







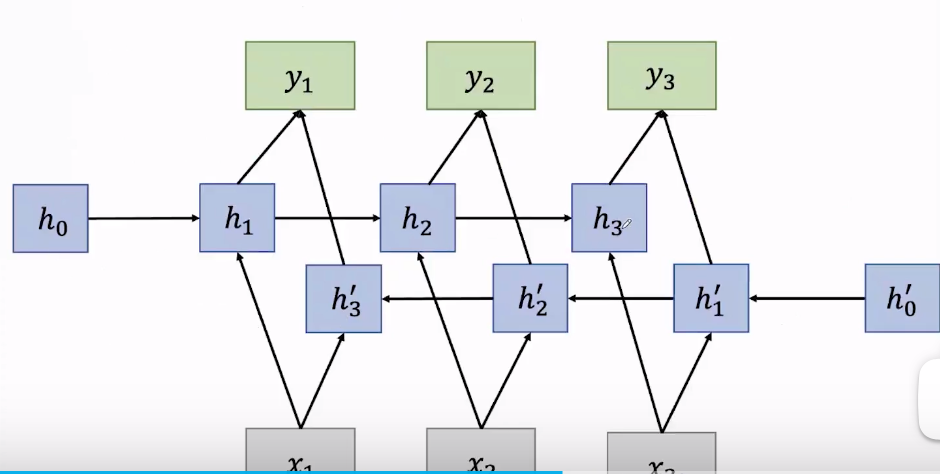
RNN
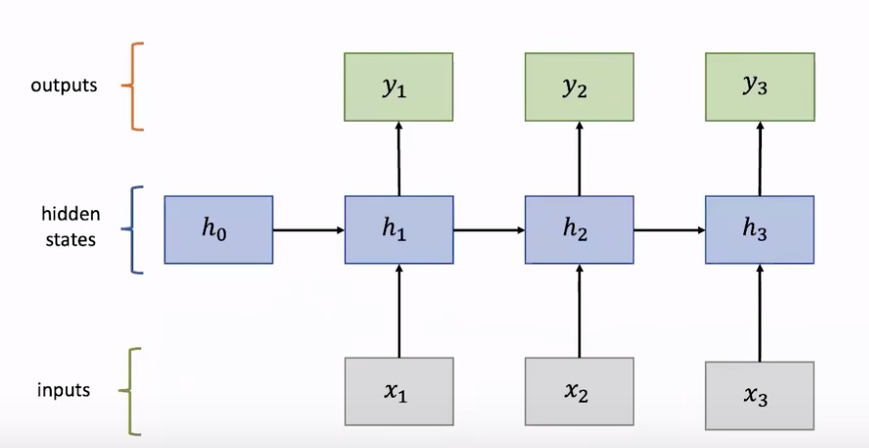
其中一个神经单元的隐藏状态
h
i
h_i
hi由上一层隐藏状态
h
i
−
1
h_{i-1}
hi−1和输入
x
i
x_i
xi决定,
W
i
W_i
Wi是权重矩阵,
b
b
b是偏置矩阵,在RNN中所有层的参数是共享的,即每一层的权重矩阵和偏置矩阵都是相同的。
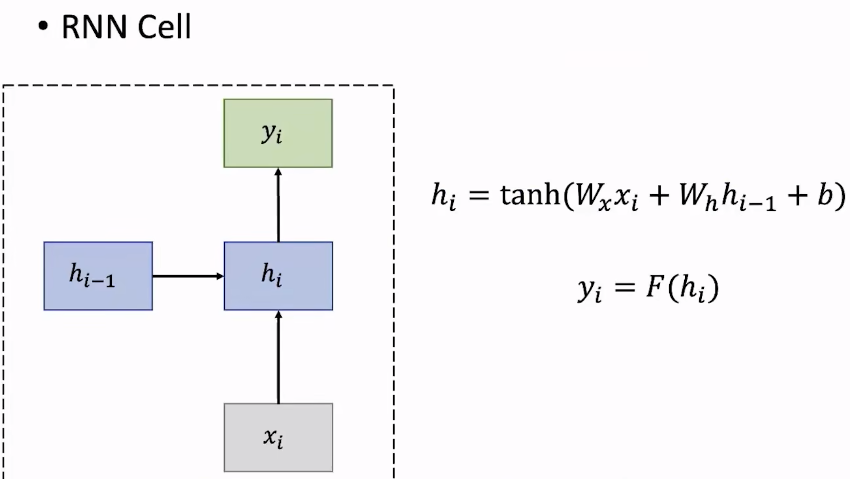
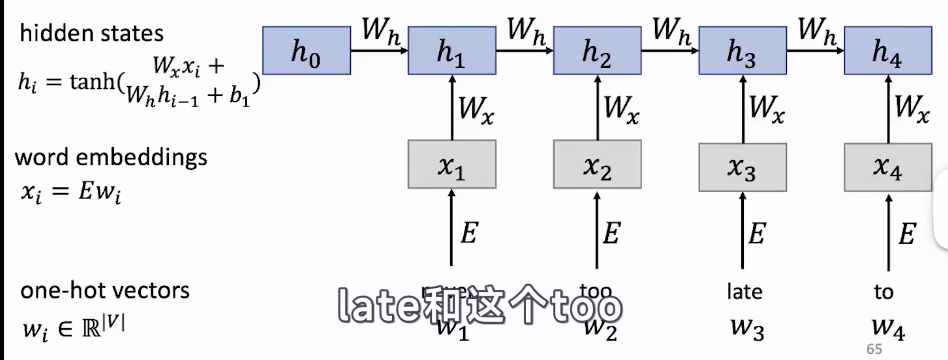
举个例子,“never too late to” ,用RNN预测“to”后面的词,首先用one-hot向量表示第一个词,再通过embedding得到更丰富含有更多信息的词向量(word2vec),再通过上一个隐藏状态计算出当前层的隐藏状态,依此类推。其中
h
0
h_0
h0是随机初始化的。当计算得到
h
4
h_4
h4之后,在输出层进行一个线性层,一般通过softmax计算出预测每个词的概率分布。
优点:
- 能够处理任意长度的输入。
- 模型大小不会随着输入的变长而变大。
- 在每个时间步的权重是共享的。
- 理论上,计算第 i i i步能包含前面的很多信息。
缺点:
- 计算速度慢。
- 实际上,随着时间不往后推移,后面的时间步很难获取到离他很远的时间步的信息。
梯度消失或爆炸问题
因为反向转播时根据链式法则,要求下游梯度,需要用上游梯度*本地梯度(一层一层嵌套)。当梯度>1时,随着层数的增加梯度会呈指数增长,梯度会爆炸;当梯度<1时,随着层数的增加梯度会呈指数衰减,梯度会消失。

RNN的变体解决梯度问题
在计算的时候
- GRU:将门控机制引入到RNN。
- 更新门:权重值会改变。
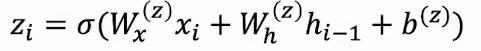
- 重置门:权重值会改变。
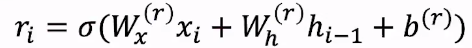
重置门通过影响上一层隐藏状态来得到一个新的激活: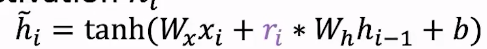
更新门通过衡量上一个隐藏状态和新的激活之间的影响得到最终的 h i h_i hi
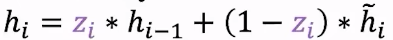
- 更新门:权重值会改变。
- LSTM: 多了一个单元状态cell state
C
t
C_t
Ct
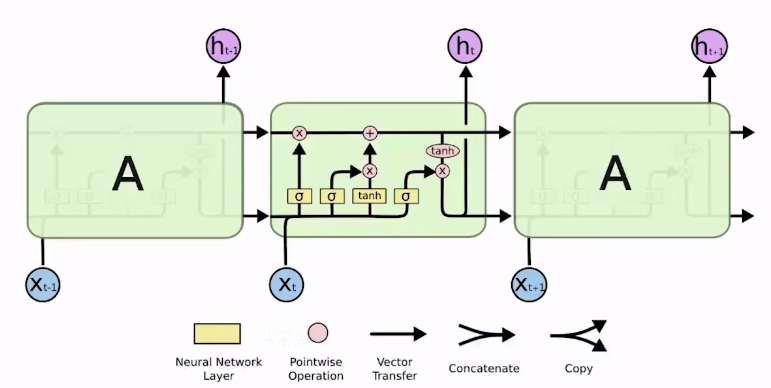
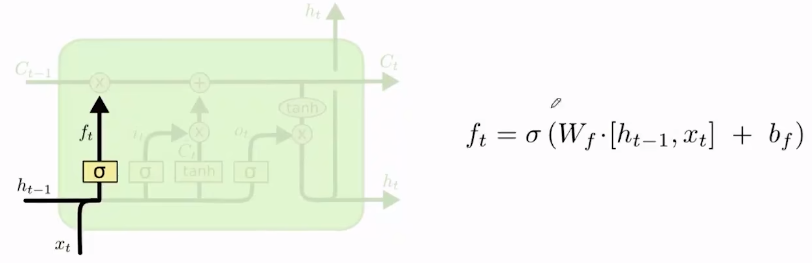
- 第一个门是遗忘门,决定上一状态哪些信息要在当前状态丢弃。
W
f
W_f
Wf是遗忘门的专属矩阵,
b
f
b_f
bf也是专属的bias。
[
h
i
−
1
,
x
t
]
[h_{i-1},x_t]
[hi−1,xt]代表将输入和上一隐藏状态进行连接concatenate。
σ
\sigma
σ代表一个激活函数,最终计算结果介于0-1之间,若
f
t
=
0
f_t=0
ft=0,将丢弃过去的信息。
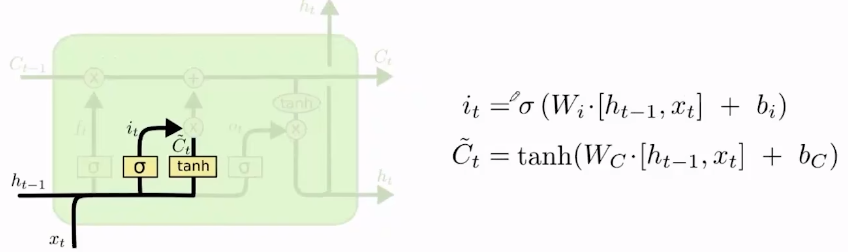
- 输入门决定待选信息
C
~
t
\tilde{C}_t
C~t中有哪些信息需要保留到
C
t
C_t
Ct中。同样计算输入门
i
t
i_t
it和待选信息
C
~
t
\tilde{C}_t
C~t时,也分别有他们专属的权重和偏置。
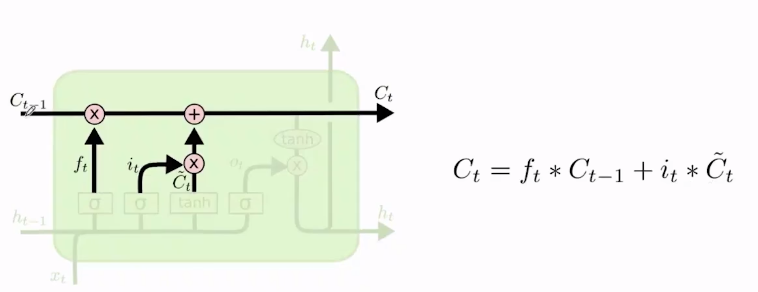
- 更新旧的cell state
C
t
−
1
C_{t-1}
Ct−1。
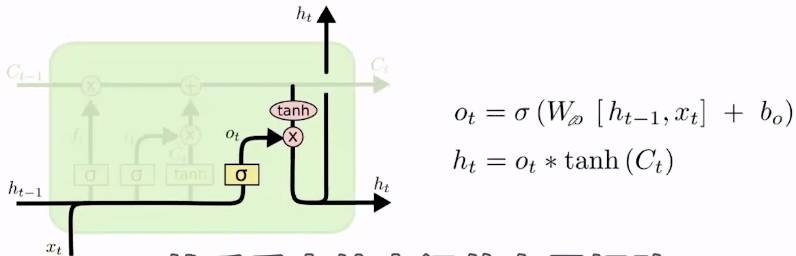
- 最后一步是输出门。输出门决定要输出哪些信息,他也有自己专属的权重和偏置。最终也是经过一个激活函数
t
a
n
h
(
)
tanh()
tanh(),得到当前的隐藏状态。
- 第一个门是遗忘门,决定上一状态哪些信息要在当前状态丢弃。
W
f
W_f
Wf是遗忘门的专属矩阵,
b
f
b_f
bf也是专属的bias。
[
h
i
−
1
,
x
t
]
[h_{i-1},x_t]
[hi−1,xt]代表将输入和上一隐藏状态进行连接concatenate。
σ
\sigma
σ代表一个激活函数,最终计算结果介于0-1之间,若
f
t
=
0
f_t=0
ft=0,将丢弃过去的信息。
- 双向RNN(双向LSTM):对当前信息的预测可能不仅依赖于以往信息,也可能以来以后的信息。
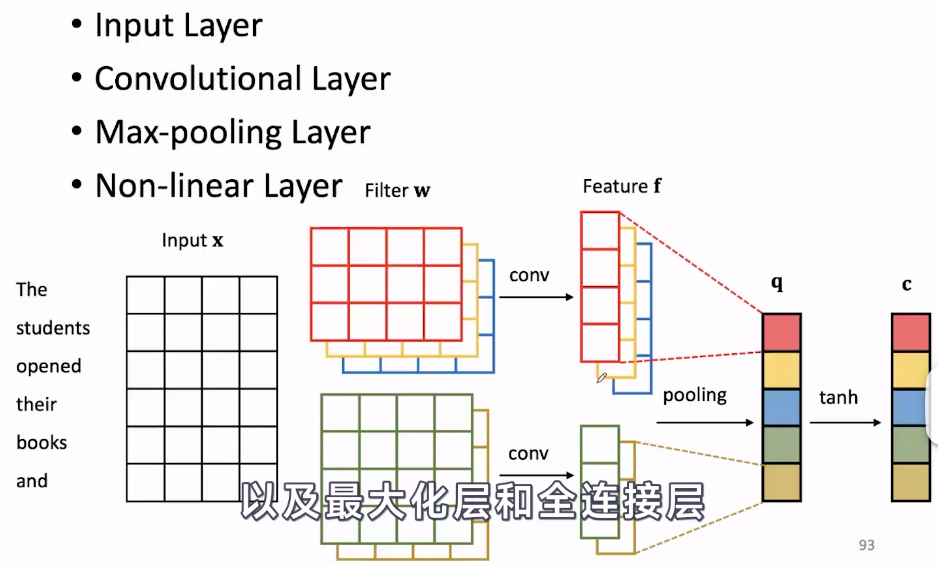
CNN
首先也是先得到输入
x
x
x的词向量矩阵,然后用滑动的卷积核Filter与词向量进行卷积(每个元素相乘最终全部加起来)就得到特征
f
f
f。得到特征后,进行池化。池化对特征进一步的提取,一般选取局部信息(与选取的n-gram有关)的最大值或平均值作为特征,最后将特征转为针对特定任务需要的格式。
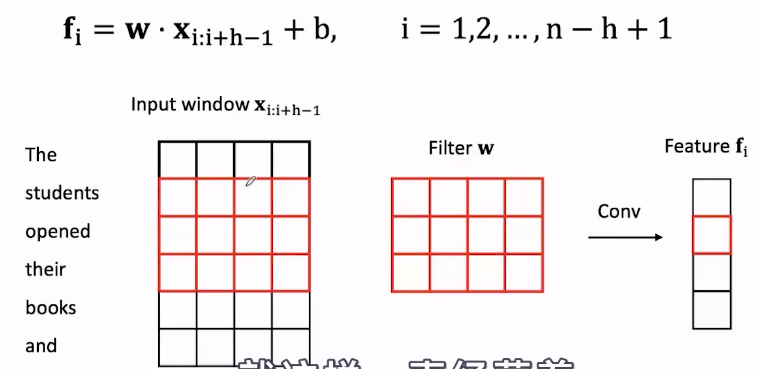
卷积层中,滑动卷积核的大小代表每次能计算的原始数据的大小,计算完一次往下滑动一个维度。
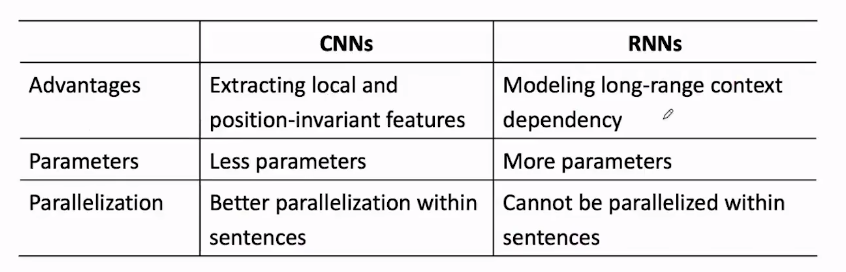
RNN与CNN对比
1.RNN更适合变长数据,CNN能提取局部特征。
2.RNN参数更多
3.CNN能更好的并行化计算,因为他卷积核之间并不是相互依赖的。















 281
281











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









