






首先,秘塔写作猫是利用智能AI写作功能帮大家完成各种写作,集AI写作,多人协作,文本校对,改写润色,自动配图等功能为一体AI Native的内容创作平台,这绝对是一个写作神器。
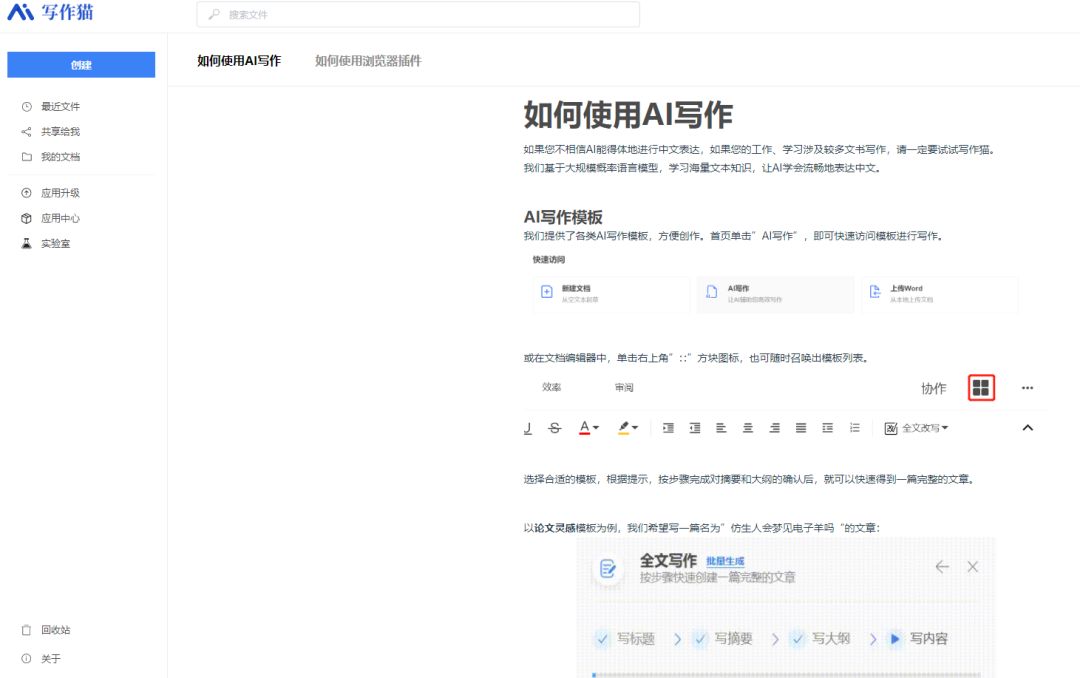
最开始不会使用的小伙伴,我们可以先看下如果使用AI写作简单学习下,这里有详细的说明。
使用起来还是挺方便的,点击新建文档,输入需要写的主题,也可以输入“//”唤起指令框,选择弹窗的模板。
选择好模板,咱们就可以先输入想要写的内容,一键即可生成,生成速度很快,生成的文章准确性非常高,

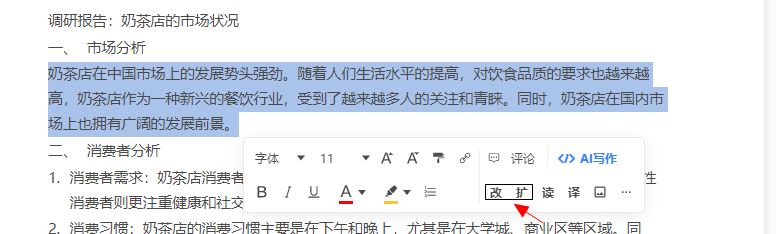
它的改写和扩写功能也是超级实用的,如果加载出来的内容有些不满意的,我们可以选择那部分文字点击弹窗上的改写或者扩写进行修改。
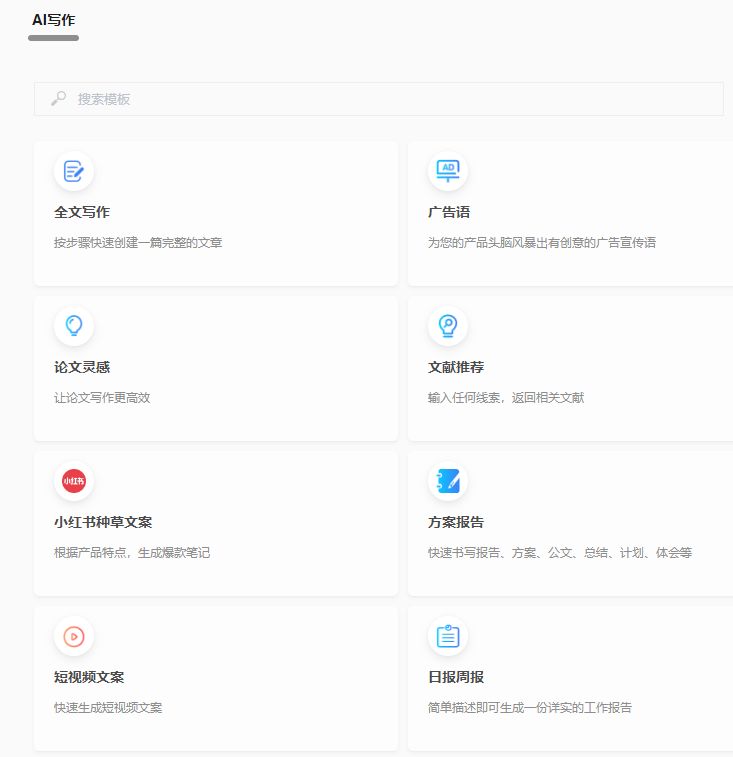
AI写作的含盖的范围非常的广,包含了全文写作,广告语,论文灵感,文献推荐,小红书种草文案,方案报告,短视频文案,日报周报,头脑风暴,AI绘图,产品评论,文章裂变,批量生成,诗歌,小说,作文,句子续写等等。
秘塔写作猫 网址:https://xiezuocat.com/?s=feng
请将链接复制到浏览器打开

















 549
549

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









