







Prometheus 监控基础

监控系统基础
- 监控系统发展史
- SNMP监控时代
第一代主要是监控网络流量和网络设置为主的时代,在那个时代主要是通过SNMP协议监控交换机、路由器、网关、操作系统等,通过互联网日益增长的需求,这种简单的通过SNMP协议实现的监控手段并不能满足现有需求,因此这种监控手段逐渐被替代。 - 当今的监控系统
当今比较流行的监控系统有Prometheus、Zabbix、Nagios、Cacti、Ganglia,它们都有几个基本特点就是对操作系统的监控数据采集、存储及展示。 - 未来的监控系统
目前一些大厂或多多少的接触到,比如基于Data的DataOps,基于AI的AIOps,他们背后都要或多或少基于一个立体监控系统,完成对于系统运行状态的分析与监控,最后反馈到系统监控中心去。大多数系统现在还处于非自治状态,对于这种非自治状态的系统对于管理者来讲需要对其进行深入的监控,以及了解它的运行特性而后做出响应的决策。我们不但要做事前监控还要做事后监控。监控系统是我们运维体系中不可缺少的基础服务,而且随着人工智能、大数据的发展,基于DataOps、AIOps的未来监控甚嚣尘上。
- 监控系统组件
- 指标数据采集
- 指标数据存储
- 指标数据分析及可视化
- 告警通知
监控系统,一般而言,它无非就是对于每一个被监控的目标,或者我们要监控的系统中的组件,(比如一个主机、交换机、网关、应用、基础服务、某个业务特征等),对于这么一个基础设施层,我们要对它内部的运行的各种关键数据,通常是一种随时间变化的数据,我们一般把它叫做指标数据,然后我们采集这些指标数据,通常会得到一些点状数据,这些点状数据我们称之为样本数据,为了能够做事后分析,我们需要把它存储下来,所以对于存储这块,需要具备持续读写的性能的支撑,在存储这些样本数据后,我们需要根据样本数据做一些分析,得出当前系统运行状态,甚至后续预测出是否会出现的问题,通常这些样本数据可以通过一个UI界面服务呈现给我们查看,最后监控系统还需要有告警通知服务,通过设置一些规则我们就能提前得到系统运行状态的信息。
一、Prometheus 监控平台简介
Prometheus受启发于Google的Brogmon监控系统(相似的Kubernetes是从Google的Brog系统演变而来),从2012年开始由前Google工程师在Soundcloud以开源软件的形式进行研发,并且于2015年早期对外发布早期版本。2016年5月继Kubernetes之后成为第二个正式加入CNCF基金会的项目,同年6月正式发布1.0版本。2017年底发布了基于全新存储层的2.0版本,能更好地与容器平台、云平台配合。
Prometheus作为新一代的云原生监控系统,目前已经有超过650+位贡献者参与到Prometheus的研发工作上,并且超过120+项的第三方集成。
Prometheus的优势
Prometheus是一个开源的完整监控解决方案,其对传统监控系统的测试和告警模型进行了彻底的颠覆,形成了基于中央化的规则计算、统一分析和告警的新模型。 相比于传统监控系统Prometheus具有以下优点:
- 易于管理
Prometheus核心部分只有一个单独的二进制文件,不存在任何的第三方依赖(数据库,缓存等等)。唯一需要的就是本地磁盘,因此不会有潜在级联故障的风险。
Prometheus基于Pull模型的架构方式,可以在任何地方(本地电脑,开发环境,测试环境)搭建我们的监控系统。对于一些复杂的情况,还可以使用Prometheus服务发现(Service Discovery)的能力动态管理监控目标。
- 监控服务的内部运行状态
Prometheus鼓励用户监控服务的内部状态,基于Prometheus丰富的Client库,用户可以轻松的在应用程序中添加对Prometheus的支持,从而让用户可以获取服务和应用内部真正的运行状态。
- 强大的数据模型
所有采集的监控数据均以指标(metric)的形式保存在内置的时间序列数据库当中(TSDB)。所有的样本除了基本的指标名称以外,还包含一组用于描述该样本特征的标签。如下所示:
http_request_status{code='200',content_path='/api/path', environment='produment'} => [value1@timestamp1,value2@timestamp2...]
http_request_status{code='200',content_path='/api/path2', environment='produment'} => [value1@timestamp1,value2@timestamp2...]
每一条时间序列由指标名称(Metrics Name)以及一组标签(Labels)唯一标识。每条时间序列按照时间的先后顺序存储一系列的样本值。
表示维度的标签可能来源于你的监控对象的状态,比如code=404或者content_path=/api/path。也可能来源于的你的环境定义,比如environment=produment。基于这些Labels我们可以方便地对监控数据进行聚合,过滤,裁剪。
- 强大的查询语言PromQL
Prometheus内置了一个强大的数据查询语言PromQL。 通过PromQL可以实现对监控数据的查询、聚合。同时PromQL也被应用于数据可视化(如Grafana)以及告警当中。
- 高效
对于监控系统而言,大量的监控任务必然导致有大量的数据产生。而Prometheus可以高效地处理这些数据,对于单一Prometheus Server实例而言它可以处理:
-
数以百万的监控指标
-
每秒处理数十万的数据点
- 可扩展
Prometheus是如此简单,因此你可以在每个数据中心、每个团队运行独立的Prometheus Sevrer。
Prometheus对于联邦集群的支持,可以让多个Prometheus实例产生一个逻辑集群,当单实例Prometheus Server处理的任务量过大时,通过使用功能分区(sharding)+联邦集群(federation)可以对其进行扩展。
- 易于集成
使用Prometheus可以快速搭建监控服务,并且可以非常方便地在应用程序中进行集成。目前支持: Java、JMX、 Python、 Go、Ruby、 .Net、 Node.js等等语言的客户端SDK,基于这些SDK可以快速让应用程序纳入到Prometheus的监控当中,或者开发自己的监控数据收集程序。同时这些客户端收集的监控数据,不仅仅支持Prometheus,还能支持Graphite这些其他的监控工具。
同时Prometheus还支持与其他的监控系统进行集成:Graphite、Statsd、Collected、Scollector、muini、Nagios等。
Prometheus社区还提供了大量第三方实现的监控数据采集支持:JMX, CloudWatch, EC2, MySQL, PostgresSQL, Haskell, Bash, SNMP, Consul, Haproxy, Mesos, Bind, CouchDB, Django, Memcached, RabbitMQ, Redis, RethinkDB, Rsyslog等等。
- 可视化
Prometheus Server中自带了一个Prometheus UI,通过这个UI可以方便地直接对数据进行查询,并且支持直接以图形化的形式展示数据。同时Prometheus还提供了一个独立的基于Ruby On Rails的Dashboard解决方案Promdash。最新的Grafana可视化工具也已经提供了完整的Prometheus支持,基于Grafana可以创建更加精美的监控图标。基于Prometheus提供的API还可以实现自己的监控可视化UI。
- 开放性
通常来说当我们需要监控一个应用程序时,一般需要该应用程序提供对相应监控系统协议的支持。因此应用程序会与所选择的监控系统进行绑定。为了减少这种绑定所带来的限制。对于决策者而言要么你就直接在应用中集成该监控系统的支持,要么就在外部创建单独的服务来适配不同的监控系统。
而对于Prometheus来说,使用Prometheus的client library的输出格式不止支持Prometheus的格式化数据,也可以输出支持其它监控系统的格式化数据,比如Graphite。
因此你甚至可以在不使用Prometheus的情况下,采用Prometheus的client library来让你的应用程序支持监控数据采集。
二、初识 Prometheus
Prometheus是一个开放性的监控解决方案,用户可以非常方便的安装和使用Prometheus并且能够非常方便的对其进行扩展。为了能够更加直观的了解Prometheus Server,接下来我们将在本地部署并运行一个Prometheus Server实例,通过Node Exporter采集当前主机的系统资源使用情况。 并通过Grafana创建一个简单的可视化仪表盘。
安装Prometheus Server
Prometheus基于Golang编写,编译后的软件包,不依赖于任何的第三方依赖。用户只需要下载对应平台的二进制包,解压并且添加基本的配置即可正常启动Prometheus Server。
从二进制包安装
对于非Docker用户,可以从https://prometheus.io/download/找到最新版本的Prometheus Sevrer软件包:
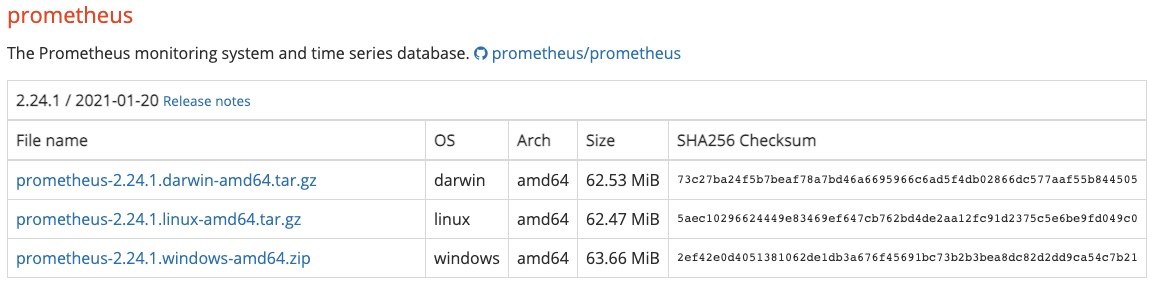
这里我们下载prometheus-2.24.1.linux-amd64.tar.gz,解压,并将Prometheus相关的命令,添加到系统环境变量路径即可:
tar -xzf prometheus-2.24.1.linux-amd64.tar.gz
cd prometheus-2.24.1.linux-amd64
解压后当前目录会包含默认的Prometheus配置文件promethes.yml:
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
Promtheus作为一个时间序列数据库,其采集的数据会以文件的形式存储在本地中,默认的存储路径为data/,因此我们需要先手动创建该目录:
mkdir -p data
用户也可以通过参数--storage.tsdb.path="/data/promethes-data/"修改本地数据存储的路径。
启动prometheus服务,其会默认加载当前路径下的prometheus.yaml文件:
./prometheus
正常的情况下,你可以看到以下输出内容:
level=info ts=2021-01-21T12:23:06.182Z caller=main.go:326 msg="No time or size retention was set so using the default time retention" duration=15d
level=info ts=2021-01-21T12:23:06.182Z caller=main.go:364 msg="Starting Prometheus" version="(version=2.24.1, branch=HEAD, revision=e4487274853c587717006eeda8804e597d120340)"
level=info ts=2021-01-21T12:23:06.182Z caller=main.go:369 build_context="(go=go1.15.6, user=root@0b5231a0de0f, date=20210120-00:09:36)"
level=info ts=2021-01-21T12:23:06.182Z caller=main.go:370 host_details="(Linux 4.4.0-62-generic #83-Ubuntu SMP Wed Jan 18 14:10:15 UTC 2017 x86_64 sc-stable-ops-tools-001 (none))"
level=info ts=2021-01-21T12:23:06.182Z caller=main.go:371 fd_limits="(soft=1024, hard=1048576)"
level=info ts=2021-01-21T12:23:06.182Z caller=main.go:372 vm_limits="(soft=unlimited, hard=unlimited)"
level=info ts=2021-01-21T12:23:06.184Z caller=web.go:530 component=web msg="Start listening for connections" address=0.0.0.0:9090
level=info ts=2021-01-21T12:23:06.185Z caller=main.go:738 msg="Starting TSDB ..."
level=info ts=2021-01-21T12:23:06.186Z caller=tls_config.go:191 component=web msg="TLS is disabled." http2=false
level=info ts=2021-01-21T12:23:06.190Z caller=head.go:645 component=tsdb msg="Replaying on-disk memory mappable chunks if any"
level=info ts=2021-01-21T12:23:06.190Z caller=head.go:659 component=tsdb msg="On-disk memory mappable chunks replay completed" duration=2.863µs
level=info ts=2021-01-21T12:23:06.190Z caller=head.go:665 component=tsdb msg="Replaying WAL, this may take a while"
level=info ts=2021-01-21T12:23:06.191Z caller=head.go:717 component=tsdb msg="WAL segment loaded" segment=0 maxSegment=0
level=info ts=2021-01-21T12:23:06.191Z caller=head.go:722 component=tsdb msg="WAL replay completed" checkpoint_replay_duration=15.9µs wal_replay_duration=220.764µs total_replay_duration=256.654µs
level=info ts=2021-01-21T12:23:06.192Z caller=main.go:758 fs_type=EXT4_SUPER_MAGIC
level=info ts=2021-01-21T12:23:06.192Z caller=main.go:761 msg="TSDB started"
level=info ts=2021-01-21T12:23:06.192Z caller=main.go:887 msg="Loading configuration file" filename=/opt/prometheus/current/prometheus.yml
level=info ts=2021-01-21T12:23:06.194Z caller=main.go:918 msg="Completed loading of configuration file" filename=/opt/prometheus/current/prometheus.yml totalDuration=1.122768ms remote_storage=2.079µs web_handler=488ns query_engine=901ns scrape=220.418µs scrape_sd=37.452µs notify=26.64µs notify_sd=18.238µs rules=5.187µs
level=info ts=2021-01-21T12:23:06.194Z caller=main.go:710 msg="Server is ready to receive web requests."
使用容器安装
对于Docker用户,直接使用Prometheus的镜像即可启动Prometheus Server:
docker run -p 9090:9090 -v /etc/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus
启动完成后,可以通过http://localhost:9090访问Prometheus的UI界面:
使用Node Exporter采集主机数据
安装Node Exporter
在Prometheus的架构设计中,Prometheus Server并不直接提供监控特定目标的服务,其主要任务负责数据的收集、存储并且对外提供数据查询支持。因此为了能够监控到服务器状态,如主机的CPU使用率,我们需要使用到Exporter。Prometheus周期性的从Exporter暴露的HTTP服务地址(通常是/metrics)拉取监控样本数据。
从上面的描述中可以看出Exporter是一个相对开放的概念,可能是一个独立运行的程序独立于监控目标之外,也可能是直接内置在监控目标中。只要能够向Prometheus提供标准格式的监控样本数据即可。
这里为了能够采集到主机的运行指标如CPU, 内存,磁盘等信息。我们可以使用Node Exporter。
Node Exporter同样采用Golang编写,并且不存在任何的第三方依赖,只需要下载,解压即可运行。可以从https://prometheus.io/download/获取最新的node exporter版本的二进制包。
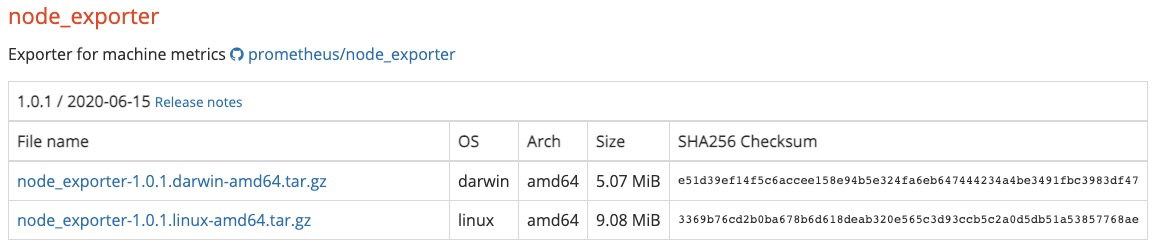
tar xf node_exporter-1.0.1.linux-amd64.tar.gz
cd node_exporter-1.0.1.linux-amd64 && ls
LICENSE node_exporter NOTICE
运行node exporter:
mv node_exporter /usr/local/bin/
node_exporter
启动成功后,可以看到以下输出:
level=info ts=2021-01-21T12:55:05.965Z caller=node_exporter.go:191 msg="Listening on" address=:9100
初始Node Exporter监控指标
本地机器访问127.0.0.1:9100/metrics,我们会看到很多机器状态指标:
curl 127.0.0.1:9100/metrics
# HELP node_cpu Seconds the cpus spent in each mode.
# TYPE node_cpu counter
node_cpu{cpu="cpu0",mode="idle"} 362812.7890625
# HELP node_load1 1m load average.
# TYPE node_load1 gauge
node_load1 3.0703125
其中HELP用于解释当前指标的含义,TYPE则说明当前指标的数据类型。在上面的例子中node_cpu的注释表明当前指标是cpu0上idle进程占用CPU的总时间,CPU占用时间是一个只增不减的度量指标,从类型中也可以看出node_cpu的数据类型是计数器(counter),与该指标的实际含义一致。又例如node_load1该指标反映了当前主机在最近一分钟以内的负载情况,系统的负载情况会随系统资源的使用而变化,因此node_load1反映的是当前状态,数据可能增加也可能减少,从注释中可以看出当前指标类型为仪表盘(gauge),与指标反映的实际含义一致。
除了这些以外,在当前页面中根据物理主机系统的不同,你还可能看到如下监控指标:
- node_boot_time:系统启动时间
- node_cpu:系统CPU使用量
- node_disk_io_*:磁盘IO
- node_filesystem_*:文件系统用量
- node_load1:系统负载
- node_memory_*:内存使用
- node_network*:网络带宽
- node_time:当前系统时间
- go_*:node exporter中go相关指标
- process_*:node exporter自身进程相关运行指标
从Node Exporter收集监控数据
为了能够让Prometheus Server能够从当前node exporter获取到监控数据,这里需要修改Prometheus配置文件。编辑prometheus.yml并在scrape_configs节点下添加以下内容:
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
# 采集node exporter监控数据
- job_name: 'node'
static_configs:
- targets: ['172.17.40.65:9100', '172.17.40.66:9100', '172.17.40.67:9100']
重新启动Prometheus Server
访问http://localhost:9090,进入到Prometheus Server。如果输入“up”并且点击执行按钮以后,可以看到如下结果:

如果Prometheus能够正常从node exporter获取数据,则会看到以下结果:
up{instance="localhost:9090",job="prometheus"} 1
up{instance="172.17.40.67:9100",job="node"} 1
其中“1”表示正常,反之“0”则为异常。
使用PromQL查询监控数据
Prometheus UI是Prometheus内置的一个可视化管理界面,通过Prometheus UI用户能够轻松的了解Prometheus当前的配置,监控任务运行状态等。 通过Graph面板,用户还能直接使用PromQL实时查询监控数据。
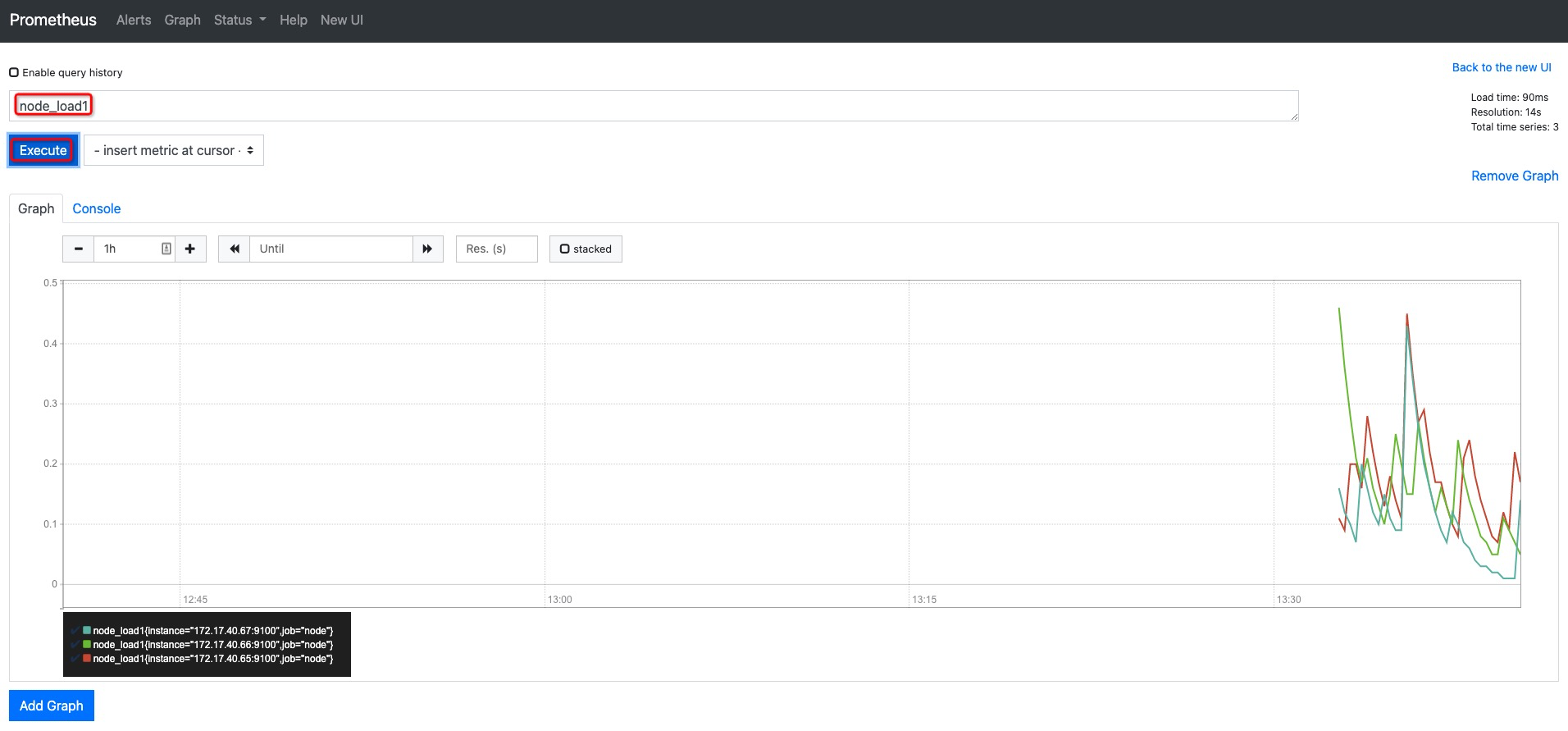
切换到Graph面板,用户可以使用PromQL表达式查询特定监控指标的监控数据。如下所示,查询主机负载变化情况,可以使用关键字node_load1可以查询出Prometheus采集到的主机负载的样本数据,这些样本数据按照时间先后顺序展示,形成了主机负载随时间变化的趋势图表:
PromQL是Prometheus自定义的一套强大的数据查询语言,除了使用监控指标作为查询关键字以为,还内置了大量的函数,帮助用户进一步对时序数据进行处理。例如使用rate()函数,可以计算在单位时间内样本数据的变化情况即增长率,因此通过该函数我们可以近似的通过CPU使用时间计算CPU的利用率:
rate(node_cpu_seconds_total[2m])
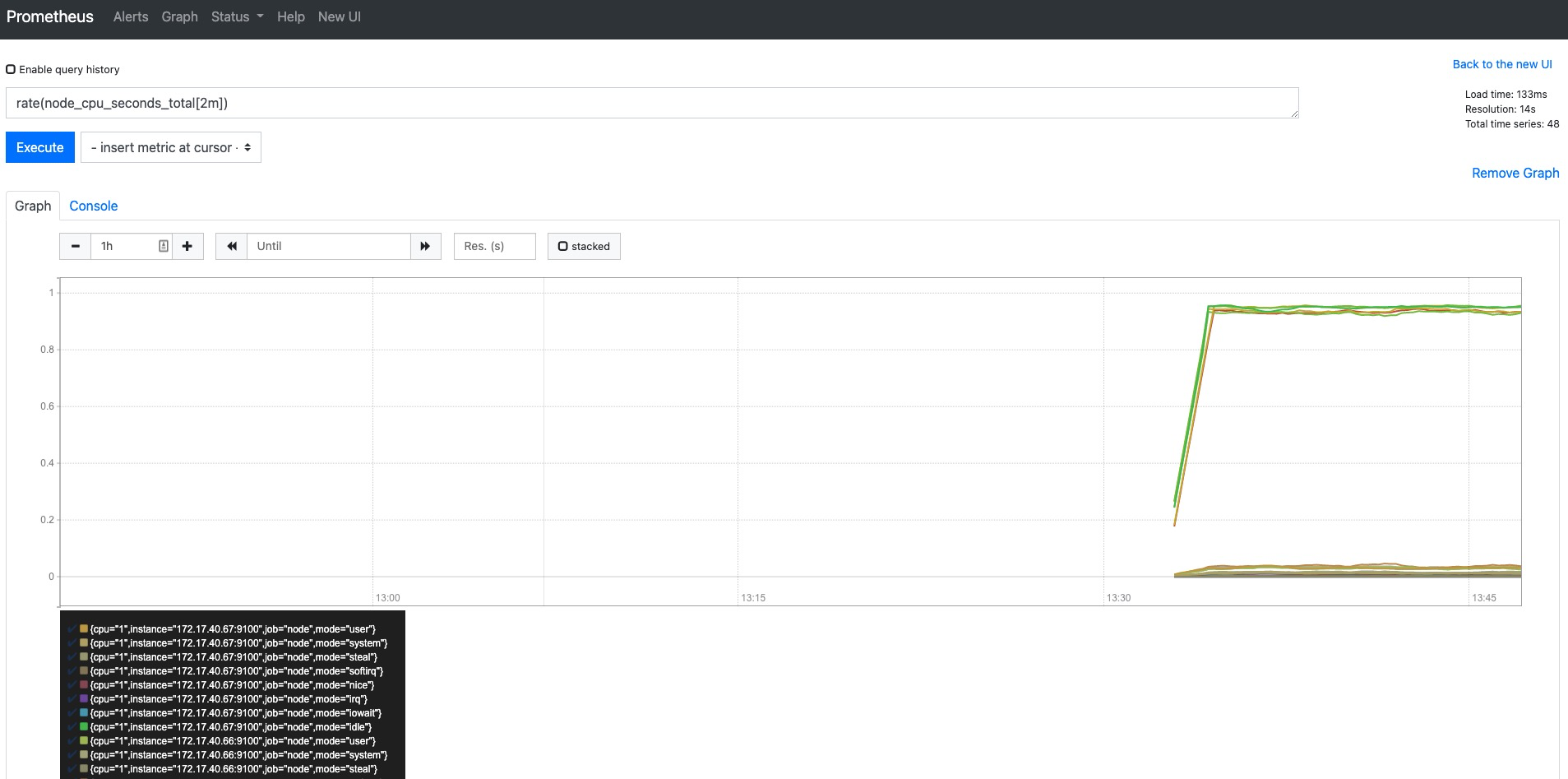
这时如果要忽略是哪一个CPU的,只需要使用without表达式,将标签CPU去除后聚合数据即可:
avg without(cpu) (rate(node_cpu[2m]))
那如果需要计算系统CPU的总体使用率,通过排除系统闲置的CPU使用率即可获得:
1 - avg without(cpu) (rate(node_cpu{mode="idle"}[2m]))
通过PromQL我们可以非常方便的对数据进行查询,过滤,以及聚合,计算等操作。通过这些丰富的表达书语句,监控指标不再是一个单独存在的个体,而是一个个能够表达出正式业务含义的语言。
监控数据可视化
Prometheus UI提供了快速验证PromQL以及临时可视化支持的能力,而在大多数场景下引入监控系统通常还需要构建可以长期使用的监控数据可视化面板(Dashboard)。这时用户可以考虑使用第三方的可视化工具如Grafana,Grafana是一个开源的可视化平台,并且提供了对Prometheus的完整支持。
docker run -d -p 3000:3000 grafana/grafana
访问http://localhost:3000就可以进入到Grafana的界面中,默认情况下使用账户admin/admin进行登录。在Grafana首页中显示默认的使用向导,包括:安装、添加数据源、创建Dashboard、邀请成员、以及安装应用和插件等主要流程:
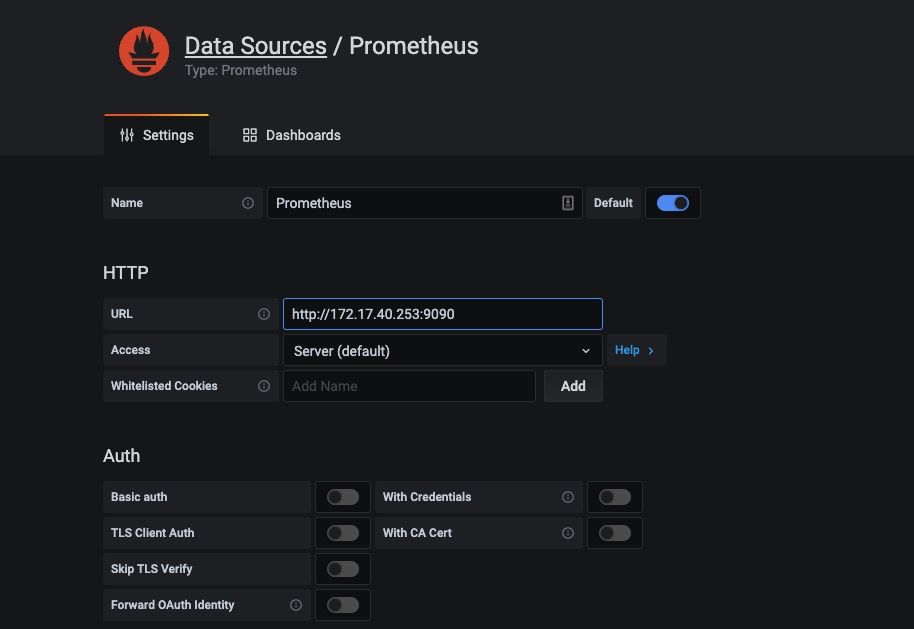
这里将添加Prometheus作为默认的数据源,如下图所示,指定数据源类型为Prometheus并且设置Prometheus的访问地址即可,在配置正确的情况下点击“Add”按钮,会提示连接成功的信息:
在完成数据源的添加之后就可以在Grafana中创建我们可视化Dashboard了。Grafana提供了对PromQL的完整支持,如下所示,通过Grafana添加Dashboard并且为该Dashboard添加一个panel。 并在该面板的“Query”选项下通过PromQL查询需要可视化的数据:
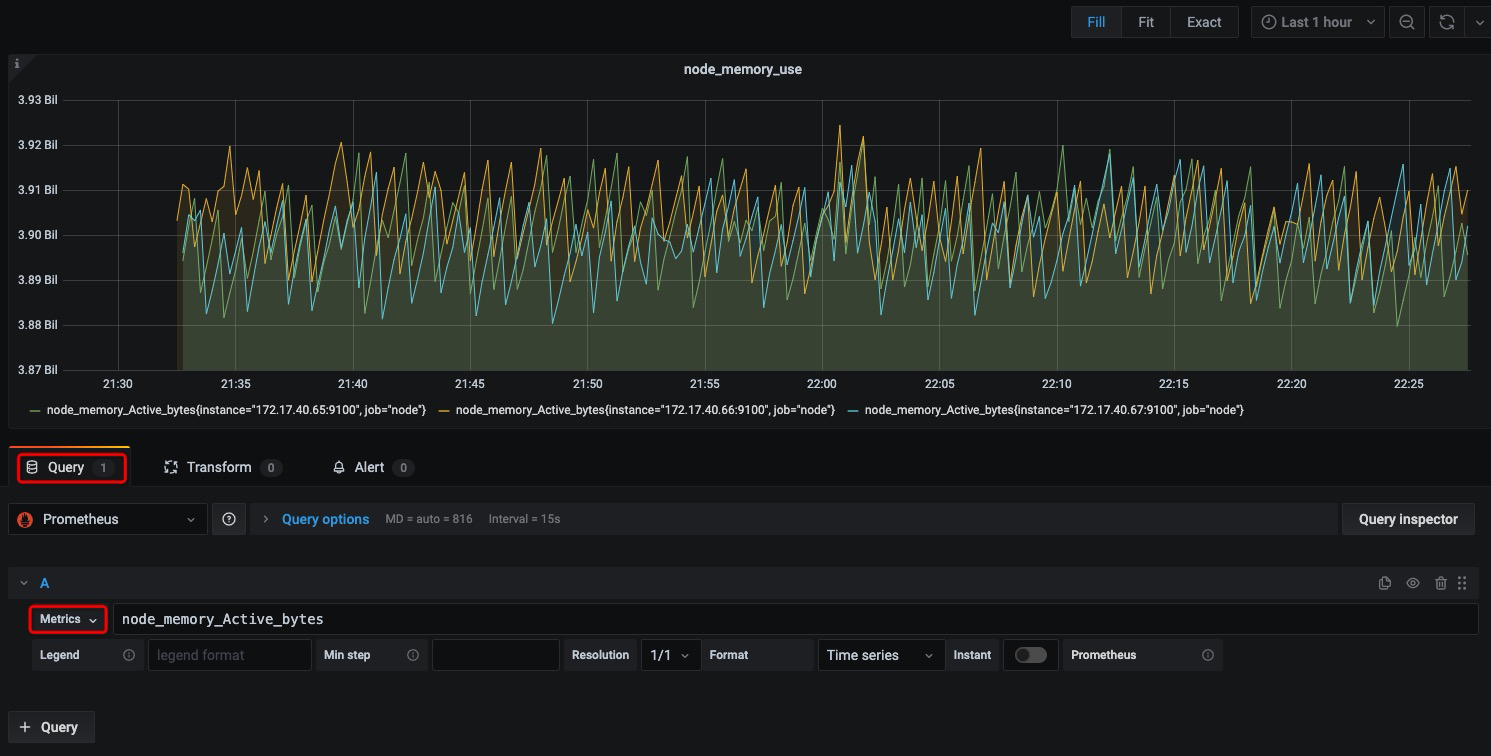
点击界面中的保存选项,就创建了我们的第一个可视化Dashboard了。 当然作为开源软件,Grafana社区鼓励用户分享Dashboard通过https://grafana.com/dashboards网站,可以找到大量可直接使用的Dashboard:

Grafana中所有的Dashboard通过JSON进行共享,下载并且导入这些JSON文件,就可以直接使用这些已经定义好的Dashboard:
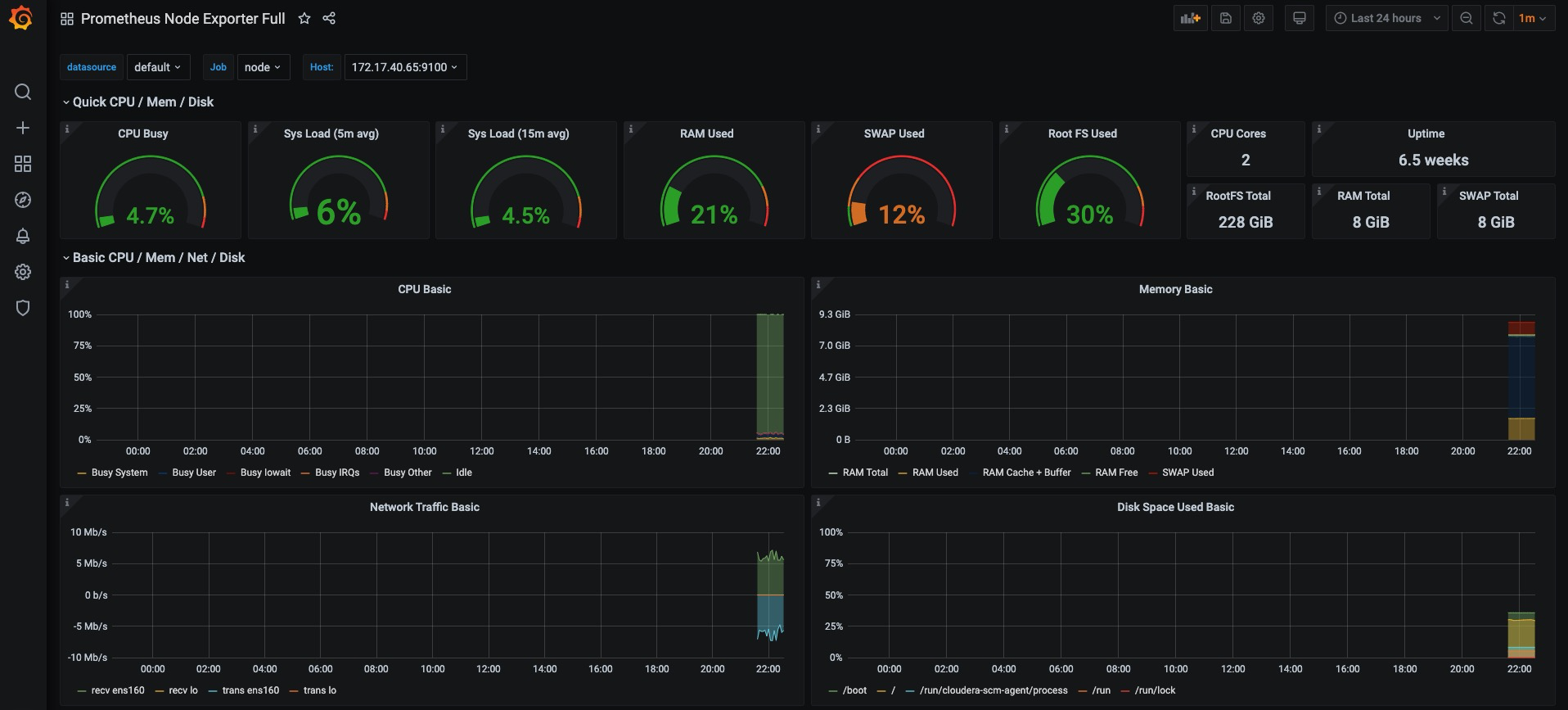
任务和实例
通过在prometheus.yml配置文件中,添加如下配置。我们让Prometheus可以从node exporter暴露的服务中获取监控指标数据。
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'node'
static_configs:
- targets: ['172.17.40.65:9100', '172.17.40.66:9100', '172.17.40.67:9100']
当我们需要采集不同的监控指标(例如:主机、MySQL、Nginx)时,我们只需要运行相应的监控采集程序,并且让Prometheus Server知道这些Exporter实例的访问地址。在Prometheus中,每一个暴露监控样本数据的HTTP服务称为一个实例。例如在当前主机上运行的node exporter可以被称为一个实例(Instance)。
而一组用于相同采集目的的实例,或者同一个采集进程的多个副本则通过一个一个任务(Job)进行管理。
* job: node
* instance 2: 172.17.40.65:9100
* instance 4: 172.17.40.66:9100
当前在每一个Job中主要使用了静态配置(static_configs)的方式定义监控目标。除了静态配置每一个Job的采集Instance地址以外,Prometheus还支持与DNS、Consul、E2C、Kubernetes等进行集成实现自动发现Instance实例,并从这些Instance上获取监控数据。
除了通过使用“up”表达式查询当前所有Instance的状态以外,还可以通过Prometheus UI中的Targets页面查看当前所有的监控采集任务,以及各个任务下所有实例的状态:
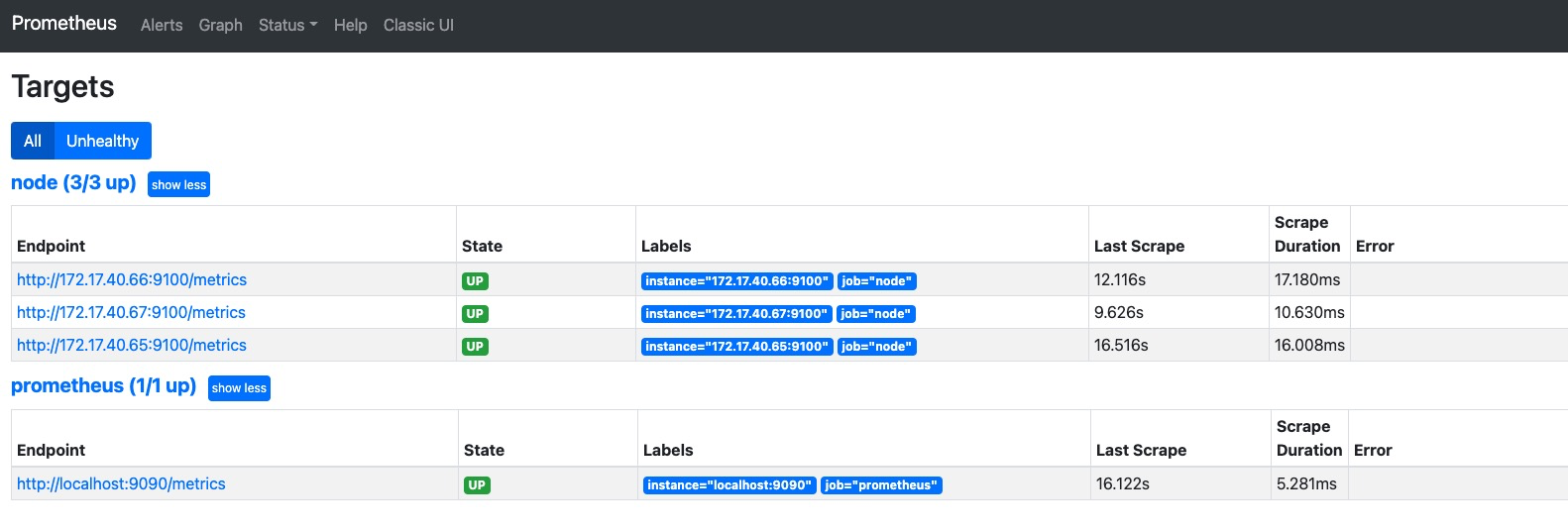
Prometheus核心组件
通过部署Node Exporter我们成功的获取到了当前主机的资源使用情况。接下来我们将从Prometheus的架构角度详细介绍Prometheus生态中的各个组件。
下图展示Prometheus的基本架构:
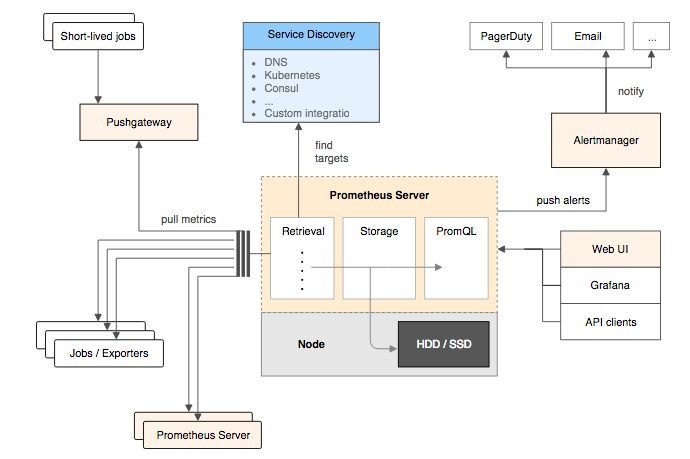
Prometheus Server
Prometheus Server是Prometheus组件中的核心部分,负责实现对监控数据的获取,存储以及查询。 Prometheus Server可以通过静态配置管理监控目标,也可以配合使用Service Discovery的方式动态管理监控目标,并从这些监控目标中获取数据。其次Prometheus Server需要对采集到的监控数据进行存储,Prometheus Server本身就是一个时序数据库,将采集到的监控数据按照时间序列的方式存储在本地磁盘当中。最后Prometheus Server对外提供了自定义的PromQL语言,实现对数据的查询以及分析。
Prometheus Server内置的Express Browser UI,通过这个UI可以直接通过PromQL实现数据的查询以及可视化。
Prometheus Server的联邦集群能力可以使其从其他的Prometheus Server实例中获取数据,因此在大规模监控的情况下,可以通过联邦集群以及功能分区的方式对Prometheus Server进行扩展。
Exporters
Exporter将监控数据采集的端点通过HTTP服务的形式暴露给Prometheus Server,Prometheus Server通过访问该Exporter提供的Endpoint端点,即可获取到需要采集的监控数据。
一般来说可以将Exporter分为2类:
- 直接采集:这一类Exporter直接内置了对Prometheus监控的支持,比如cAdvisor,Kubernetes,Etcd,Gokit等,都直接内置了用于向Prometheus暴露监控数据的端点。
- 间接采集:间接采集,原有监控目标并不直接支持Prometheus,因此我们需要通过Prometheus提供的Client Library编写该监控目标的监控采集程序。例如: Mysql Exporter,JMX Exporter,Consul Exporter等。
AlertManager
在Prometheus Server中支持基于PromQL创建告警规则,如果满足PromQL定义的规则,则会产生一条告警,而告警的后续处理流程则由AlertManager进行管理。在AlertManager中我们可以与邮件,Slack等等内置的通知方式进行集成,也可以通过Webhook自定义告警处理方式。AlertManager即Prometheus体系中的告警处理中心。
PushGateway
由于Prometheus数据采集基于Pull模型进行设计,因此在网络环境的配置上必须要让Prometheus Server能够直接与Exporter进行通信。 当这种网络需求无法直接满足时,就可以利用PushGateway来进行中转。可以通过PushGateway将内部网络的监控数据主动Push到Gateway当中。而Prometheus Server则可以采用同样Pull的方式从PushGateway中获取到监控数据。
参考链接:
https://yunlzheng.gitbook.io/prometheus-book/parti-prometheus-ji-chu/quickstart














 4700
4700











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









