






 文章介绍了ApacheAirflow与ByteHouse如何协同工作,提供可扩展且高效的数据流程解决方案。通过Airflow的自动化工作流管理和ByteHouse的云原生数据仓库能力,简化了数据提取、转换和加载过程,支持大规模数据分析和机器学习任务,助力企业实现数据驱动的业务成功。
文章介绍了ApacheAirflow与ByteHouse如何协同工作,提供可扩展且高效的数据流程解决方案。通过Airflow的自动化工作流管理和ByteHouse的云原生数据仓库能力,简化了数据提取、转换和加载过程,支持大规模数据分析和机器学习任务,助力企业实现数据驱动的业务成功。
动手点关注

干货不迷路
Apache Airflow 与 ByteHouse 相结合,为管理和执行数据流程提供了强大而高效的解决方案。本文突出了使用 Apache Airflow 与 ByteHouse 的主要优势和特点,展示如何简化数据工作流程并推动业务成功。
主要优势:
可扩展可靠的数据流程:Apache Airflow 提供了一个强大的平台,用于设计和编排数据流程,让您轻松处理复杂的工作流程。搭配 ByteHouse,一款云原生的数据仓库解决方案,您可以高效地存储和处理大量数据,确保可扩展性和可靠性。
自动化工作流管理:Airflow 的直观界面通过可视化的 DAG(有向无环图)编辑器,使得创建和调度数据工作流程变得容易。通过与 ByteHouse 集成,您可以自动化提取、转换和加载(ETL)过程,减少手动工作量,实现更高效的数据管理。
简单的部署和管理:Apache Airflow 和 ByteHouse 均设计为简单的部署和管理。Airflow 可以部署在本地或云端,而 ByteHouse 提供完全托管的云原生数据仓库解决方案。这种组合使得数据基础设施的设置和维护变得无缝化。
客户场景
业务场景
在这个客户场景中,一家名为“数据洞察有限公司(假名)”的分析公司,他们将 Apache Airflow 作为数据管道编排工具。他们选择 ByteHouse 作为数据仓库解决方案,以利用其强大的分析和机器学习功能。
数据洞察有限公司在电子商务行业运营,并收集存储在 AWS S3 中的大量客户和交易数据。他们需要定期将这些数据加载到 ByteHouse,并执行各种分析任务,以获得对业务运营的洞察。
数据链路
使用 Apache Airflow,数据洞察有限公司设置了一个基于特定事件或时间表的数据加载管道。例如,他们可以配置 Airflow 在每天的特定时间触发数据加载过程,或者当新的数据文件添加到指定的 AWS S3 存储桶时触发。当触发事件发生时,Airflow 通过从 AWS S3 中检索相关数据文件来启动数据加载过程。它使用适当的凭据和 API 集成确保与 S3 存储桶的安全身份验证和连接。一旦数据从 AWS S3 中获取,Airflow 会协调数据的转换和加载到 ByteHouse 中。它利用 ByteHouse 的集成能力,根据预定义的模式和数据模型高效地存储和组织数据。
成功将数据加载到 ByteHouse 后,数据洞察有限公司可以利用 ByteHouse 的功能进行分析和机器学习任务。他们可以使用 ByteHouse 的类 SQL 语言查询数据,进行复杂的分析,生成报告,并揭示有关客户、销售趋势和产品性能的有意义洞察。
此外,数据洞察有限公司还利用 ByteHouse 的功能创建交互式仪表板和可视化。他们可以构建动态仪表板,显示实时指标,监控关键绩效指标,并与组织中的利益相关者共享可操作的洞察。
最后,数据洞察有限公司利用 ByteHouse 的机器学习功能来开发预测模型、推荐系统或客户细分算法。ByteHouse 提供了必要的计算能力和存储基础设施,用于训练和部署机器学习模型,使数据洞察有限公司能够获得有价值的预测性和规定性洞察。
总结
通过使用 Apache Airflow 作为数据管道编排工具,并将其与 ByteHouse 集成,数据洞察有限公司实现了从 AWS S3 加载数据到 ByteHouse 的流畅自动化流程。他们充分利用 ByteHouse 的强大分析、机器学习和仪表板功能,获得有价值的洞察,并推动组织内的数据驱动。
ByteHouse<>AirFlow 快速入门
先决条件
在您的虚拟/本地环境中安装 pip。在您的虚拟/本地环境中安装 ByteHouse CLI 并登录到 ByteHouse 账户。参考 ByteHouse CLI 以获取安装帮助。macOS 上使用 Homebrew 的示例:
brew install bytehouse-cli安装 Apache Airflow
在本教程中,我们使用 pip 在您的本地或虚拟环境中安装 Apache Airflow。了解更多信息,请参阅官方 Airflow 文档。
# airflow需要一个目录,~/airflow是默认目录,
# 但如果您喜欢,可以选择其他位置
#(可选)
export AIRFLOW_HOME=~/airflow
AIRFLOW_VERSION=2.1.3
PYTHON_VERSION="$(python --version | cut -d " " -f 2 | cut -d "." -f 1-2)"
# 例如:3.6
CONSTRAINT_URL="https://raw.githubusercontent.com/apache/airflow/constraints-${AIRFLOW_VERSION}/constraints-${PYTHON_VERSION}.txt"
pip install "apache-airflow==${AIRFLOW_VERSION}" --constraint "${CONSTRAINT_URL}"如果使用 pip 无法安装,请尝试使用 pip3 install 进行安装。
安装完成后,运行命令 airflow info 以获取有关 Airflow 的更多信息。
Airflow 初始化
通过执行以下命令来初始化 Airflow 的 Web 服务器:
# 初始化数据库
airflow db init
airflow users create \
--username admin \
--firstname admin \
--lastname admin \
--role Admin \
--email admin
# 启动Web服务器,默认端口是8080
# 或修改airflow.cfg设置web_server_port
airflow webserver --port 8080设置好 Web 服务器后,您可以访问 http://localhost:8080/ 使用先前设置的用户名和密码登录 Airflow 控制台。
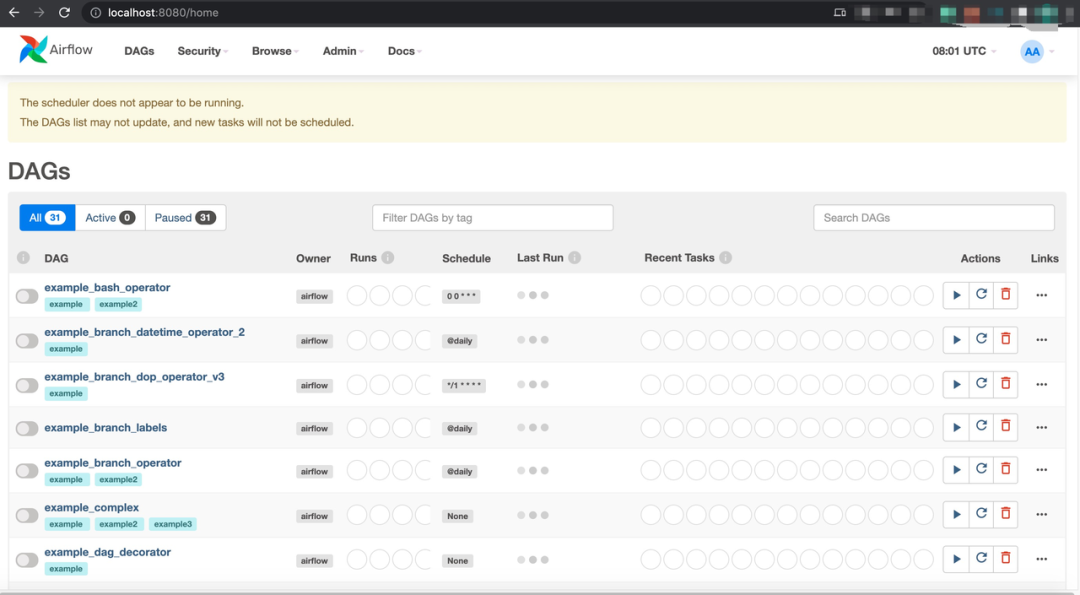
在新的终端中,使用以下命令设置 Airflow 调度器。然后,刷新http://localhost:8080/。
YAML 配置
使用 cd ~/airflow 命令进入 Airflow 文件夹。打开名为 airflow.cfg 的配置文件。
添加配置并连接到数据库。默认情况下,您可以使用 SQLite,但也可以连接到 MySQL。
# 默认情况下是SQLite,也可以连接到MySQL
sql_alchemy_conn = mysql+pymysql://airflow:airflow@xxx.xx.xx.xx:8080/airflow
# authenticate = False
# 禁用Alchemy连接池以防止设置Airflow调度器时出现故障 https://github.com/apache/airflow/issues/10055
sql_alchemy_pool_enabled = False
# 存放Airflow流水线的文件夹,通常是代码库中的子文件夹。该路径必须是绝对路径。
dags_folder = /home/admin/airflow/dags创建有向无环图(DAG)作业
在 Airflow 路径下创建一个名为 dags 的文件夹,然后创建 test_bytehouse.py 以启动一个新的 DAG 作业。
~/airflow
mkdir dags
cd dags
nano test_bytehouse.py在 test_bytehouse.py 中添加以下代码。该作业可以连接到 ByteHouse CLI,并使用 BashOperator 运行任务、查询或将数据加载到 ByteHouse 中。
from datetime import timedelta
from textwrap import dedent
from airflow import DAG
from airflow.operators.bash import BashOperator
from airflow.utils.dates import days_ago
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'email': ['airflow@example.com'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5),
}
with DAG(
'test_bytehouse',
default_args=default_args,
description='A simple tutorial DAG',
schedule_interval=timedelta(days=1),
start_date=days_ago(1),
tags=['example'],
) as dag:
tImport = BashOperator(
task_id='ch_import',
depends_on_past=False,
bash_command='$Bytehouse_HOME/bytehouse-cli -cf /root/bytehouse-cli/conf.toml "INSERT INTO korver.cell_towers_1 FORMAT csv INFILE '/opt/bytehousecli/data.csv' "',
)
tSelect = BashOperator(
task_id='ch_select',
depends_on_past=False,
bash_command='$Bytehouse_HOME/bytehouse-cli -cf /root/bytehouse-cli/conf.toml -q "select * from korver.cell_towers_1 limit 10 into outfile '/opt/bytehousecli/dataout.csv' format csv "'
)
tSelect >> tImport在当前文件路径下运行 python test_bytehouse.py 以在 Airflow 中创建 DAG。
在浏览器中刷新网页。您可以在 DAG 列表中看到新创建的名为 test_bytehouse的 DAG。
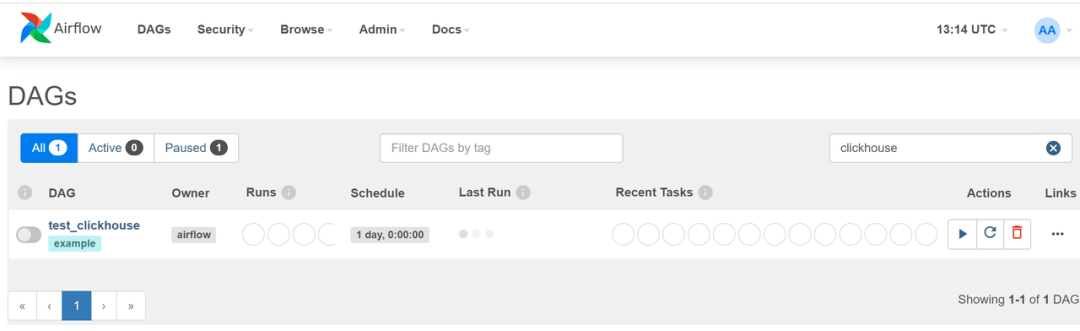
执行 DAG
在终端中运行以下 Airflow 命令来查看 DAG 列表和 test_bytehouse DAG 中的子任务。您可以分别测试查询执行和数据导入任务。
#打印"test_bytehouse" DAG中的任务列表
[root@VM-64-47-centos dags]# airflow tasks list test_bytehouse
ch_import
ch_select
#打印"test_bytehouse" DAG中任务的层次结构
[root@VM-64-47-centos dags]# airflow tasks list test_bytehouse --tree
<Task(BashOperator): ch_select>
<Task(BashOperator): ch_import>运行完 DAG 后,查看您的 ByteHouse 账户中的查询历史页面和数据库模块。您应该能够看到查询/加载数据成功执行的结果。
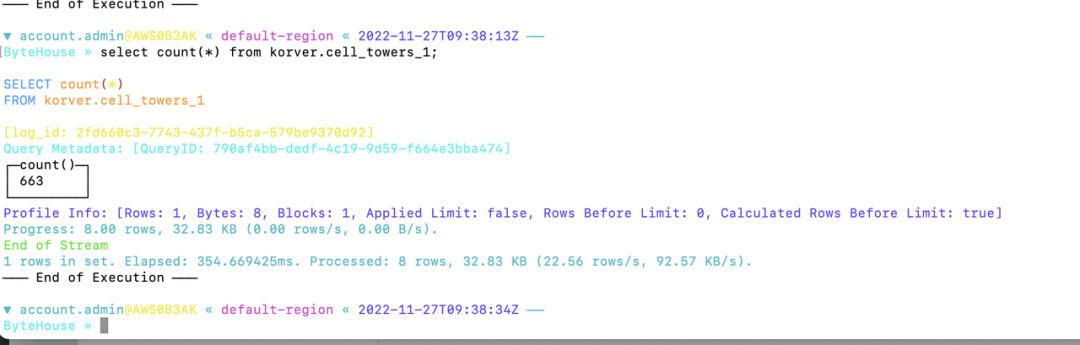
关于火山引擎 ByteHouse
ByteHouse 是字节跳动自主研发的云原生数据仓库产品,在开源 ClickHouse引擎之上做了技术架构重构,实现了云原生环境的部署和运维管理、存储计算分离、多租户管理等功能。在可扩展性、稳定性、可运维性、性能以及资源利用率方面都有巨大的提升。ByteHouse 在字节跳动内部部署规模超过 1 万 8000 台,单集群超过 2400 台。经过内部数百个应用场景和数万用户锤炼,并在多个外部企业客户中得到推广应用。
了解更多技术干货、最新活动,欢迎扫码进入官方交流群

 点击「阅读原文」即刻体验
点击「阅读原文」即刻体验


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









