






机器翻译是指将一段文本从一种语言自动翻译到另一种语言。因为一段文本序列在不同语言中的长度不一定相同,所以我们使用机器翻译为例来介绍编码器—解码器和注意力机制的应用。
主要分为读取和预处理数据,含注意力机制的编码器—解码器,训练模型和评价翻译结果四个内容。
1.读取和预处理数据
我们先定义一些特殊符号。其中“<pad>”(padding)符号用来添加在较短序列后,直到每个序列等长,而“<bos>”和“<eos>”符号分别表示序列的开始和结束。

为了演示方便,我们在这里使用一个很小的法语—英语数据集。在这个数据集里,每一行是一对法语句子和它对应的英语句子,中间使用'\t'隔开。在读取数据时,我们在句末附上“<eos>”符号,并可能通过添加“<pad>”符号使每个序列的长度均为max_seq_len。我们为法语词和英语词分别创建词典。法语词的索引和英语词的索引相互独立。
接着定义两个辅助函数对后面读取的数据进行预处理,通过Pandas库读取文本文件中的数据,然后将其中的中英文数据分别存储到trainen和trainzh两个列表中,以便后续的处理和分析。


接着处理从文件'fr-en-small.txt'中读取的句子数据,将其分为输入和输出序列,并按照设定的最大序列长度进行处理和构建数据集。

将序列的最大长度设成7,然后查看读取到的第一个样本。该样本分别包含法语词索引序列和英语词索引序列。

以下是输出结果
(tensor([ 5, 4, 45, 3, 2, 0, 0]), tensor([ 8, 4, 27, 3, 2, 0, 0]))
2.含注意力机制的编码器—解码器
我们将使用含注意力机制的编码器—解码器来将一段简短的法语翻译成英语。下面我们来介绍模型的实现。
2.1编码器
在编码器中,我们将输入语言的词索引通过词嵌入层得到词的表征,然后输入到一个多层门控循环单元中。PyTorch的nn.GRU实例在前向计算后也会分别返回输出和最终时间步的多层隐藏状态。其中的输出指的是最后一层的隐藏层在各个时间步的隐藏状态,并不涉及输出层计算。注意力机制将这些输出作为键项和值项。
接下来实现一个简单的RNN编码器模型,用于将输入序列编码成隐藏表示。

下面我们来创建一个批量大小为4、时间步数为7的小批量序列输入。设门控循环单元的隐藏层个数为2,隐藏单元个数为16。编码器对该输入执行前向计算后返回的输出形状为(时间步数, 批量大小, 隐藏单元个数)。门控循环单元在最终时间步的多层隐藏状态的形状为(隐藏层个数, 批量大小, 隐藏单元个数)。对于门控循环单元来说,state就是一个元素,即隐藏状态;如果使用长短期记忆,state是一个元组,包含两个元素即隐藏状态和记忆细胞。

以下是输出结果 (torch.Size([7, 4, 16]), torch.Size([2, 4, 16]))
2.2注意力机制
我们将实现函数[Math Processing Error]:将输入连结后通过含单隐藏层的多层感知机变换。其中隐藏层的输入是解码器的隐藏状态与编码器在所有时间步上隐藏状态的一一连结,且使用tanh函数作为激活函数。输出层的输出个数为1。两个Linear实例均不使用偏差。其中函数[MathProcessing Error]定义里向量[Math Processing Error]的长度是一个超参数,即attention_size。

注意力机制的输入包括查询项、键项和值项。设编码器和解码器的隐藏单元个数相同。这里的查询项为解码器在上一时间步的隐藏状态,形状为(批量大小, 隐藏单元个数);键项和值项均为编码器在所有时间步的隐藏状态,形状为(时间步数, 批量大小, 隐藏单元个数)。注意力机制返回当前时间步的背景变量,形状为(批量大小, 隐藏单元个数)。

在下面的例子中,编码器的时间步数为10,批量大小为4,编码器和解码器的隐藏单元个数均为8。注意力机制返回一个小批量的背景向量,每个背景向量的长度等于编码器的隐藏单元个数。因此输出的形状为(4, 8)。

以下是输出结果
torch.Size([4, 8])
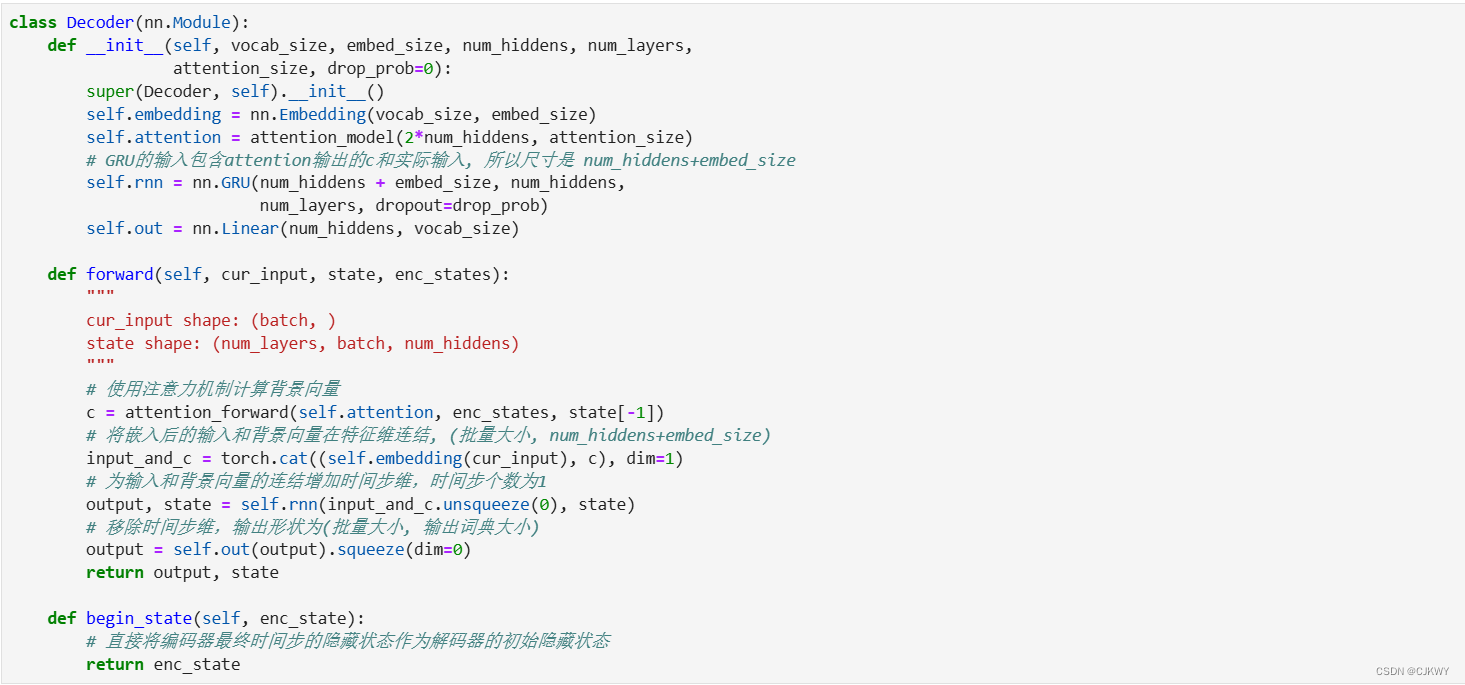
2.3含注意力机制的解码器
我们直接将编码器在最终时间步的隐藏状态作为解码器的初始隐藏状态。这要求编码器和解码器的循环神经网络使用相同的隐藏层个数和隐藏单元个数。
在解码器的前向计算中,我们先通过刚刚介绍的注意力机制计算得到当前时间步的背景向量。由于解码器的输入来自输出语言的词索引,我们将输入通过词嵌入层得到表征,然后和背景向量在特征维连结。我们将连结后的结果与上一时间步的隐藏状态通过门控循环单元计算出当前时间步的输出与隐藏状态。最后,我们将输出通过全连接层变换为有关各个输出词的预测,形状为(批量大小, 输出词典大小)。
3.训练模型
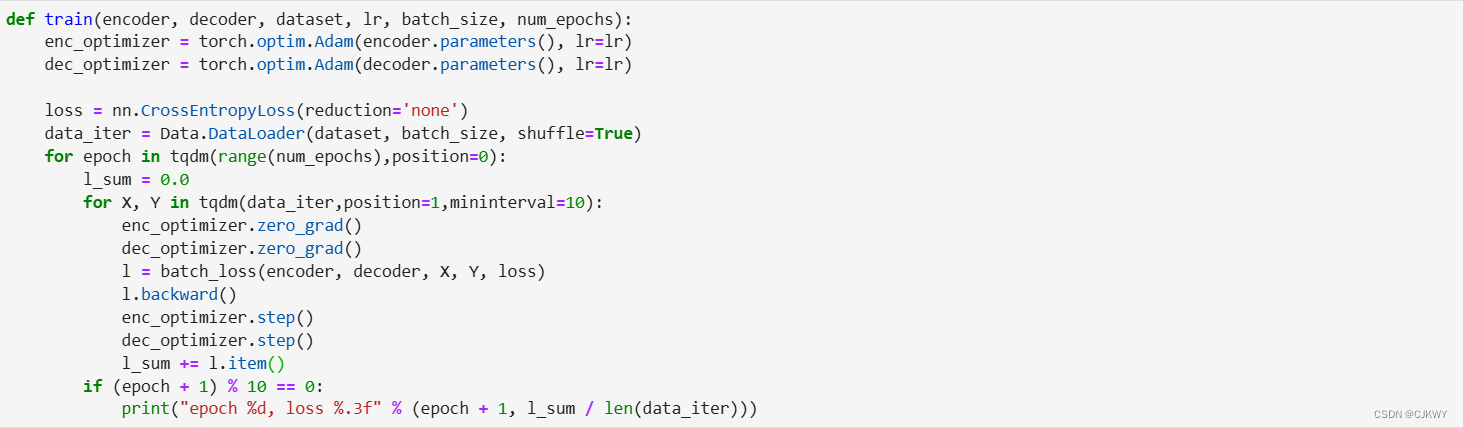
我们先实现`batch_loss`函数计算一个小批量的损失。解码器在最初时间步的输入是特殊字符`BOS`。之后,解码器在某时间步的输入为样本输出序列在上一时间步的词,即强制教学。此外,同10.3节(word2vec的实现)中的实现一样,我们在这里也使用掩码变量避免填充项对损失函数计算的影响。

在训练函数中,我们需要同时迭代编码器和解码器的模型参数。
接下来,创建模型实例并设置超参数。然后,我们就可以训练模型了。

4.评价翻译结果
评价机器翻译结果通常使用BLEU(Bilingual Evaluation Understudy)[1]。对于模型预测序列中任意的子序列,BLEU考察这个子序列是否出现在标签序列中。
具体来说,设词数为𝑛𝑛的子序列的精度为𝑝𝑛𝑝𝑛。它是预测序列与标签序列匹配词数为𝑛𝑛的子序列的数量与预测序列中词数为𝑛𝑛的子序列的数量之比。举个例子,假设标签序列为𝐴𝐴、𝐵𝐵、𝐶𝐶、𝐷𝐷、𝐸𝐸、𝐹𝐹,预测序列为𝐴𝐴、𝐵𝐵、𝐵𝐵、𝐶𝐶、𝐷𝐷,那么𝑝1=4/5,𝑝2=3/4,𝑝3=1/3,𝑝4=0𝑝1=4/5,𝑝2=3/4,𝑝3=1/3,𝑝4=0。设𝑙𝑒𝑛label𝑙𝑒𝑛label和𝑙𝑒𝑛pred𝑙𝑒𝑛pred分别为标签序列和预测序列的词数,那么,BLEU的定义为
exp(min(0,1−𝑙𝑒𝑛label𝑙𝑒𝑛pred))∏𝑛=1𝑘𝑝1/2𝑛𝑛,exp(min(0,1−𝑙𝑒𝑛label𝑙𝑒𝑛pred))∏𝑛=1𝑘𝑝𝑛1/2𝑛,
其中𝑘𝑘是我们希望匹配的子序列的最大词数。可以看到当预测序列和标签序列完全一致时,BLEU为1。
因为匹配较长子序列比匹配较短子序列更难,BLEU对匹配较长子序列的精度赋予了更大权重。例如,当𝑝𝑛𝑝𝑛固定在0.5时,随着𝑛𝑛的增大,0.51/2≈0.7,0.51/4≈0.84,0.51/8≈0.92,0.51/16≈0.960.51/2≈0.7,0.51/4≈0.84,0.51/8≈0.92,0.51/16≈0.96。另外,模型预测较短序列往往会得到较高𝑝𝑛𝑝𝑛值。因此,上式中连乘项前面的系数是为了惩罚较短的输出而设的。举个例子,当𝑘=2𝑘=2时,假设标签序列为𝐴𝐴、𝐵𝐵、𝐶𝐶、𝐷𝐷、𝐸𝐸、𝐹𝐹,而预测序列为𝐴𝐴、𝐵𝐵。虽然𝑝1=𝑝2=1𝑝1=𝑝2=1,但惩罚系数exp(1−6/2)≈0.14exp(1−6/2)≈0.14,因此BLEU也接近0.14。
下面来实现BLEU的计算。

接下来,定义一个辅助打印函数。

预测正确则分数为1。

参考文献
[1] Papineni, K., Roukos, S., Ward, T., & Zhu, W. J. (2002, July). BLEU: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting on association for computational linguistics (pp. 311-318). Association for Computational Linguistics.
[2] WMT. Translation Task - ACL 2014 Ninth Workshop on Statistical Machine Translation
[3] Tatoeba Project. Tab-delimited Bilingual Sentence Pairs from the Tatoeba Project (Good for Anki and Similar Flashcard Applications)















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









