









数据结构和算法——树(1)
一、二叉树
二叉树是一种最简单的树形结构,它的特点是树中的每个结点最多关联到两个后继结点,也就是说,一个结点它可以有0、1、2个后继结点。此外,其后继结点有明显的左右之分。
这里面有一些相关的名词:空树、单点树、父结点、子结点、父子关系、祖先/子孙关系、祖先结点、子孙结点、兄弟结点、分支结点等在这里就不做解释了,主要看代码的实现。
1.1 二叉树的结点结构定义
使用list方式来表示[val, left, right]。
例如,我们可以这样表示一棵树:
[1, [2, None, None], [3, None, None]]
"""
1
/ \
2 3
"""
下面是使用类来定义二叉树的一个结点:
class BinTreeNode:
def __init__(self, val, left=None, right=None):
self.val = val # 值
self.left = left # 左孩子
self.right = right # 右孩子
1.2 二叉树的建立
首先是最简单的建立方式,直接按关系定义
root = BinTreeNode(1)
root.left = BinTreeNode(2)
root.right = BinTreeNode(3)
"""
1
/ \
2 3
"""
这样我们就简单定义了一个树,该树有三个结点,根结点为1,其左孩子为2,其右孩子为3。
def create_tree():
a = input('Enter a key: ')
if a == '#':
root = None
else:
root = BinTreeNode(a)
root.left = create_tree()
root.right = create_tree()
return root
按照前序遍历的方式创建一棵二叉树,当结点为空时用’#'表示。
def create_tree_from_list(node_list):
if node_list is None:
root = None
elif node_list[0] == None:
node_list.pop(0)
root = None
else:
root = BinTreeNode(node_list.pop(0))
root.left = create_tree_from_list(node_list)
root.right = create_tree_from_list(node_list)
return root
bt = create_tree_from_list(['a', 'b', 'c', None, None, 'd', None, None, 'e', 'f', None, None, None])
print(bt.right.left.val)
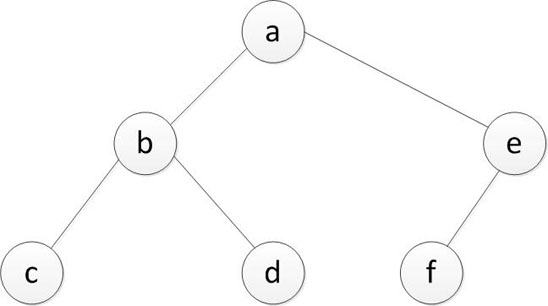
直接根据列表中的数据创建一个二叉树,要注意在没有结点的位置用None表示,不能落下。
1.3 二叉树的遍历方式
-
先序遍历:按照根-左-右的顺序遍历。
def preorder(root): """ 前序遍历 :param root: :return: """ if root is None: return else: print(root.val) preorder(root.left) preorder(root.right) -
中序遍历:按照左-根-右的顺序遍历。
def inorder(root): """ 中序遍历 :param root: :return: """ if root is None: return else: inorder(root.left) print(root.val) inorder(root.right) -
后序遍历:按照左-右-根的顺序遍历。
def postorder(root): """ 后序遍历 :param root: :return: """ if root is None: return else: postorder(root.left) postorder(root.right) print(root.val) -
层序遍历:按照从上到下的顺序遍历一棵二叉树,在实现的时候需要使用队列,在这里简单使用一个
list来代替队列。def level_traversal(root): queue = [root] traveled_list = [] while queue: tree_node = queue.pop(0) if tree_node: traveled_list.append(tree_node.val) queue.append(tree_node.left) queue.append(tree_node.right) return traveled_list -
先序遍历的非递归实现思路:需要用到栈来实现,从栈顶取出结点,如果该结点不为空,则访问该结点,同时把该结点的右孩子入栈,然后左孩子入栈,当栈为空时跳出循环。
def no_recur_preorder(root): if not root: return [] stack = [root] result_list = [] while stack: tmp_node = stack.pop() if tmp_node: result_list.append(tmp_node.val) stack.append(tmp_node.right) stack.append(tmp_node.left) return result_list -
中序遍历的非递归实现思路:同样需要用栈来实现,需要先把根结点入栈,然后一直把左孩子入栈,直到左孩子为空。此时,栈顶结点就是我们要访问的结点,取出栈顶结点,并访问,然后判断该结点是否有右孩子,如果有,则将其入栈,重复根结点入栈时的操作,如果没有,则继续取出栈顶元素。
def no_recur_inorder(root): if not root: return [] stack = [] p = root result_list = [] while p or stack: while p: stack.append(p) p = p.left p = stack.pop() result_list.append(p.val) if p.right: p = p.right else: p = None return result_list -
后序遍历的非递归实现思路:这同样也是需要用栈来实现,先把根结点入栈,然后再将其左孩子入栈,直到左孩子为空,在入栈时,要给每个结点分配一个标志位,当遍历该结点的左孩子时,将标志位设为0,当要遍历该结点的右孩子时,设置当前结点的标志位为1,当遍历完成时,在该结点出栈时,查看该结点的标志位,如果为0,表示该结点的右孩子还没有遍历,则需要将该结点再次入栈,并且标志位设置为1,然后以该结点的右孩子为根结点,重复上述操作;如果标志位为1,则说明该结点的左右孩子都已经遍历完成,可以访问该结点。
def no_recur_postorder(root): if not root: return [] stack = [] p = root result_list = [] while p or stack: while p: stack.append([p, 0]) p = p.left p, tag = stack.pop() if tag == 0: stack.append([p, 1]) p = p.right else: result_list.append(p.val) p = None return result_list
二、优先队列
2.1 什么是优先队列
优先队列与正常的队列类似,可以进行入队和出队等操作,但是优先队列有一个特点,就是存入其中的每个数据项都有一个数值来表示这个项的优先级,在进行出队操作时,总是能够保证优先级最高的项能够优先被访问或出队列。
2.2 优先队列的实现方式
2.2.1 使用Python中的list来实现。
class PrioQue:
def __init__(self, elist=[]):
self._elems = list(elist)
self._elems.sort(reverse=True)
def enqueue(self, e):
i = len(self._elems) - 1
while i >= 0:
if self._elems[i] <= e:
i -= 1
else:
break
self._elems.insert(i + 1, e)
def is_empty(self):
return not self._elems
def peek(self):
if self.is_empty():
raise ValueError('The Queue is Empty.')
return self._elems[-1]
def dequeue(self):
if self.is_empty():
raise ValueError('The Queue is Empty.')
return self._elems.pop()
def __len__(self):
return len(self._elems)
使用list来实现优先队列时,除了插入数据时使用的是O(N)时间复杂度,其它操作的时间复杂度都是O(1)。
2.2.2 使用堆来实现优先队列
采用树形结构来实现优先队列的技术成为堆。我们常见的堆结构通常是一棵完全二叉树,在存储数据时会满足一种特定的顺序,即:任意一个结点里所存储的数据先于或等于其子结点(如果存在)里的数据。
class PrioQueue:
def __init__(self, elist=[]):
self._elems = list(elist)
if elist:
self.buildheap()
def buildheap(self):
end = len(self._elems)
for i in range(end // 2, -1, -1):
self.siftdown(self._elems[i], i, end)
def is_empty(self):
return not self._elems
def peek(self):
if self.is_empty():
raise ValueError('The Queue is Empty.')
return self._elems[0]
def enqueue(self, e):
self._elems.append(e)
self.siftup(e, len(self._elems) - 1)
def siftup(self, e, last):
elems, i, j = self._elems, last, (last - 1) // 2
while i > 0 and e < elems[j]:
elems[i] = elems[j]
i, j = j, (j - 1) // 2
elems[i] = e
def dequeue(self):
if self.is_empty():
raise ValueError('The Queue is Empty.')
elems = self._elems
e0 = elems[0]
e = elems.pop()
if len(elems) > 0:
self.siftdown(e, 0, len(elems))
return e0
def siftdown(self, e, begin, end):
elems, i, j = self._elems, begin, begin * 2 + 1
while j < end:
if j + 1 < end and elems[j + 1] < elems[j]:
j += 1
if e < elems[j]:
break
elems[i] = elems[j]
i, j = j, 2 * j + 1
elems[i] = e
参考自书《数据结构与算法 Python语言描述》
基于堆实现的优先队列创建操作的时间复杂度为O(N),入队和出队操作的时间复杂度为O(log N),效率比较高。
三、哈夫曼树
设实数集W={w0, w1, …, wm-1},T是一棵扩充二叉树,其m个外部结点分别以wi(i=1, 2, …, m-1)为权,而且T的带权外部路径长度WPL在所有这样的扩充二叉树中达到最小,则称T为数据集W的最优二叉树或者哈夫曼树。
3.1 构造哈夫曼树的算法
算法的输入为实数集W={w0, w1, …, wm-1},在构造的过程中维护一棵包含k棵二叉树的集合F,开始时k=m,并且F={T0, T1, …, Tm-1},其中每个Ti是一棵只包含权重为wi的根结点的单点二叉树。
算法的整个过程中重复执行以下两个步骤,直到F中只剩下一棵树为止:
- 构造一棵新二叉树,其左右子树是从集合F中选取的两棵权最小的二叉树,其根结点的权值设置为这两棵子树的根结点的权值之和。
- 将所选的两棵二叉树从F中删除,把新构造的二叉树加入F。
3.2 哈夫曼算法的实现
实现哈夫曼算法会用到一个优先队列,以权重值作为优先级存入优先队列,从优先队列中弹出两棵有最小权重值的树,然后将两者生成的新树放入优先队列中,循环执行上述操作,直到优先队列中只有一棵树。
class HTreeNode:
def __init__(self, data, lchild=None, rchild=None):
self.data = data
self.lchild = lchild
self.rchild = rchild
def __lt__(self, other):
return self.data < other.data
def create_huffman_tree(weights):
"""
构建哈夫曼树
:param weights:
:return:
"""
trees = PrioQueue()
for w in weights:
trees.enqueue(HTreeNode(w))
while len(trees) > 1:
t1 = trees.dequeue()
t2 = trees.dequeue()
x = t1.data + t2.data
trees.enqueue(HTreeNode(x, t1, t2))
return trees.dequeue()
def travel_leaves(root):
"""
遍历叶子结点
:param root:
:return:
"""
if not root:
return
if not root.lchild and not root.rchild:
print(root.data)
travel_leaves(root.lchild)
travel_leaves(root.rchild)
root = create_huffman_tree([2, 3, 7, 10, 4, 2, 5])
travel_leaves(root)
四、二叉排序树(二叉搜索树)
二叉排序树又称二叉搜索树或者二叉查找树。
二叉排序树或者为一棵空树,或者是具有以下性质的二叉树:
- 若左子树不空,则左子树上所有的结点的值均小于它的根结点的值;
- 若右子树不空,则右子树上所有的结点的值均大于或等于它的根结点的值;
- 左右子树均为二叉排序树。
4.1 二叉排序树插入
思路:从根结点开始对比,如果要插入的元素比该结点元素大,则继续跟其右孩子结点对比,如果比该结点元素小,则继续跟其左孩子结点对比,直到没有可对比元素,则将要插入的元素插入。
4.2 二叉排序树查找
思路:从根结点开始对比,如果查找的元素比该结点元素大,则继续跟其右孩子结点对比,如果比该结点元素小,则继续跟其左孩子结点对比,如果相等,则返回True,最后没有可以对比的元素,则返回False。
4.3 二叉排序树删除
删除结点时会出现以下三种情况:
- 删除的结点为叶子结点:这样直接删除就可以
- 删除的结点左子树为空或者右子树为空:直接将不为空的树放到父结点上即可
- 删除的结点左子树和右子树都不为空:让左子树中的最大的结点来替换要删除的结点,然后将左子树的最大结点删除。
4.4 二叉排序树及其操作的实现
class TreeNode:
def __init__(self, val, lchild=None, rchild=None):
self.val = val
self.lchild = lchild
self.rchild = rchild
class BST:
def __init__(self, nums_list=[]):
self.root = None
for num in nums_list:
self.insert(num)
def insert(self, data):
"""
向二叉排序树中插入新结点
"""
p = self.root
if p is None:
self.root = TreeNode(data)
return
while p:
if p.val <= data:
if p.rchild is None:
p.rchild = TreeNode(data)
break
p = p.rchild
else:
if p.lchild is None:
p.lchild = TreeNode(data)
break
p = p.lchild
def search(self, data):
"""
查找二叉排序树中的结点
"""
bt = self.root
while bt:
if bt.val < data:
bt = bt.rchild
elif bt.val > data:
bt = bt.lchild
else:
return True
return False
def delete_data(self, data):
"""
删除二叉排序树中的结点
"""
if self.root is None:
return
cur = self.root
parent = None
while cur and cur.val != data:
parent = cur
if cur.val > data:
cur = cur.lchild
else:
cur = cur.rchild
if not cur.lchild and not cur.rchild:
if parent.lchild == cur:
parent.lchild = None
else:
parent.rchild = None
elif cur.lchild and cur.rchild:
max_node_p = None
max_node = cur.lchild
while max_node.rchild:
max_node_p = max_node
max_node = max_node.rchild
cur.val = max_node.val
if max_node_p:
max_node_p.rchild = max_node.lchild
else:
cur.lchild = None
else:
if parent.lchild == cur:
if cur.lchild:
parent.lchild = cur.lchild
else:
parent.lchild = cur.rchild
else:
if cur.lchild:
parent.rchild = cur.lchild
else:
parent.rchild = cur.rchild
如有错误欢迎批评指正!!















 25万+
25万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









