






Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments 2017 NIPS MADDPG
背景介绍跳过,相关方法跳过,我的主页有
https://arxiv.org/abs/1706.02275
本文的主要贡献
提出了一种通用的多智能体学习算法,具有以下特点:
-
学习到的策略在执行时仅使用局部信息(即自身观测);
-
不假设环境动力学模型的可微性或智能体间通信方式的特定结构;
-
不仅适用于合作交互,还适用于涉及物理和通信行为的竞争或混合交互。在混合合作-竞争环境中行动的能力对智能体可能至关重要;虽然竞争性训练为学习提供了自然课程,但智能体在执行时也必须表现出合作行为(例如与人类合作)
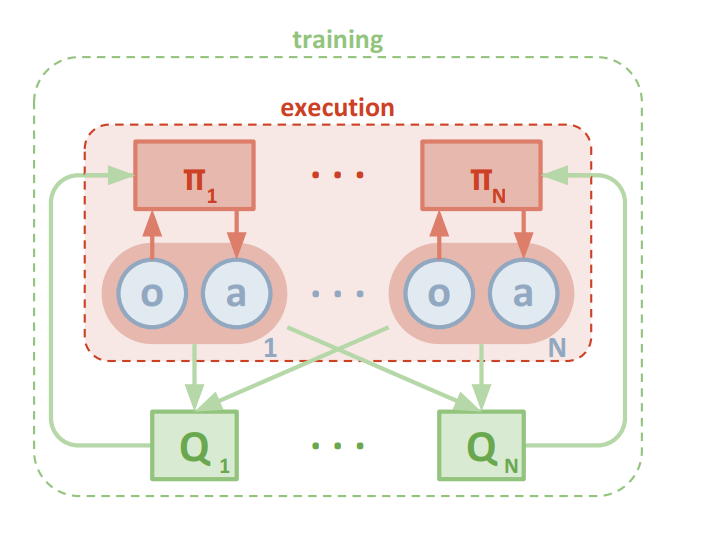
采用一种集中式训练与分布式执行的框架,允许策略在训练过程中使用额外的信息,只要在测试时不使用这些信息。通过对演员-评论家策略梯度方法的扩展,评论家可以获取其他智能体策略的额外信息,而演员只能访问局部信息。这种方法在训练完成后,只使用局部演员进行分布式执行,同时适用于合作和竞争环境
该算法可以在线学习其他智能体的近似模型,并在其自身的策略学习过程中有效地使用它们。此外,还引入了一种通过使用每个智能体的策略集合进行训练来提高多智能体策略稳定性的方法。实证研究表明,该方法在合作和竞争场景中相对于现有方法具有优势。
方法
4 Multi-Agent Actor Critic
文章先提出了基本的设定
-
学习到的策略在执行时只能使用局部信息(即它们自己的观察);
-
我们不假设环境动力学模型的可变性
-
我们不对智能体之间的通信方法做任何特定的结构假设
提出了一种新的基于actor-critic策略梯度方法的扩展,以解决Q-learning中的一些限制
- 采用集中式训练与分布式执行框架。
- 策略在训练时可以使用额外信息,但在测试时不使用。。
- 在这种扩展中,critic使用其他代理的策略的额外信息进行增强。
这里假设一个有n个参与者的游戏,其中有N个参数,N个策略参数记作
θ
=
{
θ
1
,
.
.
.
,
θ
N
}
\theta=\{\theta1,...,\theta_N\}
θ={θ1,...,θN}
N个智能体的策略记作
π
=
=
{
π
1
,
.
.
.
,
π
N
}
\pi==\{\pi1,...,\pi_N\}
π=={π1,...,πN}
数学推理建议看原文
5 实验
实验环境包括N个智能体和L个地标,它们位于一个具有连续空间和离散时间的二维世界中。代理可以在环境中采取物理行动,并进行通信行动,这些通信行动会广播给其他智能体。与不同,作者并不假设所有智能体具有相同的动作和观察空间,或者根据相同的策略π行动。此外,作者还考虑了既合作(所有智能体必须最大化共享回报)又竞争(智能体具有相互冲突的目标)的游戏。在某些环境中,代智能体要进行明确的通信以获得最佳奖励,而在其他环境中,智能体只能执行物理行动。
实验环境的示例:
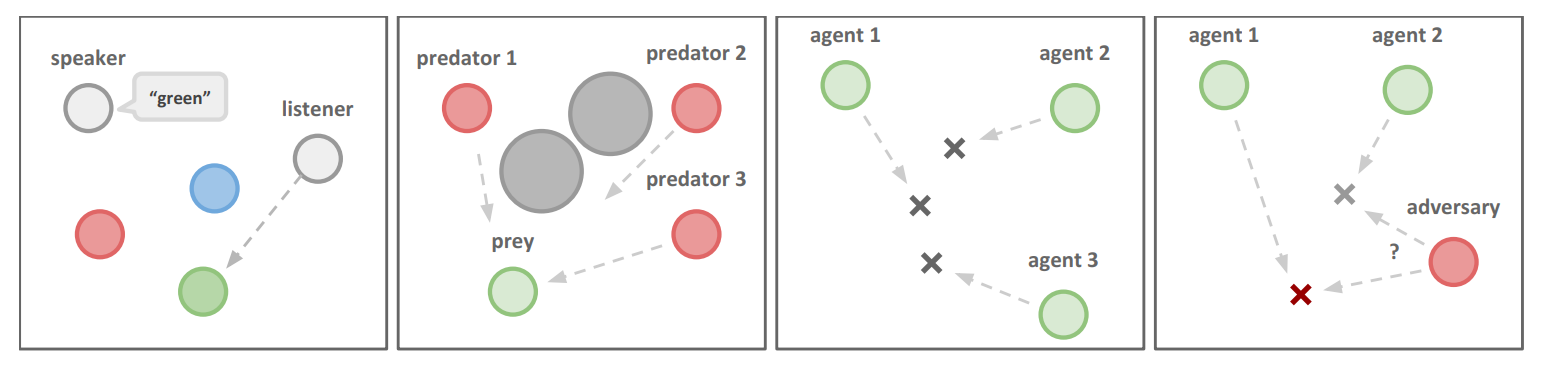
a) 合作通信 b) 捕食者-猎物 c) 合作导航 d) 物理欺骗。
**Cooperative communication **:该任务包括两个合作智能体:一个发言者和一个听者。他们被放置在一个有三个不同颜色的地标的环境中。在每个情节中,听者必须导航到特定颜色的地标,并根据其到正确地标的距离获得奖励。然而,虽然听者可以观察到地标的相对位置和颜色,但它不知道必须导航到哪个地标。相反,发言者的观察包括正确的地标颜色,它可以在每个时间步骤产生一个通信输出,这个输出被听者观察到。因此,发言者必须学会根据听者的动作输出地标颜色。
**Cooperative navigation :**代理需要通过物理行动来合作,以到达一组L个地标。智能体观察其他智能体和地标的相对位置,并根据任何代理与每个地标的接近程度共同获得奖励。换句话说,智能体需要“覆盖”所有地标。此外,代理占据了相当大的物理空间,并在相互碰撞时受到惩罚。智能体学会推断出它们必须覆盖的地标,并在避开其他智能体的同时移动到那里
**Keep-away:**其中包括L个地标(包括一个目标地标)、N个合作智能体(知道目标地标并根据与目标的距离获得奖励)和M个对抗智能体(阻止合作智能体到达目标)。对抗智能体通过将合作智能体从地标推开并暂时占据地标来实现这一目标。虽然对抗智能体也根据与目标地标的距离获得奖励,但他们不知道正确的目标;他们必须从合作智能体的行动中推断出正确的目标。
**Physical deception:**在这个场景中,N个智能体需要合作以从总共N个地标中到达一个目标地标。他们的奖励是基于任何代理到目标的最小距离(因此只有一个代理需要到达目标地标)。然而,一个孤立的对手(M=1)也希望到达目标地标;问题在于对手不知道哪个地标是正确的。因此,合作代理(根据对手到目标的距离受到惩罚)学会分散并覆盖所有地标,以便欺骗对手。
**Predator-prey:**这个环境中,N个较慢的合作智能体必须在一个随机生成的环境中追逐速度较快的对手,环境中有L个大地标阻碍道路。每当合作代理与对手发生碰撞时,智能体会得到奖励,而对手会受到惩罚。代理观察到其他智能体的相对位置和速度以及地标的位置。
**Covert communication:**这是一个对抗性通信环境,说话智能体(“爱丽丝”)必须向监听智能体(“鲍勃”)发送信息,而监听代理必须在另一端重构信息。然而,一个对抗智能体(“夏娃”)也在观察信道,并希望重构信息–爱丽丝和鲍勃会根据夏娃的重构结果受到惩罚,因此爱丽丝必须使用随机生成的密钥对信息进行编码,而这个密钥只有爱丽丝和鲍勃知道。这与《密码学》中考虑的加密环境类似。
6 结果
cooperative communication:
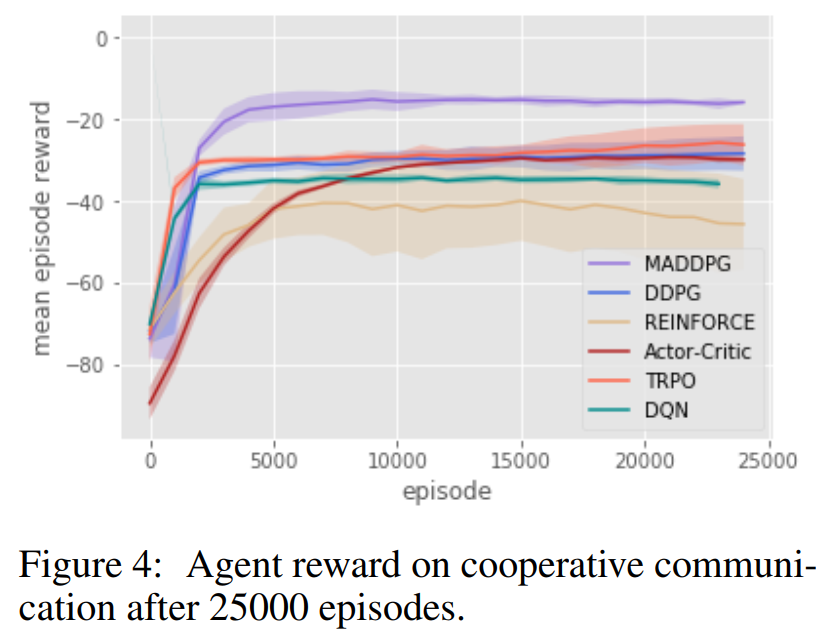
其他结果见原文
7 其他
7.1 Effect of Learning Polices of Other Agents
合作通信环境中评估学习其他智能体策略的有效性,遵循与之前实验相同的超参数设置,并在等式7中设置λ=0.001。结果如图7所示。我们观察到,尽管没有完美拟合其他智能体的策略(特别是,发言者学到的近似听者策略与真实策略的KL散度相当大),但使用近似策略进行学习能够达到与使用真实策略相同的成功率,且收敛速度没有明显减慢。
7.2 Effect of Training with Policy Ensembles
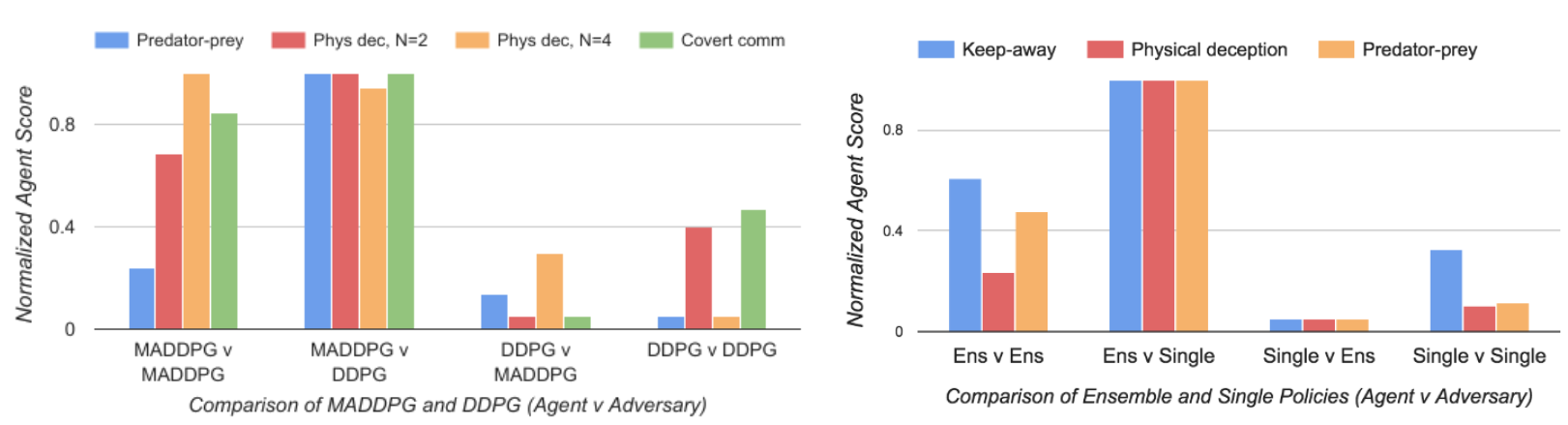
在竞争环境中关注策略集合的有效性,包括keep-away、合作导航和捕食者-猎物。我们为keep-away和合作导航环境选择K=3个子策略,为捕食者-猎物选择K=2个子策略。为了提高收敛速度,我们要求合作智能体理在每个情节中具有相同的策略,对手也是如此。为了评估这种方法,我们测量了集合策略和单一策略在代理和对手角色中的表现。结果显示在图3的右侧。我们观察到,具有策略集合的智能体比具有单一策略的代理更强大。特别是,当将集合代理与单一策略对手进行对抗(从左数第二个柱状图簇)时,与角色颠倒时(从左数第三个柱状图簇)相比,集合代理的表现优于对手的表现。















 2784
2784











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









