






2.4.1.2. HTML源码分析
Web端站点和M端站点返回结果都是HTML格式,部分站点为了提升页面渲染速度,或者为了增加代码分析难度,通过动态JavaScrip执行等方式,动态生成HTML页面,网络爬虫缺少JS执行和渲染过程,很难获取真实的数据,微博Web端站点HTML代码片段如下所示:

脚本中的正文内容:

M端站点HTML内容:
M端HTML内容中并未出现页面中的关键信息,可以判定为前后端分离的设计方式,通过Chrome浏览器开发模式,能够查看所有请求信息,通过请求的类型和返回结果,基本可以确定接口地址,查找过程如下图所示:
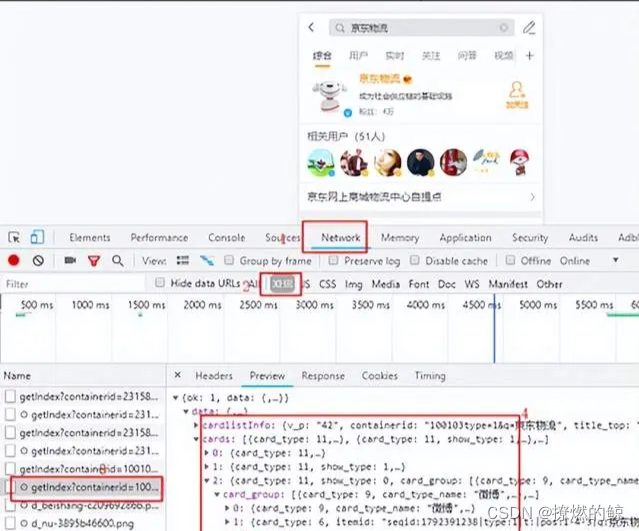
注:图片来源于微博M端截图
(1) 打开Chrome开发者工具,刷新当前页面;
(2) 修改请求类型为XHR,筛选Ajax请求;
(3) 查看所有请求信息,忽略没有返回结果的接口;
(4) 在接口返回结果中查找页面中相关内容。
2.4.1.3. 接口分析
接口分析主要包括:请求地址分析、请求方式、参数列表、返回结果等。
请求地址、请求方式和参数列表可以根据Chrome开发人员工具中的网络请求Header信息获取,请求信息如下图所示:
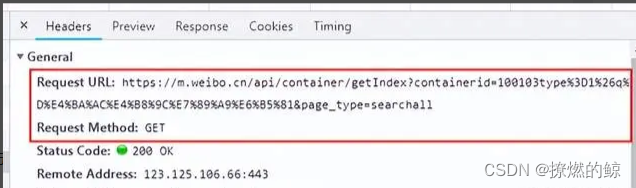
上图中接口地址采用的是GET方式请求,请求地址是unicode编码,参数内容可以查看Query String Parameters列表查看请求参数,效果如下图所示:

请求结果分析主要分析数据结构的特点,查找与正文内容相同的数据结构,同时要检查所有结果是否与正文内容一致,避免特殊返回结果影响数据解析过程。
2.4.1.4. 接口验证
接口验证一般需要两个步骤:
(1)用浏览器(最好是新开浏览器,如Chrome的隐身模式)模拟请求过程,在地址栏中输入带有参数的请求地址查看返回结果。
(2)采用Postman等工具模拟浏览器请求过程,主要模拟非Get方式的网络请求,同样也可以验证站点是否强制使用Cookie和User-Agent信息等。
2.4.2. 定义数据结构
爬虫数据结构定义主要结合业务需求和数据抓取的结果进行设计,微博数据主要用户国内的舆情系统,所以在开发过程中将相关站点的数据统一定义为OpinionItem类型,在不同站点的数据保存过程中,按照OpinionItem数据结构的特点装配数据。在items.py文件中定义舆情数据结构如下所示:















 2640
2640

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









