创建数据表t_grade SELECT * FROM t_grade tg
WHERE ( SELECT COUNT ( * ) FROM t_grade
WHERE tg. name = t_grade. name
AND score >= tg. score
) <= 3 ORDER BY name, score DESC ;
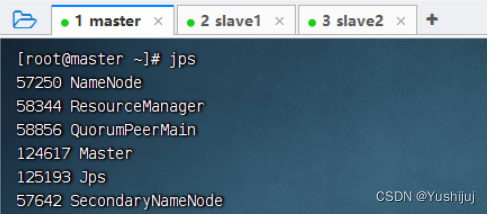
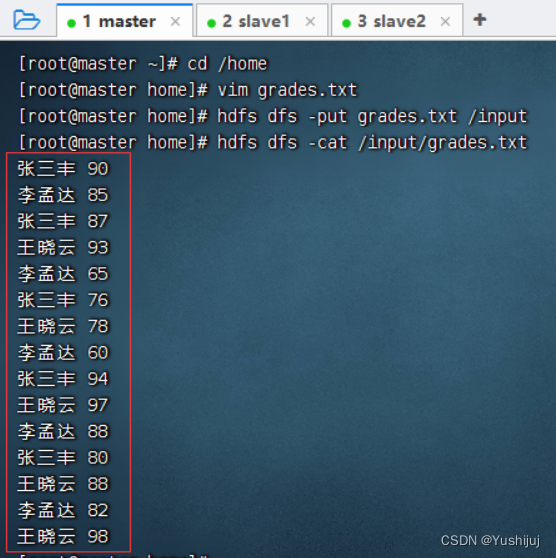
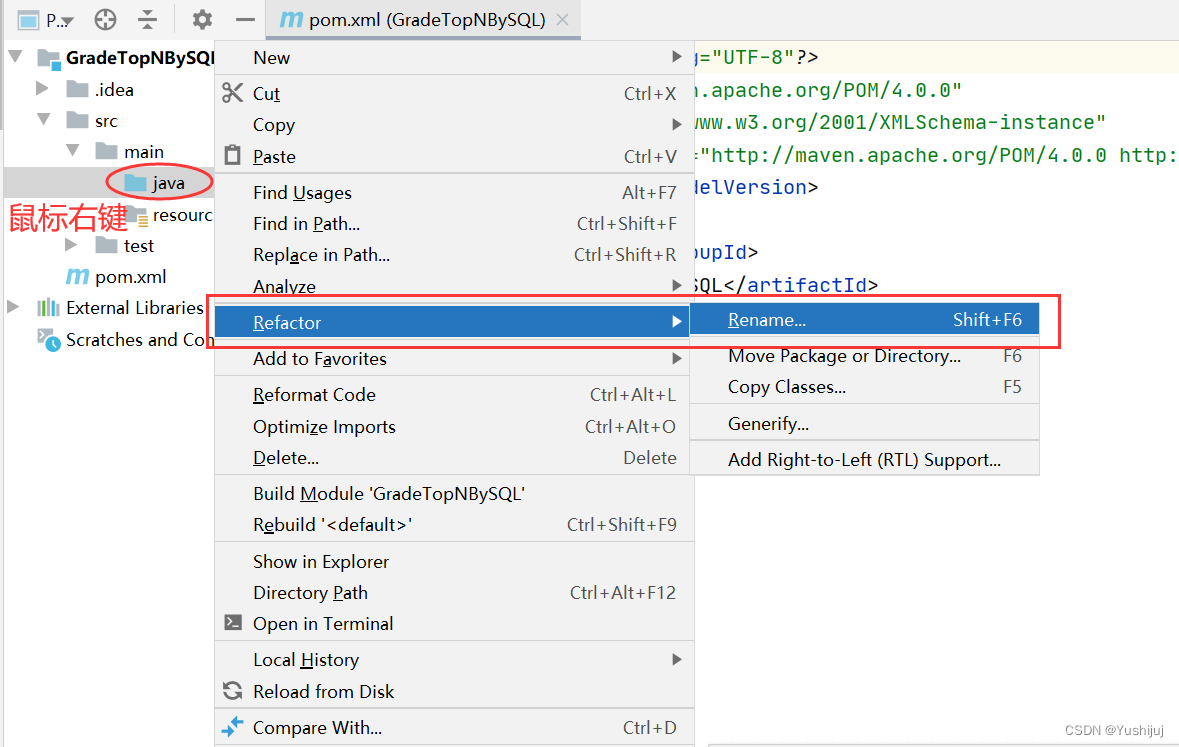
预备工作:启动集群的HDFS与Spark 将成绩文件 - grades.txt上传到HDFS上/input目录 Spark 1.5.x版本以后,在Spark SQL和DataFrame中引入了开窗函数,其中比较常用的开窗函数就是row_number(),该函数的作用是根据表中字段进行分组,然后根据表中的字段排序;其实就是根据其排序顺序,给组中的每条记录添加一个序号,且每组序号都是从1开始,可利用它这个特性进行分组取topN。 ROW_NUMBER() OVER (PARTITION BY field1 ORDER BY field2 DESC) rank 分组求top3的SQL语句 设置项目信息(项目名、保存位置、组编号、项目编号) 将java目录改成scala目录
在pom.xml文件里添加依赖与Maven构建插件 < ? xml version= "1.0" encoding= "UTF-8" ? >
< project xmlns= "http://maven.apache.org/POM/4.0.0"
xmlns: xsi= "http://www.w3.org/2001/XMLSchema-instance"
xsi: schemaLocation= "http: / / maven. apache. org/ POM/ 4.0 .0
http: / / maven. apache. org/ xsd/ maven- 4.0 .0 . xsd">
< modelVersion> 4.0 .0 < / modelVersion>
< groupId> . cb. sql< / groupId>
< artifactId> GradeTopNBySQL < / artifactId>
< version> 1.0 - SNAPSHOT< / version>
< dependencies> < dependency> < groupId> . scala- lang< / groupId>
< artifactId> - library< / artifactId>
< version> 2.11 .12 < / version>
< / dependency>
< dependency> < groupId> . apache. spark< / groupId>
< artifactId> - core_2. 11 < / artifactId>
< version> 2.1 .1 < / version>
< / dependency>
< dependency> < groupId> . apache. spark< / groupId>
< artifactId> - sql_2. 11 < / artifactId>
< version> 2.1 .1 < / version>
< / dependency>
< / dependencies>
< build> < sourceDirectory> / main/ scala< / sourceDirectory>
< plugins> < plugin> < groupId> . apache. maven. plugins< / groupId>
< artifactId> - assembly- plugin< / artifactId>
< version> 3.3 .0 < / version>
< configuration> < descriptorRefs> < descriptorRef> - with - dependencies< / descriptorRef>
< / descriptorRefs>
< / configuration>
< executions> < execution> < id> - assembly< / id>
< phase> package < / phase>
< goals> < goal> < / goal>
< / goals>
< / execution>
< / executions>
< / plugin>
< plugin> < groupId> . alchim31. maven< / groupId>
< artifactId> - maven- plugin< / artifactId>
< version> 3.3 .2 < / version>
< executions> < execution> < id> - compile- first< / id>
< phase> - resources< / phase>
< goals> < goal> - source< / goal>
< goal> < / goal>
< / goals>
< / execution>
< execution> < id> - test- compile< / id>
< phase> - test- resources< / phase>
< goals> < goal> < / goal>
< / goals>
< / execution>
< / executions>
< / plugin>
< / plugins>
< / build>
< / project>
在资源文件夹里创建日志属性文件 - log4j.properties log4j. rootLogger= ERROR, stdout, logfile
log4j. appender. stdout= org. apache. log4j. ConsoleAppender. appender. stdout. layout= org. apache. log4j. PatternLayoutlog4j. appender. stdout. layout. ConversionPattern= % d % p [ % c] - % m% n
log4j. appender. logfile= org. apache. log4j. FileAppenderlog4j. appender. logfile. File= target/ spark. log
log4j. appender. logfile. layout= org. apache. log4j. PatternLayoutlog4j. appender. logfile. layout. ConversionPattern= % d % p [ % c] - % m% n
在net.cb.sql包里创建GradeTopNBySQL单例对象 package net. cb. sql
import org. apache. spark. sql. { Dataset , SparkSession }
object GradeTopNBySQL {
def main ( args: Array [ String ] ) : Unit = {
val spark = SparkSession . builder ( )
. appName ( "GradeTopNBySQL" )
. master ( "local[*]" )
. getOrCreate ( )
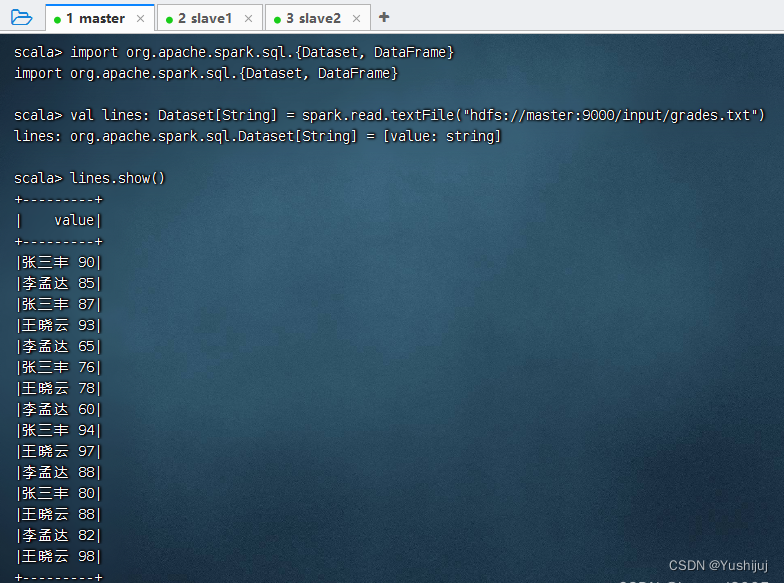
val lines: Dataset [ String ] = spark. read. textFile ( "hdfs://master:9000/input/grades.txt" )
import spark. implicits. _
val gradeDS: Dataset [ Grade ] = lines. map (
line = > { val fields = line. split ( " " )
val name = fields ( 0 )
val score = fields ( 1 ) . toInt
Grade ( name, score)
} )
val df = gradeDS. toDF ( )
df. createOrReplaceTempView ( "t_grade" )
val top3 = spark. sql (
"""
|SELECT name, score FROM
| (SELECT name, score, row_number() OVER (PARTITION BY name ORDER BY score DESC) rank from t_grade) t
| WHERE t.rank <= 3
|""" . stripMargin
)
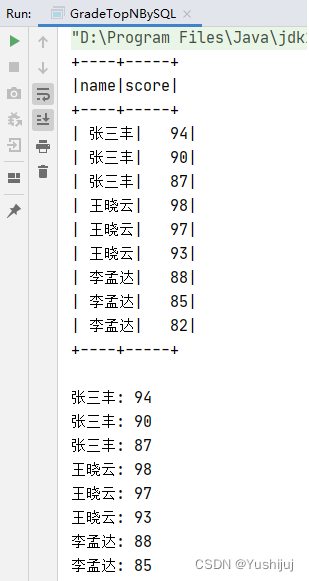
top3. show ( )
top3. foreach ( row = > println ( row ( 0 ) + ": " + row ( 1 ) ) )
spark. close ( )
}
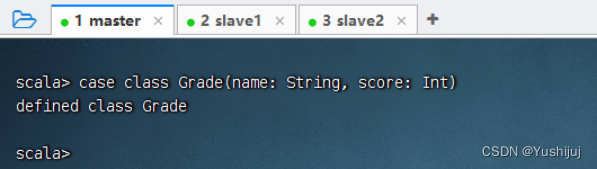
case class Grade ( name: String , score: Int )
}
在控制台查看输出结果 执行命令:val lines: Dataset[String] = spark.read.textFile("hdfs://master:9000/input/grades.txt") 执行命令:case class Grade(name: String, score: Int)
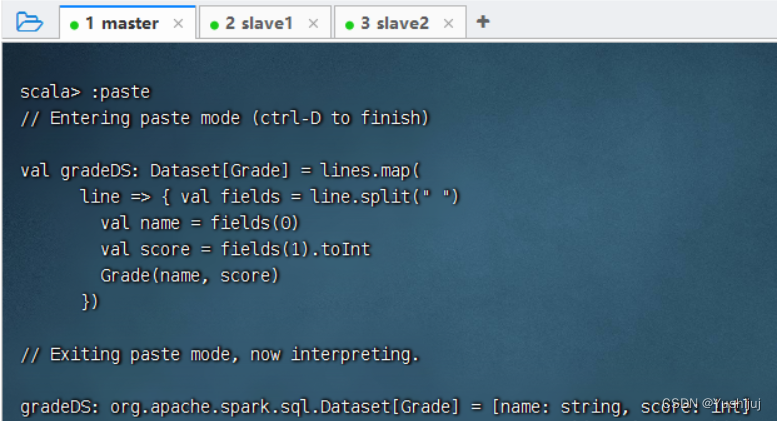
val gradeDS: Dataset[ Grade] = lines.map(
line = > { val fields = line.split( " " )
val name = fields( 0 )
val score = fields( 1 ) .toInt
Grade( name, score)
} )
执行上述语句 执行命令:val df = gradeDS.toDF()







 * 执行查询
* 执行查询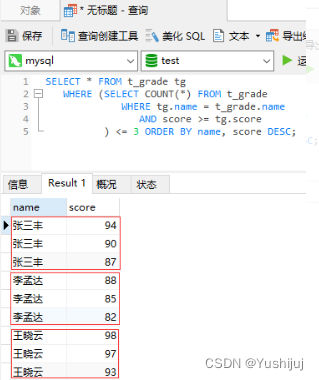




















 1084
1084











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









