLOv8通过引入先进的网络结构和优化算法,显著提升了检测速度和准确性。它利用多尺度特征融合和注意力机制,增强了对小目标的检测能力,同时减少了误检。
1.2.与YOLOv5的比较
相较于其他目标检测模型,YOLOv8在速度和精度上取得了平衡。它的轻量化设计使其更适合实时应用场景。与SSD、Faster R-CNN等模型相比,YOLOv8在保持高效率的同时,也提供了可比的检测精度。
2.环境搭建
2.1.依赖库安装
大家点击上面的链接之后,可以点击下面这里的中文官网。
往下滑之后,有五个YOLO的教程。

博主这边就以安装(Install)、训练(Train)以及Predict(预测)为例。
点击开始后,稍许往下滑之后,可以看到一个紫色的Install,这里也就是YOLO官方Python库的安装教程,博主这边是用上面那个命令,下面那个命令不太清楚使用之后是什么效果,点击右上角可以直接复制。
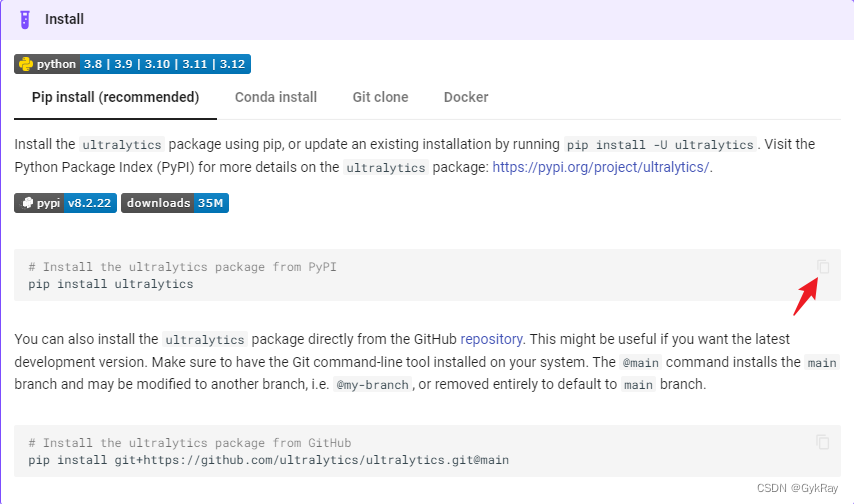
pip install ultralytics可以使用 Win+R ,输入cm,进入Windwos命令行终端去安装;也可以进入Pycharm编辑器里面的终端去直接输入命令也可以。安装的库比较大,还请大家都网络稍许好一些去下载。
再往下滑可以看到PyToch的安装教程,博主这里已CPU版为示例,大家可以看看网络上其他的教程去用带CUDA的PyTorch,这里直接把命令放在这里。
pip3 install torch torchvision torchaudio2.2.YOLOv8框架安装
在这里,大家打开github,登陆注册全部一起,然后在搜索栏输入框中搜索"YOLOv8"。
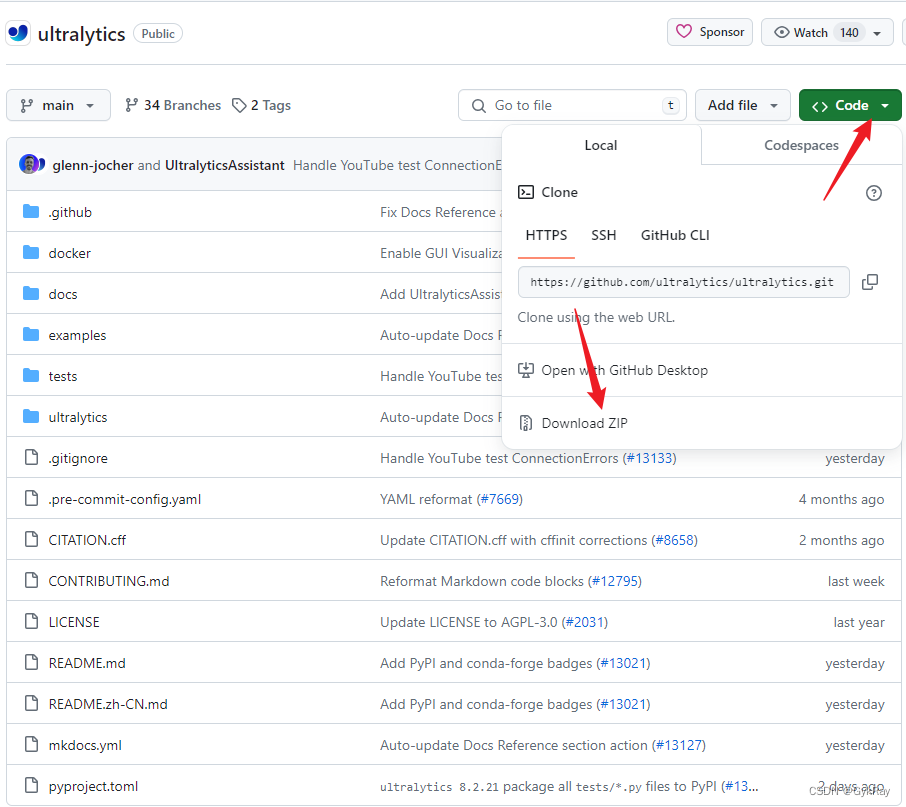
点击第一个Star最多的就是官方YOLOv8了。
然后点Code、Download ZIP就可以完整的下载下来了。
3.数据准备
博主这里以两种方式去教大家使用。
3.1.官方数据
还是在上面的官方页面,往下翻有一个例子。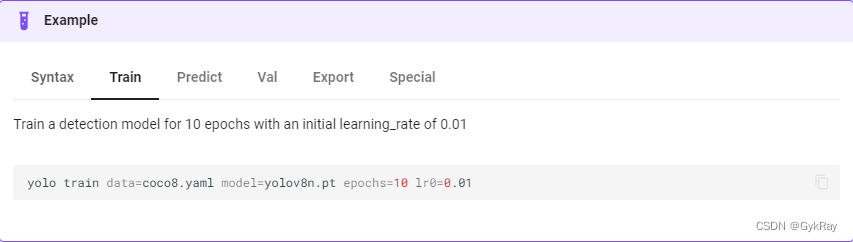
点击Train,可以看到这里有一串命令行运行代码,里面的内容具体每一个参数是干嘛用的暂且不管,重点放在 data=coco8.yaml 这里。大致的意思可以才到是数据集要用coco8.yaml里面的,然后我们现在就在文件管理器那去查找这个文件在哪。

然后方便的操作就是右键该文件,点击 打开文件所在的位置。
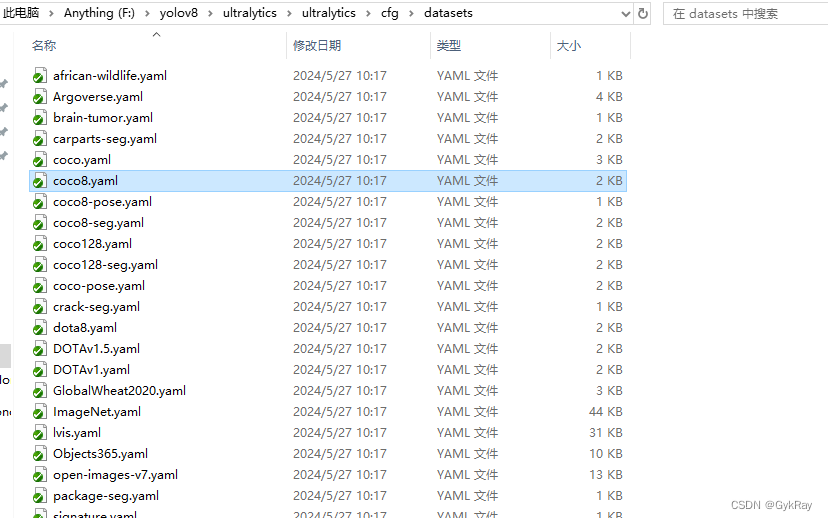
然后就可以看到这里有很多很多的官方示例的相关数据集的配置文件。这里就用Windows自带的记事本打开coco8.yaml文件。
博主这边就默认大家打开咯,然后里面的重要信息有这几个。
path、train、val、download(需要拉到文件最下方)。
path是整个数据集的根目录路径;train是path路径下的 images/train 文件夹(训练集);val是path路径下的 images/val 文件夹(验证集);download是下载当前这个数据集的github下载地址。
所以,当然是先下载数据集先咯,大家直接将链接复制-粘贴到浏览器上就可以下载啦;下载好后,按照文档里面的路径,在和coco8.yaml,同一个目录下去创建一个coco8文件夹。
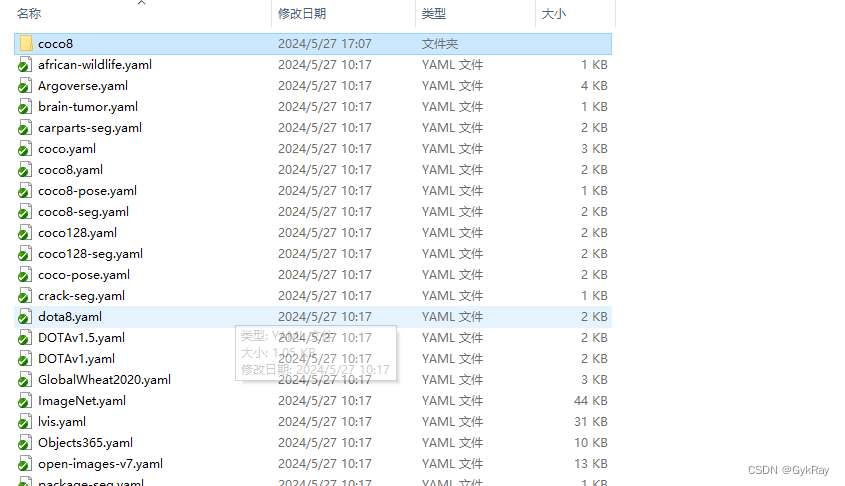
接下来将下载好的coco8.zip解压到这个coco8文件夹中。这样子官方的数据集就准备就绪啦,可以进行一些学习探索咯。
3.2.个人数据
3.2.1.准备工作(新建文件夹)

在ultralytics目录下创建文件夹VOCdata,在该文件夹下在创建两个文件夹Annotations(用于存放图片标注后产生的内容(以XML格式存放))和images(用于存放要标注的图片(虽然YOLO开始训练的时候会检测并自动更正格式,但是仍然建议以jpg格式存放))。
3.2.2.使用labelImg标注图片
这里可以直接在github搜索栏,搜索 labelImg ,下载解压下来就好了,博主这里就不贴图片了(反正就是看Star最多那一个)。放一个直达的网址:https://github.com/HumanSignal/labelImg
下载解压后,在 labelImg 目录下启动cmd。(在箭头指示的框框输入cmd)
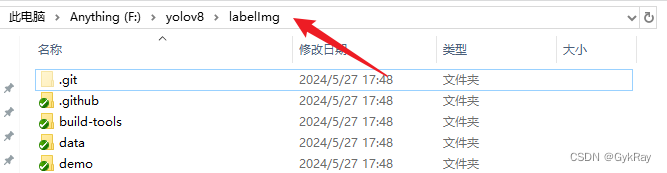
然后输入以下代码来启动labelImg。
python labelImg.py可能遇到的问题:
(1)No module named 'sip'报错
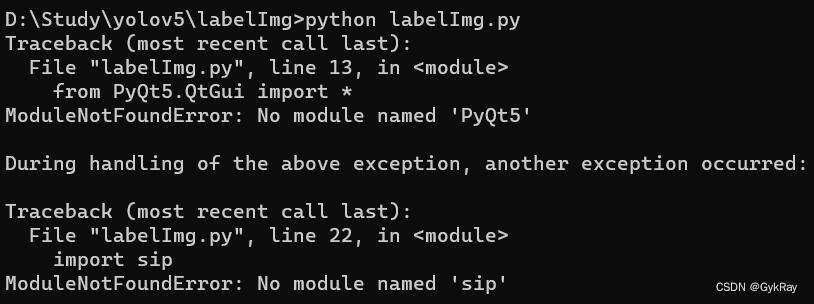
这是因为我们的Python环境下没有PyQt5包里面的sip包,这时候只需在 PyCharm终端 或者 Windows命令终端 输入以下代码即可解决问题。
pip install PyQt5(2)No module named 'libs.resources'报错
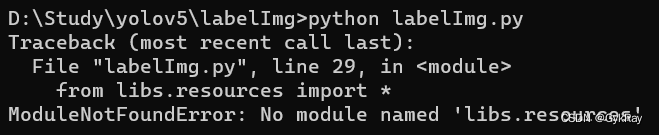
这是因为我们下载下来的labelImg文件夹下的包库里面没有resources.py,大家可以在labelImg文件夹下去运行以下命令。
Pyrcc5 -o resources.py resources.qrc 运行后会在当前目录生成一个 resources.py 文件,将这个文件剪切/复制到当前目录下的 libs 文件夹下即可解决问题。
接下来打开labelImg。
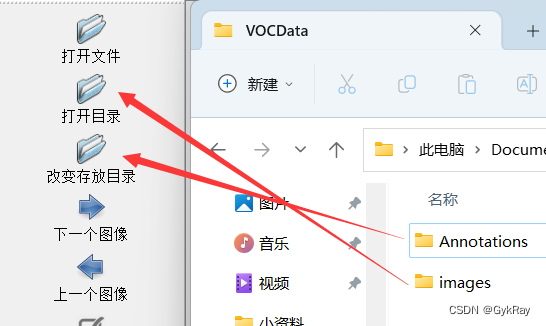
来到labelImg的使用界面后,左侧的打开目录对应存放标注图片的文件夹(images),改变存放目录对应标注图片产生的xml数据文件夹(Annotations)。
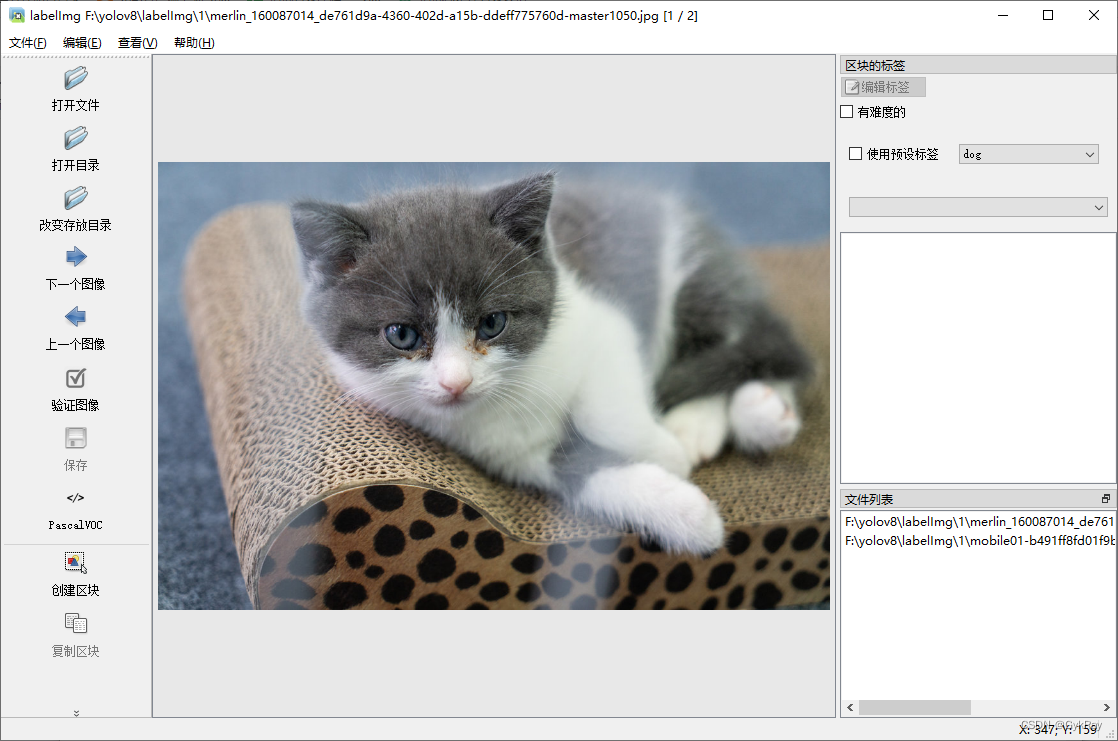
博主这边以网上随便找的猫猫狗狗图片为举例好了。 点击下面的创建区块就是数据标注;在创建区块上方,有一个图片标注后的存储格式,博主这边一一列举。
| 名称 | 格式 |
| PascalVOC | .XML |
| YOLO | .TXT |
| CreateML | .json |
博主这边以.XML格式存储。
3.2.3.数据集划分及配置文件修改
(1)划分训练集、验证集及测试集。
在VOCData目录下创建python程序 split_train_val.py 并运行,代码如下(不用修改代码)。
import os
import random
import argparse
parser = argparse.ArgumentParser()
#xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='Annotations', type=str, help='input xml label path')
#数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='ImageSets/Main', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 1.0 # 训练集和验证集所占比例。 这里没有划分测试集
train_percent = 0.9 # 训练集所占比例,可自己进行调整
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
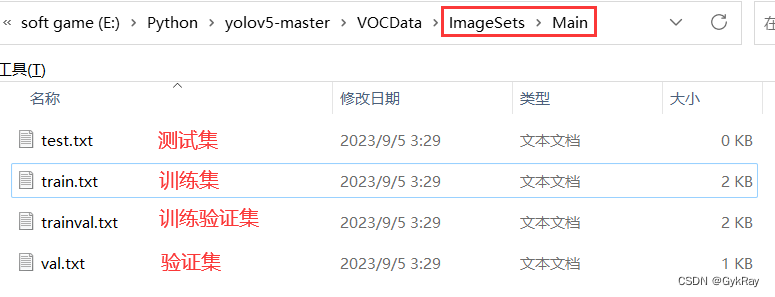
file_test.close()运行完毕后,会生成 ImagesSets/Main 文件夹,且在其下生成测试集、训练集、验证集来存放图片的名字(都是纯名字,没有文件格式后缀.jpg)。
由于没有分配测试集,所以测试集为空。若要分配,更改12,13这两行代码,更改所在比例即可。
(2)xml格式转txt格式
在VOCData目录下创建python程序 xml_to_yolo.py 并运行,代码如下(需要修改代码)。
这里需要修改的 第6行classes = ["light", "post"] ,要把中括号内的标签名就改成你自己需要的,比如博主个人有标有 classes = ["ripe"] ;除此之外还要修改的地方就是像 第24、25、53、54、55、57、58、63行 中出现的类似 'D:/Yolov5/yolov5/VOCData/Annotations/%s.xml' ,这里大家就需要把它改成自己的路径,比如博主个人的路径是 D:/Study/yolov5/VOCData/Annotations ,大家就直接复制粘贴就好(注意:最好只修改 D:/Study/yolov5/VOCData/ 这一段,因为这些路径多多少少是有一些不同,博主也是出于方便才特意说明)。
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val', 'test']
classes = ["light", "post"] # 改成自己的标签类别
abs_path = os.getcwd()
print(abs_path)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
in_file = open('D:/Yolov5/yolov5/VOCData/Annotations/%s.xml' % (image_id), encoding='UTF-8')
out_file = open('D:/Yolov5/yolov5/VOCData/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
#difficult = obj.find('Difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('D:/Yolov5/yolov5/VOCData/labels/'):
os.makedirs('D:/Yolov5/yolov5/VOCData/labels/')
image_ids = open('D:/Yolov5/yolov5/VOCData/ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
if not os.path.exists('D:/Yolov5/yolov5/VOCData/dataSet_path/'):
os.makedirs('D:/Yolov5/yolov5/VOCData/dataSet_path/')
list_file = open('dataSet_path/%s.txt' % (image_set), 'w') # 这行路径不需更改,这是相对路径
for image_id in image_ids:
list_file.write('D:/Yolov5/yolov5/VOCData/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
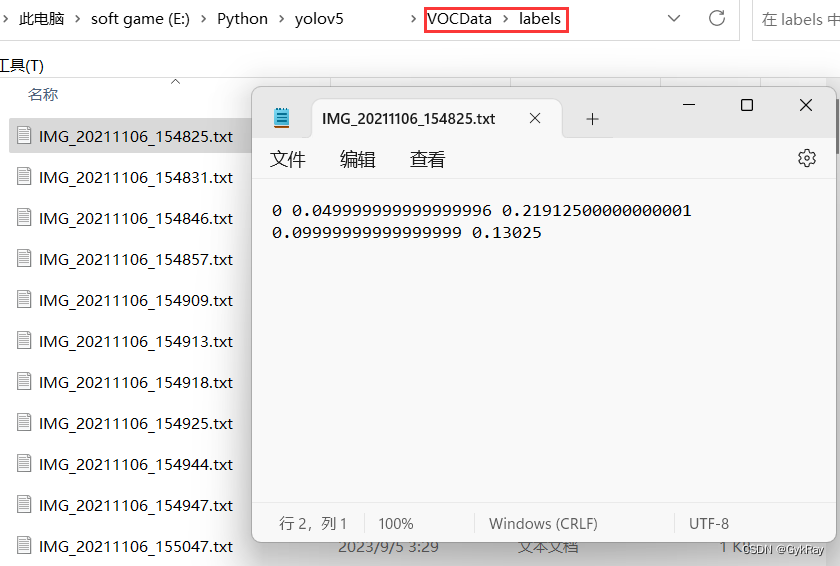
list_file.close()运行后会生成如下 labels 文件夹和 dataSet_path 文件夹。
其中 labels 中为不同图像的标注文件,每个图像对应一个txt文件,文件每一行为一个目标的信息,包括class, x_center, y_center, width, height格式,这种即为 yolo_txt 格式。
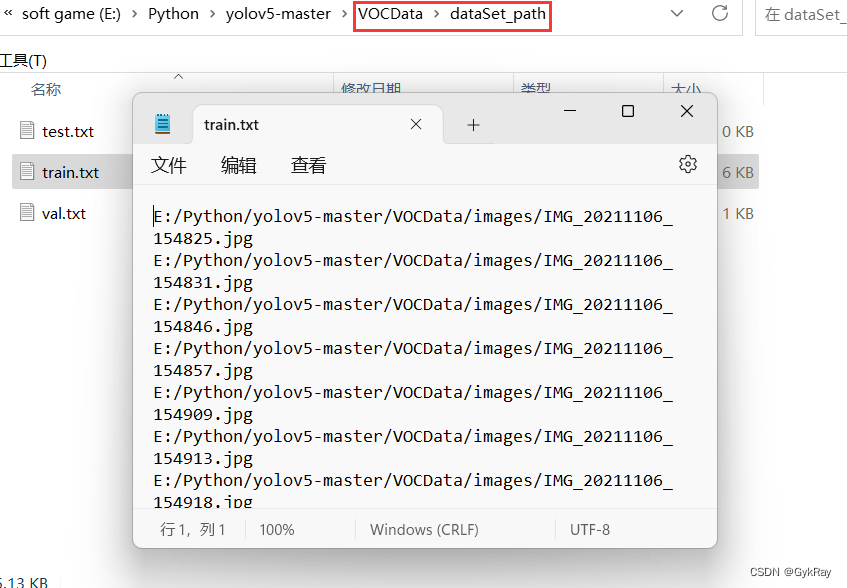
dataSet_path 文件夹包含三个数据集的txt文件,train.txt等txt文件为划分后图像所在位置的路径,如train.txt就含有所有训练集图像的路径(博主这里的路径和大家的不一样,需要注意一下)。
(3)配置文件
好的,前面的部分是照抄我前一个博客的内容,因为是在实习工作中写的这篇文章,节省偷懒一下。这里回到刚刚那个 coco8.yaml 文件。
最近博主工作忙没啥时间更新后续内容,请大家谅解,可以去看看其他博客!!!!
最近博主工作忙没啥时间更新后续内容,请大家谅解,可以去看看其他博客!!!!
最近博主工作忙没啥时间更新后续内容,请大家谅解,可以去看看其他博客!!!!
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











