







动手点关注 干货不迷路 👆
Split lock 是 CPU 为了支持跨 cache line 进行原子内存访问而支持的内存总线锁。
有些处理器比如 ARM、RISC-V 不允许未对齐的内存访问,不会产生跨 cache line 的原子访问,所以不会产生 split lock,而 X86 是支持的。
split lock 对开发者来说是很方便的,因为不需要考虑内存不对齐访问的问题,但是这同时也是有代价的:一个产生 split lock 的指令会独占内存总线大约 1000 个时钟周期,对比正常情况下的 ADD 指令约只需要小于 10 个时钟周期,锁住内存总线导致其他 CPU 无法访问内存会严重影响系统性能。
因此 split lock 的检测与处理就非常重要,现在的 CPU 支持检测能力,检测到如果在内核态会直接 panic,在用户态则会尝试主动 sleep 来降低 split lock 产生的频率,或者 kill 用户态进程,进而缓解对内存总线的争抢。
在引入了虚拟化后,会尝试在 Host 侧处理,KVM 通知 QEMU 的 vCPU 线程主动 sleep 降低 split lock 产生的频率,甚至 kill 虚拟机。以上的结论也只是截止目前 2022/4/19(下同)的情况,近 2 年社区仍对 split lock 的处理有不同的看法,处理方式也是改变了多次,所以以下的分析仅讨论目前的情况。
1. Split lock 背景
1.1 从 i++说起
我们假设一个最简单的计算模型,一个 CPU(单核、没有开启 Hyper-threading、没有 Cache),一块内存。上面运行一个 C 程序在执行i++,对应的汇编代码是add 1, i。
分析一下这里add指令的语义,需要两个操作数,源操作数 SRC 和目的操作数 DEST,实现的功能是DEST = DEST + SRC。这里 SRC 是立即数 1,DEST 是 i 的内存地址,CPU 需要先在内存中读出 i 的内容,然后加 1,最后把结果写入 i 所在的内存地址。总共产生了两次串行的内存操作。
如果计算架构复杂一点,有 2 个 CPU 核 CoreA 和 CoreB 的情况下,上面的i++代码就不得不考虑数据一致性的问题:
1.1.1 并发写问题
如果 CoreA 正在向 i 的内存地址中写入时,CoreB 同时向 i 的内存地址写入怎么办?
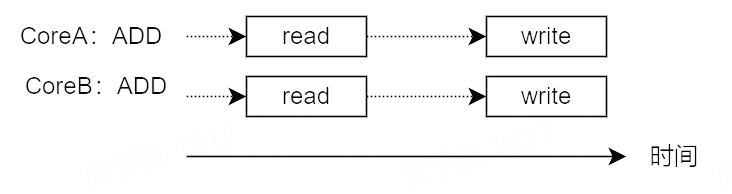
并发写相同内存地址其实很简单,CPU 从硬件上保证了基础内存操作的原子性。
具体的操作有:
读/写 1 byte
读/写 16 bit 对齐的 2 byte
读/写 32 bit 对齐的 4 byte
读/写 64 bit 对齐的 8 byte
1.1.2 写覆盖问题
如果 CoreA 从内存中读出 i 后,写入 i 所在内存地址前这段时间内,CoreB 向 i 的内存地址写入数据怎么办?
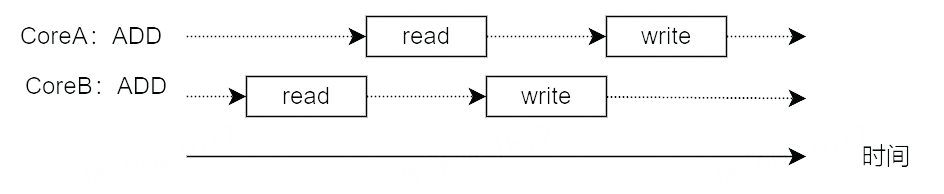
这种情况下会导致 CoreB 写入的数据被 CoreA 后面再写入的数据覆盖掉,使 CoreB 的写入数据丢失,而 CoreA 也不知道写入的数据已经在读出后被更新过了。
为什么会出现这个问题呢?就是因为 ADD 指令不是原子操作,会产生两次内存操作。
那怎么解决这个问题呢?既然 ADD 指令在硬件上不是原子的,那么就从软件上加锁来实现原子操作,使 CoreB 的的内存操作在 CoreA 的内存操作完成前不能执行。

对应方法就是声明指令前缀LOCK,汇编代码变为lock add 1, i。
1.2 总线锁
LOCK指令前缀声明后,随同执行的指令会变为原子指令。原理就是在随同指令执行期间,锁住系统总线,禁止其他处理器进行内存操作,使其独占内存来实现原子操作。
下面举几个例子:
1.2.1 QEMU 中的原子累加
QEMU 中的函数 qatomic_inc(ptr),把参数 ptr 指向的内存数据进行进行加 1。
#define qatomic_inc(ptr) ((void) __sync_fetch_and_add(ptr, 1))原理是调用 GCC 内置的__sync_fetch_and_add 函数,我们手写一个 C 程序,看下__sync_fetch_and_add 的汇编实现。
int main() {
int i = 1;
int *p = &i;
while(1) {
__sync_fetch_and_add(p, 1);
}
return 0;
}// add.s
.file "add.c"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
movl $1, -12(%rbp)
leaq -12(%rbp), %rax
movq %rax, -8(%rbp)
.L2:
movq -8(%rbp), %rax
lock addl $1, (%rax)
jmp .L2
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (Debian 6.3.0-18+deb9u1) 6.3.0 20170516"
.section .note.GNU-stack,"",@progbits可以看到__sync_fetch_and_add 的汇编实现就是在 add 指令前声明了 lock 指令前缀。
1.2.2 Kernel 中的原子累加
Kernel 中的 atomic_inc 函数,把参数 v 指向的内存数据进行进行加 1。
static __always_inline void
atomic_inc(atomic_t *v)
{
instrument_atomic_read_write(v, sizeof(*v));
arch_atomic_inc(v);
}
static __always_inline void arch_atomic_inc(atomic_t *v)
{
asm volatile(LOCK_PREFIX "incl %0"
: "+m" (v->counter) :: "memory");
}
#define LOCK_PREFIX LOCK_PREFIX_HERE "\n\tlock; "可以看到,同样是声明了 lock 指令前缀。
1.2.3 CAS(Compare And Swap)
编程语言中的 CAS 接口为开发者提供了原子操作,实现无锁机制。
Golang 的 CAS
// bool Cas(int32 *val, int32 old, int32 new)
// Atomically:
// if(*val == old){
// *val = new;
// return 1;
// } else
// return 0;
TEXT ·Cas(SB),NOSPLIT,$0-17
MOVQ ptr+0(FP), BX
MOVL old+8(FP), AX
MOVL new+12(FP), CX
LOCK
CMPXCHGL CX, 0(BX)
SETEQ ret+16(FP)
RETJava 的 CAS
inline jlong Atomic::cmpxchg (jlong exchange_value, volatile jlong* dest, jlong compare_value) {
bool mp = os::is_MP();
__asm__ __volatile__ (LOCK_IF_MP(%4) "cmpxchgq %1,(%3)"
: "=a" (exchange_value)
: "r" (exchange_value), "a" (compare_value), "r" (dest), "r" (mp)
: "cc", "memory");
return exchange_value;
}
// Adding a lock prefix to an instruction on MP machine
#define LOCK_IF_MP(mp) "cmp $0, " #mp "; je 1f; lock; 1: "可以看到,CAS 同样是使用 lock 指令前缀来实现的,那么 lock 指令前缀具体是怎么实现的呢?
1.2.4 LOCK#信号
具体来说,代码中的指令前面声明了 LOCK 前缀指令后,处理器就会在指令运行期间产生 LOCK#信号,使其他处理器不能通过总线访问内存。
我们尝试从 8086 CPU 的引脚图中管中窥豹,了解下 LOCK#信号的原理。

8086 CPU 存在一个 LOCK 引脚(图中 29 号引脚),低电平有效。当声明 LOCK 指令前缀时,会拉低 LOCK 引脚电平,进行 assert 操作,此时其他设备无法获取系统总线的控制权。当 LOCK 指令修饰的指令执行完成后,拉高 LOCK 引脚电平进行 de-assert。
所以整个流程就清晰了,当想要通过非原子指令(例如 add)实现原子操作时,编程时需要在指令前声明 lock 指令前缀,运行时 lock 指令前缀会被处理器识别出来,并产生 LOCK#信号,使其独占内存总线,而其他处理器则无法通过内存总线访问内存,这样就实现了原子操作。所以也就解决了上面的写覆盖问题了。
看起来很好
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









