







L2正则化
普通的损失函数
L
=
∑
n
(
y
^
n
−
(
b
+
∑
w
i
x
i
)
)
2
L = \sum_n( \hat y_n- (b+\sum w_ix_i))^2
L=n∑(y^n−(b+∑wixi))2
在损失函数后面加上一个正则项,梯度下降的时候时候减小w
L
=
∑
n
(
y
^
n
−
(
b
+
∑
w
i
x
i
)
)
2
+
λ
∑
w
i
2
L = \sum_n( \hat y_n- (b+\sum w_ix_i))^2 + \lambda\sum w_i^2
L=n∑(y^n−(b+∑wixi))2+λ∑wi2
梯度下降更新会在原有的梯度上多减去一项,使得w的值更小
w
=
w
−
α
(
δ
L
δ
W
+
λ
∑
w
)
w = w - \alpha(\frac {\delta L} {\delta W } +\lambda \sum w)
w=w−α(δWδL+λ∑w)
更小的权重意味着,学出来的模型更加简单平滑。假设模型为最简单的线性回归模型
y
=
b
+
∑
w
i
(
x
i
+
△
x
i
)
y = b + \sum w_i(x_i+\vartriangle x_i)
y=b+∑wi(xi+△xi)
当w越小或趋向于0时,x变化时,w
△
x
→
0
\vartriangle x \to0
△x→0
w
i
→
0
w
i
△
x
i
→
0
w_i \to 0 \\w_i\vartriangle x_i \to 0
wi→0wi△xi→0
因此,模型对输入变化越不敏感,受噪声的影响越小。
不足的点在于,λ过大时,造成w过小,会造成输入x的拟合不足。
在参数λ合适的情况下,增加L2正则化项可以降低模型复杂度,提高测试准确度。
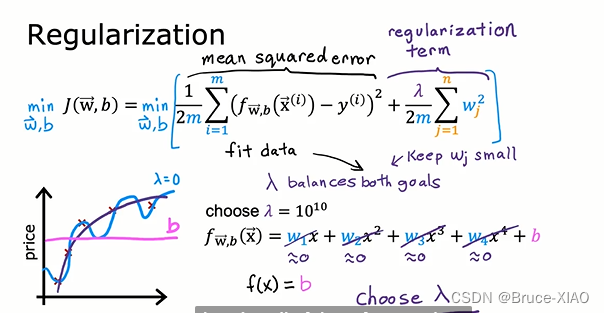
如下图,来自Andrew的课程,
当
λ
=
0
\lambda = 0
λ=0时,模型
f
(
x
)
=
w
1
x
1
+
w
2
x
2
+
w
3
x
3
+
w
4
x
4
+
b
f(x) = w_1x_1+w_2x^2+w_3x^3+w_4x^4+b
f(x)=w1x1+w2x2+w3x3+w4x4+b, 曲线如蓝色线条,模型会非常复杂, 造成过拟合
而当
λ
=
1
0
10
\lambda = 10^{10}
λ=1010时,所有的权重都将减小至0,
f
(
x
)
=
b
f(x)=b
f(x)=b,如红色线条,模型欠拟合
当选择一个合适的
λ
\lambda
λ时,得到一个合适的模型,如紫色线
参考:
李宏毅课程















 686
686











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









