






 文章介绍了如何在GoogleColab上使用mmdetection库进行目标检测。首先,通过安装和导入必要的库,然后选择和下载FasterR-CNN模型的配置和权重文件。接着,利用init_detector初始化模型并在单张图片上进行检测。最后,展示了如何对视频进行目标检测,将每一帧处理后生成新的视频文件。
文章介绍了如何在GoogleColab上使用mmdetection库进行目标检测。首先,通过安装和导入必要的库,然后选择和下载FasterR-CNN模型的配置和权重文件。接着,利用init_detector初始化模型并在单张图片上进行检测。最后,展示了如何对视频进行目标检测,将每一帧处理后生成新的视频文件。
传统目标检测分为 one-step 和two-step,也就是对提出Anchor和分类部分结合问题。
使用API不需要担心这一问题。
一.准备工作
tip:本文基于google colab免费算力平台进行实现
1.1 安装三方库(clone git库)
!pip install -U openmim
!mim install mmengine
!mim install "mmcv>=2.0.0"
!mim install mmdet
!git clone https://github.com/open-mmlab/mmdetection.git
%cd mmdetection
!pip install -e .在当前目录下就会看到克隆的库
1.2 导入必要包
from mmdet.apis import init_detector, inference_detector
from mmdet.utils import register_all_modules
from mmdet.registry import VISUALIZERS
import mmcv
import torch1.3 定义运行设备是CPU or GPU,建议放在GPU上进行加速运算
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')二,选择模型(网络结构和权重文件)
2.1 先使用命令‘mim search mmdet --model"model_name" ’搜索你需要的模型
本文采用Faster R-Cnn
!mim search mmdet --model 'faster r-cnn' 可以按照自己的需求进行选择,具体模型的AP 可见官网

2.2 下载具体的模型版本和权重文件。
mim download mmdet --config 模型版本 --dest 存放路径
!mim download mmdet --config faster-rcnn_r50-caffe-c4_1x_coco --dest ./checkpoints
config_file = './checkpoints/faster-rcnn_r50-caffe-c4_1x_coco.py'
checkpoint_file = './checkpoints/faster_rcnn_r50_caffe_c4_1x_coco_20220316_150152-3f885b85.pth'2.3 将下载的两个文件用‘init_detector’封装起来,之后会用调用其进行目标检测
tip:register_all_modules() 本人在测试中删除了也不会报错
#Register all modules in mmdet into the registries
register_all_modules()
# build the model from a config file and a checkpoint file
#模型和参数配置文件组成一个model
model = init_detector(config_file, checkpoint_file, device=device) # or device='cpu' #'cuda:0'三.测试图片能否顺利检测
# test a single image
img = mmcv.imread( 'demo.jpg', channel_order='rgb')
result = inference_detector(model, img)
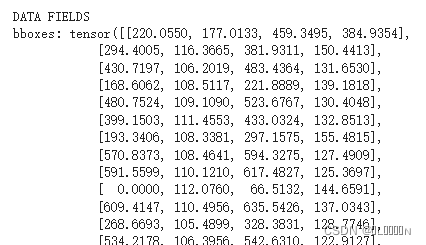
print(result)result分两部分:基本信息和检测信息
基本信息如下

检测信息(目标框、置信度、label等)

tip:如果是进行的分割,还会有mask
四.视频检测
主要思想:将视频分成图片进行检测,后重组成一个新的视频
在此代码块主要做了以下几件事:
1.加载模型
2.加载视频并获取其信息(高,宽,fps),后续用于重组视频
3.读取视频上每一帧的图片,将检测结果用add_datasample方法进行可视化。
4.将可视化后的图片加入新的视频
import cv2
import os
from mmdet.apis import inference_detector, init_detector
# 配置文件和权重文件路径
config_file = '/content/mmdetection/checkpoints/faster-rcnn_r50-caffe-c4_1x_coco.py'
checkpoint_file = '/content/mmdetection/checkpoints/faster_rcnn_r50_caffe_c4_1x_coco_20220316_150152-3f885b85.pth'
# 初始化模型
model = init_detector(config_file, checkpoint_file, device=device) #
video_path = '/content/mmdetection/demo/person_2.mp4'
video = cv2.VideoCapture(video_path)
# 获取视频信息
frame_width = int(video.get(cv2.CAP_PROP_FRAME_WIDTH))
frame_height = int(video.get(cv2.CAP_PROP_FRAME_HEIGHT))
fps = video.get(cv2.CAP_PROP_FPS)
# 创建视频编写器
output_path = 'output1.mp4'
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
video_writer = cv2.VideoWriter(output_path, fourcc, fps, (frame_width, frame_height))
# 遍历视频帧
while video.isOpened():
ret, frame = video.read()
if not ret:
break
# 目标检测
result = inference_detector(model, frame)
# 结果可视化
visualizer = VISUALIZERS.build(model.cfg.visualizer)
visualizer.dataset_meta = model.dataset_meta
visualizer.add_datasample(
'result',
frame,
data_sample=result,
draw_gt=False,
wait_time=0
)
visualizer.show()
# 将结果帧写入视频
video_writer.write(visualizer.get_image())
# 释放资源
video.release()
video_writer.release()
cv2.destroyAllWindows()Tip:visualizer是用于可视化的对象方法。在1.0的版本用show_result_pyplot(),2.0使用model.show_result()。但是这两个方法我都试过不太行。

















 856
856

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









