







Attention(在RNN中的应用)
注意力机制是为了解决encoder和decoder之间存在的信息瓶颈问题而提出的。因为decoder需要获取到encoder阶段的最后一个隐藏状态向量,然后用这个向量去一层一层迭代decoder,而最后一层隐藏向量或许没有能力包含输入的全部信息,因此存在信息瓶颈。
Attention计算步骤
- encoder的隐藏状态 h 1 , h 2 … , h N ∈ R h h_1, h_2 \ldots, h_N \in \mathbb{R}^h h1,h2…,hN∈Rh
- decoder在时间步 t t t的隐藏状态 s t ∈ R h s_t \in \mathbb{R}^h st∈Rh
- 计算当前时间步的注意力分数 e t = [ s t T h 1 , … , s t T h N ] ∈ R N e^t=\left[s_t^T h_1, \ldots, s_t^T h_N\right] \in \mathbb{R}^N et=[stTh1,…,stThN]∈RN
- 用softmax计算注意力分布。
与RNN的主要区别在于,RNN直接将decoder的结果作为预测词向量,而加入注意力机制后,需要用decoder的 s t s_t st结合encoder的隐向量点积计算注意力分数(比较常见的一种计算方式),使得模型能关注到最大可能该关注的encoder的隐向量 h i h_i hi,然后softmax得到注意力分布 α 1 \alpha^1 α1,最终用注意力分布与encoder的隐向量加权求和得到一个输出向量,再将这个输出向量 o 1 o_1 o1与decoder的隐向量 s 1 s_1 s1进行拼接得到最终预测词的向量。
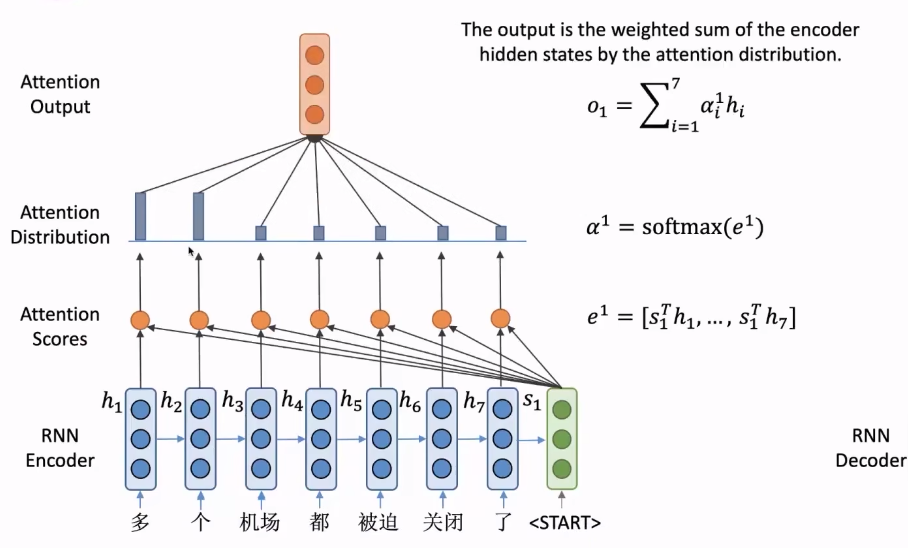
其中每个时间步decoder的隐向量都会作为输入传入decoder的下一个隐向量,直到最后一个时间步结束。
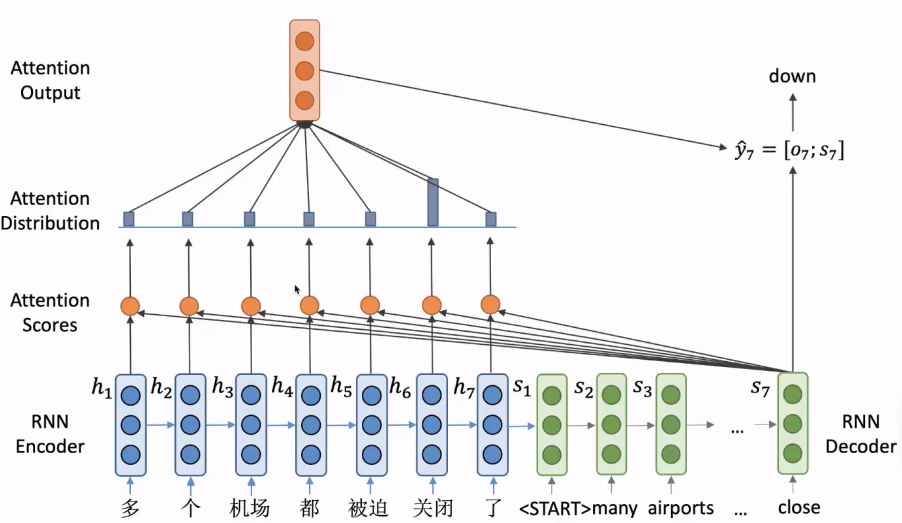
数学表示
query向量对应上述的decoder的隐向量,value向量对应encoder的隐向量,其中给定一个query向量和一系列value向量,attention的本质就是根据这个query向量对value向量加权平均。

计算注意力分数
- 点积(dot-produce)的方式:当encoder和decoder的隐向量维度相同时。
e i = s T h i ∈ R e_i=s^T h_i \in \mathbb{R} ei=sThi∈R - multiplicative attention:当encoder和decoder隐向量维度不一样时,需要在中间乘一个权重矩阵使得它们能够相乘,最后得到一个标量。
e i = s T W h i ∈ R , W ∈ R d 2 × d 1 e_i=s^T W h_i \in \mathbb{R}, \quad W \in \mathbb{R}^{d_2 \times d_1} ei=sTWhi∈R,W∈Rd2×d1 - additive attention:使用一个前馈神经网络将encoder和decoder的隐向量变成一个标量。
W
1
W_1
W1和
W
2
W_2
W2是两个权重矩阵,
v
T
∈
R
d
3
v^T \in \mathbb{R}^{d_3}
vT∈Rd3是一个权重向量。其中
W
1
∈
R
d
3
×
d
1
,
W
2
∈
R
d
3
×
d
2
W_1 \in \mathbb{R}^{d_3 \times d_1}, W_2 \in \mathbb{R}^{d_3 \times d_2}
W1∈Rd3×d1,W2∈Rd3×d2,
t
a
n
h
tanh
tanh是一个激活函数。
e i = v T tanh ( W 1 h i + W 2 s ) ∈ R e_i=v^T \tanh \left(W_1 h_i+W_2 s\right) \in \mathbb{R} ei=vTtanh(W1hi+W2s)∈R
Attention解决的问题
- RNN中信息瓶颈问题
- RNN中梯度消失问题:在encoder和decoder之间提供一种直接连接的方式,防止梯度在RNN中传播过长而消失。
- 给神经网络提供了一定可解释性。
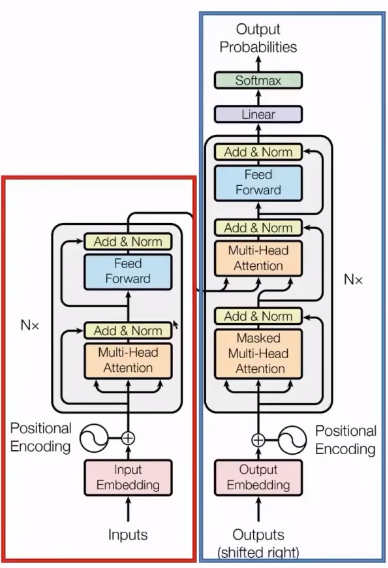
Transformer
总体结构:encoder+decoder
输入层:byte pair encoding (BPE) + 位置编码
模型:多个encoder和decoder的堆叠,每个encoder或decoder结构相同,只是参数不同。
输出层:经过线性变换和softmax输出词的概率分布。
损失函数:交叉熵损失。
输入层
Byte Pair Encoding(BPE)
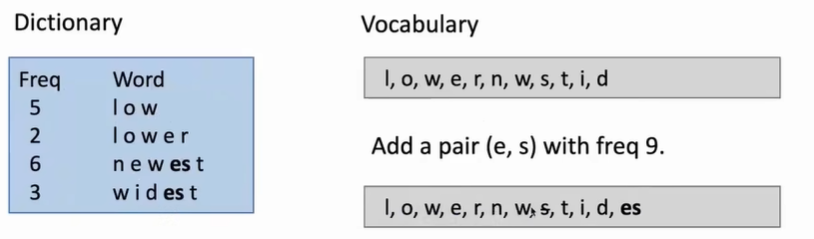
- 词表由语料库中所有出现的字母开始。如下图语料库中low频率为5;lower频率为2;newest频率为6;widest频率为3。初始词表为组成这些词的字母集合{l,o,w,e,r,n,s,t,i,d}.
- 找到出现频率最高的n-gram,并将他们替换原词表中的字母。n=2时,“es”出现频率最高为9,因此把“es”加入词表,而由于“s”不会再单独出现,于是在词表中删除,以此类推。
- 直到词表达到预期大小。最终词表中的每个结果对应一个token。
BPE解决了OOV(out of vocabulary)问题,因为原本按照空格切分的方法很难穷举完语料库中所有单词,而BPE使用subword unit能表示更多的词。
positional encoding
Transformer与RNN不同,RNN是通过从左到右的方式进行编码从而保留了句子中的位置信息,如果没有位置编码,Transformer将不能捕获词之间的位置信息。因为Transformer block(每一个encoder或decoder叫做encoder/decoder block)对不同位置的相同词不敏感。
不同位置的词表示不同:
P
E
(
pos
,
2
i
)
=
sin
(
pos
/
1000
0
2
i
/
d
)
P
E
(
pos
2
i
+
1
)
=
cos
(
pos
/
1000
0
2
i
/
d
)
\begin{aligned} & P E_{(\text {pos }, 2 i)}=\sin \left(\text { pos } / 10000^{2 i / d}\right) \\ & P E_{(\text {pos } 2 i+1)}=\cos \left(\text { pos } / 10000^{2 i / d}\right) \end{aligned}
PE(pos ,2i)=sin( pos /100002i/d)PE(pos 2i+1)=cos( pos /100002i/d)
其中$pos
当前
t
o
k
e
n
在句子中的位置,
当前token在句子中的位置,
当前token在句子中的位置,i
是
e
m
b
e
d
d
i
n
g
的
i
n
d
e
x
,
是embedding的index,
是embedding的index,d$是BPE结果(词表构建完之后,输入样本能直接从词表得到一个向量)的维度。
最终输入层的结果为BPE+Position Encoding
Transformer block
encoder由多头注意力层和前馈网络(本质上是一个带激活函数的两层MLP(多层感知机,即多层神经网络)全连接)组成。
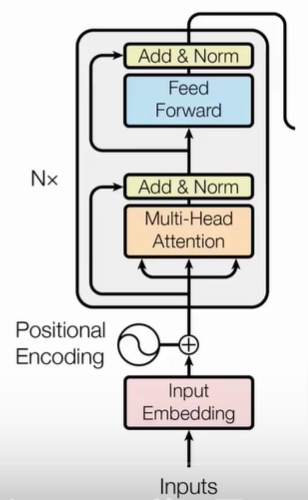
其中运用到了残差链接(将输入和输出直接相加缓解梯度消失。图中直接指向Add&Norm的线。)和正则化(将输入向量变为均值为0,方差为1的一个分布。图中的Add&Norm)两个技巧,用于缓解梯度消失或爆炸问题。
Attention(在Transfomer中的应用)
输入:
- 给定一个query向量和key-value对向量的集合
- query和key向量维度都是 d k d_k dk
- value向量维度为
d
v
d_v
dv
输出: - values向量的权重之和
- 通过query和key的点积计算每一个value的权重。
A ( q , K , V ) = ∑ e q ⋅ k i ∑ j e q ⋅ k j v i A(q, K, V)=\sum \frac{e^{q \cdot k_i}}{\sum_j e^{q \cdot k_j}} v_i A(q,K,V)=∑∑jeq⋅kjeq⋅kivi - 通过softmax计算注意力分布。这里用矩阵
Q
Q
Q表示多个query。
A ( Q , K , V ) = softmax ( Q K T ) V A(Q, K, V)=\operatorname{softmax}\left(Q K^T\right) V A(Q,K,V)=softmax(QKT)V
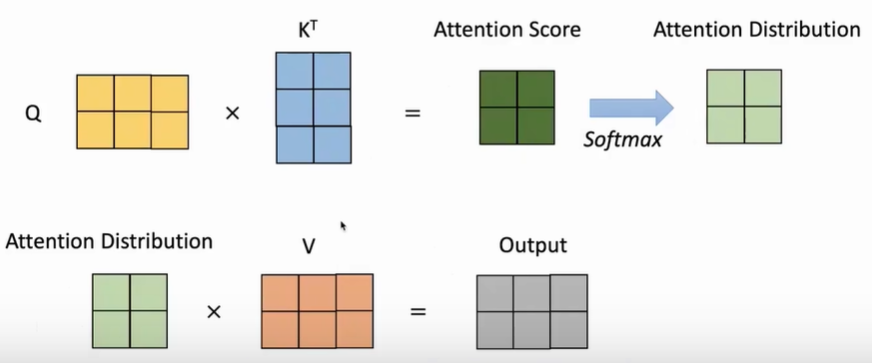
上述做法随着 d k d_k dk的增大, q T ⋅ k q^T \cdot k qT⋅k的方差将会增加,也就是说得到的分布将会更加尖锐,有某个地方可能为1,其余地方趋近于0。这会导致梯度越来越小,为了解决这个问题需要加入scale(缩放)过程。 A ( Q , K , V ) = softmax ( Q K T d k ) V A(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^T}{\sqrt{d_k}}\right) V A(Q,K,V)=softmax(dkQKT)V

self-attention
让词向量自己选择需要关注哪些token。Q、K、V都是通过词向量乘上一个变换矩阵得的。对于第一层block来说,词向量是BPE和位置编码之后的结果对于非第一层block来说,词向量是上一层block的输出。
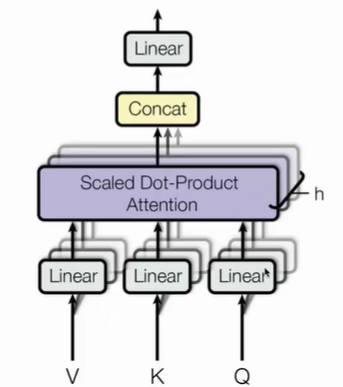
Multi-head Attention
由相同的结构自注意力一致,只是参数不同。每个注意力头都有自己的
W
q
、
W
k
、
W
v
W_q、W_k、W_v
Wq、Wk、Wv
对于
h
h
h个头,有如下表示:
head
i
=
A
(
Q
W
i
Q
,
K
W
i
K
,
V
W
i
K
)
MultiHead
(
Q
,
K
,
V
)
=
Concat
(
head
1
,
…
,
head
h
)
W
O
\begin{aligned} & \text { head }_i=\mathrm{A}\left(Q W_i^Q, K W_i^K, V W_i^K\right) \\ & \text { MultiHead }(Q, K, V)=\operatorname{Concat}\left(\text { head }_1, \ldots, \text { head }_h\right) W^O \end{aligned}
head i=A(QWiQ,KWiK,VWiK) MultiHead (Q,K,V)=Concat( head 1,…, head h)WO
其中
W
O
W^O
WO表示线性层的权重矩阵。
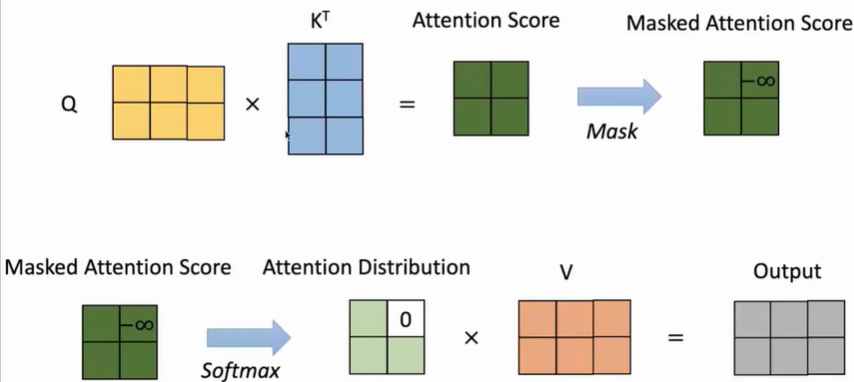
decoer与上述encoder过程基本一致(decoder需要遵循从左到右的生成的方式,不要参考后面的信息),不同点有两个:
- 在多头注意力上加了Mask(通过限制 q × k q \times k q×k的结果中上三角部分全为负无穷,经过softmax,这些位置的概率会变为0),使得词只能看到先前的词。
- 这里的多头注意力(第二个)的输入中,
K
、
V
K、V
K、V向量来自于最后一层encoder的输出,
Q
Q
Q向量才是来自于decoder(类似于RNN中的应用)。

Transformer的优缺点
优点
- 是一个强有力的模型,并已被证实对许多NLP任务是有效的。
- 适合并行计算,能更好的利用GPU资源。
- 证明了attention机制的有效性
- 为一些NLP的SOTA带来灵感,例如bert、gpt
缺点 - 结构难以优化,对参数比较敏感。对超参数、优化器的选择可能对模型性能造成很大影响。
- 每一层的复杂度为 O ( n 2 ) O(n^2) O(n2), n n n代表处理文本的长度,通常限制为512。
预训练语言模型(PLM)
语言模型
任务:给定部分词预测下一个词。
P
(
w
n
∣
w
1
,
w
2
,
⋯
,
w
n
−
1
)
P\left(w_n \mid w_1, w_2, \cdots, w_{n-1}\right)
P(wn∣w1,w2,⋯,wn−1)(能迁移到别的NLP任务),常见的有Word2vec、GPT、Bert…
语言模型包含大量语言理解的知识,例如语言知识和事实知识;并且语言模型只需要纯文本进行训练,不需要人工标注。
预训练语言模型
预训练语言模型分为两种范式:
- 基于特征的范式:直接将PLMs的输出作为下游任务的输入,例如特征提取。最具代表性的是Word2vec
- 微调的范式:语言模型也会作为下游任务的模型,并且会更新他们的参数。最具代表性的是Bert。
GPT
GPT是第一个基于Transformer的预训练语言模型。它利用了Transformer+left-to-right LM的方式,并在下游任务进行微调。
GPT用12层的Transformer的decoder在无监督预料上进行训练,然后在下游任务,例如分类任务上进行预测。
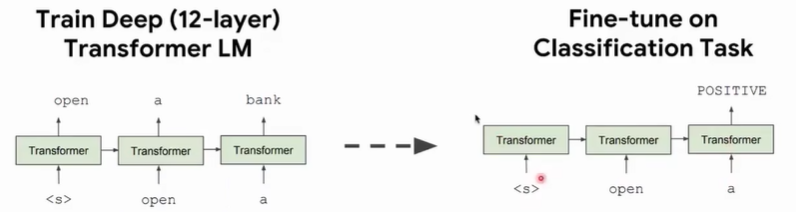
GPT-2
与GPT相比,提升了transformer的参数量,使用更大规模的预训练语料训练了40GB的文本。可以零样本学习。
GPT系列效果好的主要原因是:
- 模型从大规模的预训练语料中学习
- 使用了高效的transformer的decoder
Bert
在bert之前的LM是单向的,要么只用左边要么只用右边的内容,但是语言理解通常是双向的,既要考虑左边也要考虑右边的信息。
而语言模型设计为单向的原因是:
- 单项的模型能生成更好的概率分布。
- 双向的模型可能产生信息泄露问题。例如下图中在预测“a”时,模型会看到这个词,模型就不学习和推理,直接shortcut出需要预测的词。
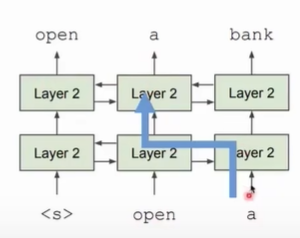
Bert为了解决信息泄露问题,提出了掩码语言模型,这也是Bert的预训练任务之一,。Bert采用随机mask15%的词,在最后一层让模型还原被mask掉的词。

而使用mask策略会引起mask的token在微调时没有见过,会导致预训练和微调时的差异,模型可能会只关注mask的token。为了解决这个问题,针对15%的mask的词,分为3种小策略: - 80%的时间,会直接用[MASK]替代需要被掩码的词。
- 10%的时间,随机用一个词来替代需要被掩码的词。
- 10%的时间,保持不变。
Bert的另一个预训练任务是下一个句子预测,能够学习句子间的关系。 利用标签来确定两个句子是否相邻。
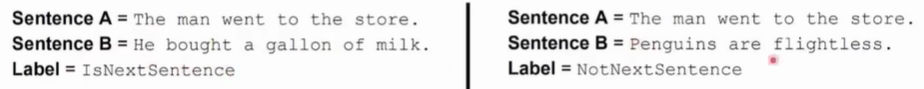
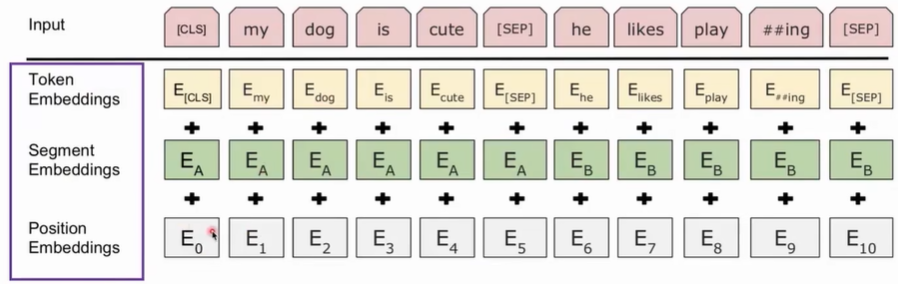
Bert的输入:起始[CLS]和结束[SEP]都是两个特殊标签,Segment Embedding在预训练时就是两个句子是否相邻的embedding。最后将三个部分的embedding加起来作为输入。
RoBERTa
由于mask引起的问题,导致模型中有效学习的只有15%。
对Bert进行改进:提升BERT的鲁棒性。
- 动态的mask
- 模型的输入格式
- 下一个句子预测是否必要
- 用更大的batch size效果更好
- 文本编码(encoding)
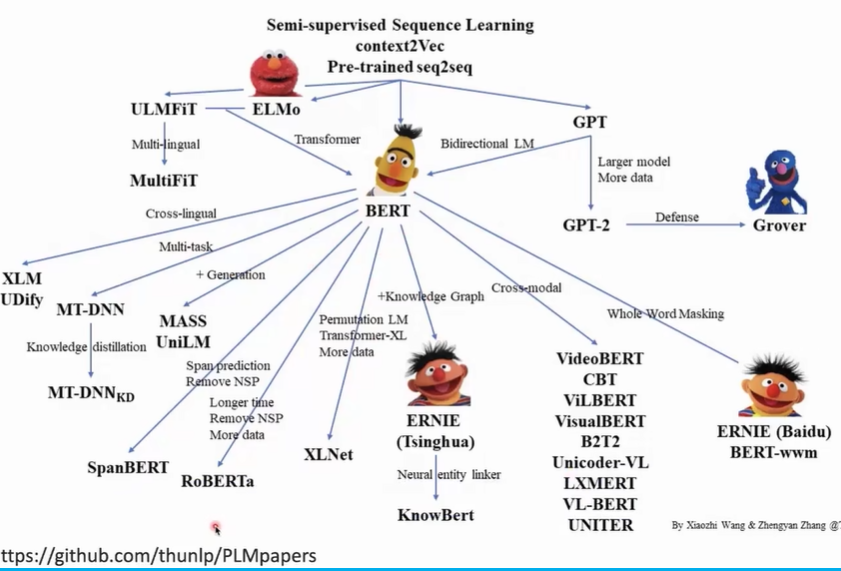
PLM Family
Trsnformer实战
Pipeline接口
# 使用pipeline,直接调用一个PLM,没有微调
from transformers import pipeline
# 直接传需要做的任务,transformer会给你找一个相应任务的plm,会自动下载。
classifier = pipeline('sentiment-analysis')
# 传入数据
cls = classifier('I love you!')
# 输出:[{'label': 'POSITIVE', 'score': 0.9998782873153687}]
print(cls)
在PLM上用自己数据进行fine-tune
在PLMs上微调的步骤通常是:
例子是用SST-2数据集做情感分析任务。
- 加载数据集和评价指标,
from datasets import load_dataset, load_metric
import numpy as np
# 加载GLUE中的sst2
data = load_dataset("glue", "sst2")
metric = load_metric("glue", "sst2")
# 随机生成ground-truth和预测的结果,用于演示metric的使用
fake_preds = np.random.randint(0, 2, size=(64,))
fake_labels = np.random.randint(0, 2, size=(64,))
# metric的使用.输出为:{'accuracy': 0.5}
metric.compute(predictions=fake_preds, references=fake_labels)
- 对数据进行tokenize
from transformers import AutoTokenizer
# 对数据进行tokenization,使用的是bert的base版本,uncased代表不区分大小小,全转为小写。
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
'''
tokenize"I love you!"的结果:
{'input_ids': [101, 1045, 2293, 2017, 999, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1]}
input_ids代表每个token对应词表中的id,
token_type_ids代表两个句子是否相邻,这里全0是因为我们只有一个句子.
若有两个句子,第一个句子的token全为0,第二个句子全为1.
attention_mask代表需要模型去attention的tokens,该例子中
全为1,如果有补全,补全的位置应该置为0.
'''
tokenizer("I love you!")
- 利用tokenizer对数据进行预处理
# 利用tokenizer对数据进行预处理
def preprocess_function(example):
# 传入truncation,将长度超过512的句子截断
return tokenizer(example['sentence'], truncation=True)
# 用sst2的训练集中前5个样例进行验证预处理函数
'''
输出结果:
{'input_ids': [[101, 5342, 2047, 3595, 8496, 2013, 1996, 18643, 3197, 102],
[101, 3397, 2053, 15966, 1010, 2069, 4450, 2098, 18201, 2015, 102],
[101, 2008, 7459, 2049, 3494, 1998, 10639, 2015, 2242, 2738, 3376, 2055, 2529, 3267, 102],
[101, 3464, 12580, 8510, 2000, 3961, 1996, 2168, 2802, 102],
[101, 2006, 1996, 5409, 7195, 1011, 1997, 1011, 1996, 1011, 11265, 17811, 18856, 17322, 2015, 1996, 16587, 2071, 2852, 24225, 2039, 102]],
'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}
'''
preprocess_function(data['train'][:5])
# 用到我们自己数据集上,用批处理的方式。map函数会将preprocess_function映射到每一个数据样本,map迭代一轮是1000次。
encoded_data = data.map(preprocess_function, batched=True)
- 加载模型
# 导入自己需要用到的模型
from transformers import AutoModelForSequenceClassification
# 载入模型,num_labels代表分类标签的种类,根据数据集来给定。
model = AutoModelForSequenceClassification.from_pretrained('bert-base-uncased', num_lables=2)
- 使用Trainer类来进行微调
# 导入trainer参数这个包
from transformers import TrainingArguments
# 导入训练器
from transformers import Trainer
# 定义一个函数,告诉trainer怎么计算指标。即根据哪个指标来选取模型作为我们的最终模型。
def compute_metrics(eval_preds):
logits, labels = eval_preds # labels:[batch_size,]
# 将概率最大的类别作为预测结果
predictions = np.argmax(logits, axis=1) # predictions:[batch_size,num_labels]
return metric.compute(predictions=predictions, references=labels)
# 构建要传给trainer的参数字典
batch_size = 16
args = TrainingArguments(
'bert-base-uncased-finetuned-sst2',# 本次训练的名称
evaluation_strategy='epoch',# 每个epoch结束评价一次
save_strategy='epoch',# 每个epoch结束保存一个checkpoint
learning_rate=2e-5,# 学习率
per_device_train_batch_size=batch_size,# 训练时,每个gpu上的batch_size,一次性训练多少个样例
per_gpu_eval_batch_size=batch_size,
num_train_epochs=5,# 训练的epoch数量
weight_decay=0.01,
load_best_model_at_end=True,# 训练结束后加载过程中效果最好的checkpoint
metric_for_best_model='accuracy'# 以准确率作为指标
)
# 初始化trainer
trainer = Trainer(
model,
args,
train_dataset=encoded_data['train'],
eval_dataset=encoded_data['validation'],
tokenizer=tokenizer,
compute_metrics=compute_metrics
)
# 开始训练
trainer.train()














 4485
4485











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









