










最近才开始看d2l(这种东西早该在两年前看的,拖到现在了)
为了做项目还得学一手OpenGL(被windows安装GLFW逼疯了)
1.15
打完ICPC EC final回来,也许可以出一篇博客写下简单的题解。
对蛋白质相似空间子结构搜索的算法有了一些思路,简单分为传统算法和目标检测算法
1.16
想到要对蛋白质可视化,然后去找可以用于三维绘图的库,找到了OpenGL,在wsl里面装了一个,发现挺方便,准备开始学[傅老師/OpenGL教學 第一章] OpenGL自製3D遊戲引擎 (已更畢)_哔哩哔哩_bilibili
然后发现蛋白质三维结构是需要跑alphafold的(自己电脑根本跑不了),还不如直接下载网上的已经预测好结构的数据集。
1.17
1、UniProt
学习了UniProt网站的一些知识,还有待进一步探索
struct里面可以查看各种蛋白质的三维结构,蛋白质数据都是可以下载的
标了reviewed的数据可信度更高,做实验优先选择这类数据
2、蛋白质三维结构比对算法
主要分为分子间距离比较和分子内距离比较。
分子间距离比较就类似迭代的做法,通过刚体旋转使得蛋白质分子间的cRMS指标最小
分子内距离dRMS的判据一般用于蛋白质的局部空间结构比较,可以绕过刚体旋转拟合的过程
结构比对算法已经有很多优秀的算法了,比如CE、TM-align、DALI、VAST、K2、SHEBA等之类的,似乎不用自己再写一个了。
1.18
查看网络情况
ipconfig,ping+网址,ss,ip link。
查看conda环境列表:conda env list
删除conda环境:conda env remove --name xxx(必须在非激活状态下删除)
创建conda环境:conda create --name xxx python=3.x
激活conda环境:conda activate xxx
在某环境下安装某个包:直接pip install
d2l网站,之前找了好久都没找到,今天一找就找到了:安装 — 动手学深度学习 2.0.0 documentation
1.19
滑动窗口维护次大值
一个神奇的方法,单调队列,每次把z加入队列时比较队尾的两个元素x,y,
若z>=x&&z>=y,弹出x、y中的较小值,直到不满足该条件后,将z加入队尾
这样可以保证,区间最大值一定是前两个数之一,次大值一定是前四个数之一。
为什么呢
用反证法,最大值在第三位,那么,1、2位都会小于第三位,那么应该弹出1、2位之一,矛盾。
若次大值在第五位,那么1234位中一定有三位小于次大值,而最大值一定在1、2位,所以3、4位一定小于第五位的次大值,那么3、4位必定弹出一个,矛盾。
综上以上维护方式可以维护最大值与次大值。
yyq%%%%%我直接膜爆yyq,这么多年了,他还在c!他还在输出!yyq yyds!!!
1.20
休息日,和yyq打MC,发现金头盔可以避免自己被猪灵攻击。
1.21
看Struct2GO论文,看d2l
python os模块学习:第26天:Python 标准库之 os 模块详解 - 纯洁的微笑博客
和操作系统实验里面写的函数用法几乎一模一样,使得python可移植性很强。
将pandas的dataframe数据类型转换为tensor(先转numpy再转tensor)
A=torch.tensor(xx.to_numpy(dtype=xxx))(xx为dataframe类型的变量)
d2l笔记:
数据预处理,离散缺失值一般单独分一类或者用众数代替,连续缺失值可以用平均数或者众数代替。
torch.arange(n,dtype=xxxx)(生成0~n-1的数据类型为xxxx的一串数)
设A、B为tensor张量
A.reshape(n,m,……)(保证数据总数不变的情况下对数据进行变形)
A.sum(axis=0、1)(按照行、列求和)
A.cumsum(axis=0、1)(按照行列进行前缀和计算)
A+B,对应位置相加
A*B ,Hadamard积,就是对应位置相乘
torch.dot(A,B)向量点积
torch.mv(A,B)矩阵乘向量(A为矩阵n*m,B为向量m,乘出来为一个n维列向量)
(mv表示matrix*vector)
torch.mm(A,B)矩阵乘法,不解释
范数复习:
向量范数:

矩阵范数:F、1、2、∞
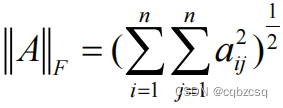

![]()
范数性质:

![]() (矩阵范数特有)
(矩阵范数特有)
torch.norm(A):计算向量A的2范数、矩阵A的F范数
torch.abs(A).sum():计算向量的1范数
1.22
学了一些分类模型的指标,写了个博客机器学习分类模型评价指标总结(准确率、精确率、召回率、Fmax、TPR、FPR、ROC曲线、PR曲线,AUC,AUPR)-CSDN博客
用gpt写了个代码,用神经网络来拟合简单的函数,结果发现好容易过拟合,bbzl
不过作为一个上手的demo还是很不错的
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
# 定义一个三层的多层感知机模型
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.fc1 = nn.Linear(1, 3) # 输入层到隐藏层
self.fc2 = nn.Linear(3, 3) # 隐藏层到隐藏层
self.fc3 = nn.Linear(3, 1) # 隐藏层到输出层
def forward(self, x):
x = torch.sigmoid(self.fc1(x))
x = torch.sigmoid(self.fc2(x))
x = self.fc3(x)
return x
# 创建训练数据集
x_train = torch.unsqueeze(torch.linspace(-5, 5, 100), dim=1)
y_train = torch.sin(x_train)
# 创建模型实例、损失函数和优化器
model = MLP()
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.01)
# 开始训练
num_epochs = 2000
for epoch in range(num_epochs):
output = model(x_train)
loss = criterion(output, y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch + 1) % 2500 == 0:
print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}")
# 绘制拟合曲线
x_test = torch.unsqueeze(torch.linspace(-5, 5, 100), dim=1)
y_real = torch.sin(x_test)
y_pred = model(x_test)
plt.plot(x_test, y_real, 'r-', label='Original data')
plt.plot(x_test, y_pred.detach().numpy(), 'b-', label='Fitted line')
plt.xlabel('x')
plt.ylabel('y')
plt.legend()
plt.show()1.23
上午看struct2go论文,下午晚上打游戏,摆烂了一天
1.24
把struct2go论文看完了,有好多地方不太理解,问学长,学长说是其他论文里面的一些方法,让我看一下其他论文。DeepFRI,node2vec,NBR建图方法,SeqVec
长度单位:埃=0.1纳米,肽键长度为0.132纳米,大约是1.32埃
主成分分析
对于拥有p维属性的n条数据,计算属性的协方差矩阵p*p
然后求协方差矩阵的特征值和特征向量
从大到小对特征值排序,依次从前往后选择对应特征向量,当当前特征值之和超过总和的80%时,就停止选择,选出来的这一系列特征向量成为主成分
struct2go论文整体思路不难理解
先是预处理,用alphafold2算出来的蛋白质结构,三维空间中进行建图,对每个氨基酸残基用独热编码作为节点属性,再用node2vec算一遍节点嵌入,得到初始的图。
然后是网络层,只有两层,主要结构都是先对图做GCN,然后做自注意力池化(一共只做了两层)。
最后和序列处理的信息融合起来(序列信息直接用的SeqVec),做多标签分类。
实验结果,和其他蛋白质GO标签预测模型相比Fmax、AUC、AUPR三个指标都很不错,从消融实验来看,应该是蛋白质结构信息的贡献最大。但是BP标签上面略有瑕疵,之后的研究估计可以从融合PPI网络数据等方面来入手。
具体细节还需要看代码才能理解,就当成是知识积累吧。
2小时44分钟读完一篇,挺累人。中途一直在查资料,人麻了。
1.25~1.28
摆了四天
1.29
看了点书:把基因组注释看完了,感觉也没理解到什么关键的东西,看到转录组学了,学了一下RNA测序的方法RNA-seq,感觉好难,头大
1.30
又摆烂一天,发现高中同学去参加最强大脑了,令人感叹
1.31
把d2l的第三章做完了。
python zip()和enumerate()功能,把两个序列压倒一起做for循环 | 给枚举前面加入当前序号
python assert 表达式,要输出的提示信息

发现今天竟然是yuanshen4.4更新,绷不住了,启动!















 1439
1439











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









