







动手点关注 干货不迷路 👆
延迟是怎么产生的?
传统直播方案(http-flv、RTMP 等)的架构以及延迟量级如下图所示:

以抖音直播为例,直播链路各环节延迟贡献如下:
推流端——网络延迟平均 20 ~ 30ms,编码延迟依赖编码参数设置而定
流媒体服务——在拉流转码的场景下,会额外引入 300ms ~ 2s 的转码延迟(大小与转码参数相关),如果直接播放源流,则不存在转码延迟
播放端——网络延迟 100ms ~ 200ms 左右,主要是链路分发节点之间的传输延迟;防抖 buffer——5 ~ 8s
从各环节延迟贡献看,容易得出一个直观的结论:端到端延迟过大主要是播放器的防抖 buffer 造成,这个表面现象也经常会导致很多同学,认为降低播放器的 buffer,就能降低延迟。这个说法的对错,取决于从什么角度解释。在辩证这个结论前,我们先详细拆解介绍下直播全链路的延迟:
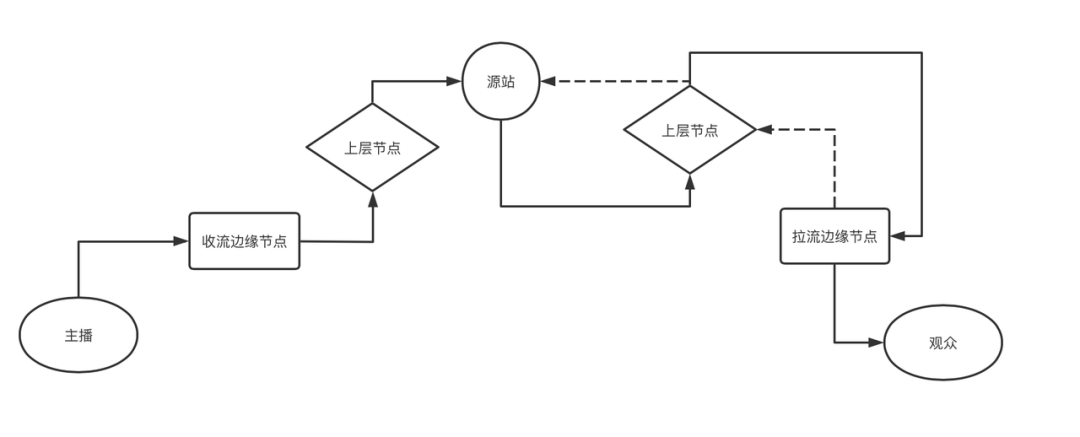
上图主要更细致地拆解了流媒体服务环节,即 CDN 传输链路,拆解为上行(收流节点和上层节点)、源站、下行(上层节点和拉流边缘节点)。各环节延迟归因如下:
主播端(推流器)
主要包含编码延迟以及发送缓存引入的延迟(多数主播网络情况良好,发送缓存延迟平均只有 20 ~ 30ms),这个环节的延迟可优化空间不多,虽然通过调节编码器参数可有效降低编码延迟,但带来的是画质的损失,同时也影响压缩效果,因此多数集中在优化弱网传输(不过出发点是为了提供用户观看流畅体验,而不在于降低延迟)
收流边缘节点&中间链路
针对 http-flv 不需要分片的协议,CDN 传输各节点都是在收到流数据就直接转发到下一个节点,这个环节主要的延迟是由链路传输引起的,与链路长度正相关,一般平均不超过 200ms。
如果播放端拉转码流,那么在网络传输延迟基础之上,会额外增加转码延迟(目前各大 CDN 厂商编码延迟大概分布在 300ms ~ 2s),包括解码延迟和转码延迟,其中对于无 B 帧的场景,解码延迟较小,主要是编码延迟。编码延迟主要是受编码器缓存帧数影响,假设 FPS=15,那么缓存 6 帧,延迟就 400ms,该部分延迟与推流编码延迟一样,同样可以通过调整转码参数来降低转码延迟,但也同样会带来画质与压缩率的损失,因此这部分延迟需要根据实际场景综合来考虑,如果对延迟要求很高,可以调整下。
拉流边缘节点
不考虑回源的情况,这个环节主要影响延迟的是 gop cache 策略(有的 CDN 厂商也叫做快启 buffer 策略或者快启 cache),即在边缘节点缓存一路流最新的几个 gop(一般媒体时长平均为 5 ~ 7s),目的是为了在拉流请求建立时,可以有媒体数据即时发送,优化首帧和卡顿,这样也就导致了播放端收到的第一帧数据就是 5 ~ 7s 前的旧数据,第一帧的延迟就达到了 5 ~ 7s(这个环节才是端到端延迟过大的根因)。
CDN gopCache 的逻辑
字节与 CDN 厂商沟通约定 gop cache 按照下限优先来下发数据,比如下限 6s,表示先在缓存数据中定位最新 6s 的数据,然后向 6s 前的旧数据查找第一个关键帧下发,保证下发第一帧距离最新帧之间的时长不低于 6s:
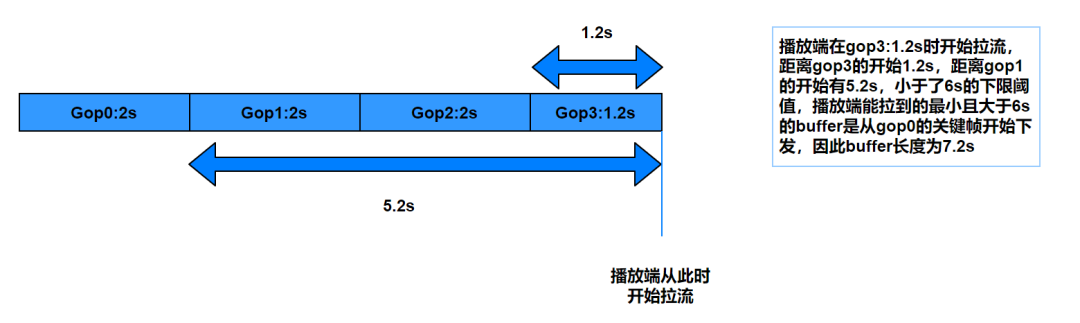
如上图,如果不考虑生产端和中间链路的延迟,那么 buffer 长度 7.2s 可以近似看作播放的初始端到端延迟,在播放器正常播放且无卡顿的前提下,这个延迟会一直持续到退出直播间,不会变化。这里介绍几个初始延迟计算的通用公式:
延迟分布区间[M,M+gop]s,
平均延迟为 M+gop/2,其中 M 为 gopCache 策略的下限,gop 即为编码 gop 的固定大小值
例如抖音秀场 gop 大小是固定的 2s,假设 gopCache 下限为 6s,那么观众的合理端到端延迟分布区间为:[6, 8]s,根据用户请求的时间点,所有观众的延迟都会均匀分布在这个区间内,因此不同观众间的延迟 diff 最大不超过一个 gop 的长度 2s(这点是优化设备间延迟差的理论基础)
观众(播放器)
播放器在 io 模块有分配缓存 buffer(抖音线上分配 buffer 最大为 20s,也就是最多可容纳 20s 的媒体数据,这个 buffer 其实越大越好,抗网络抖动能力也越强),用于存放从 CDN 边缘节点下载到的流媒体数据。播放器下载是主动下载,在可分配的 buffer 队列未充满的前提下,io
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









