






Transformer 是一种用于自然语言处理任务的深度学习模型架构,首次由Vaswani等人在2017年提出。它引入了自注意力机制(self-attention mechanism),在处理长距离依赖关系时相对于传统的循环神经网络(RNN)和长短时记忆网络(LSTM)具有更好的性能。
Transformer 模型的核心是多头自注意力机制和位置编码。自注意力机制允许模型在计算时同时考虑输入序列的所有位置,从而更好地捕捉序列中不同位置之间的依赖关系。多头自注意力机制允许模型并行地学习多组自注意力表示,增强了模型对不同方面信息的建模能力。位置编码用于反映输入序列中单词的位置信息,帮助模型区分不同位置的单词。
Transformer 模型还包括多层自注意力层和全连接前馈神经网络层,通过堆叠这些层构建深层网络结构。在训练过程中,Transformer 使用残差连接和层归一化来帮助有效训练深层模型。通过编码器-解码器结构,Transformer 在翻译等序列到序列任务中取得了巨大成功,成为自然语言处理领域的重要里程碑之一。
以下使用 Jupyter Notebook、PyTorch、Torchtext 和 SentencePiece 的基于 Transformer 的日中机器翻译模型教程的简单复现。
导入必要的包
首先,确保您的系统已安装以下包,若发现缺少某些包,则需要安装它们。

获取平行数据集
在这个教程中,我们将使用从JParaCrawl(http://www.kecl.ntt.co.jp/icl/lirg/jparacrawl)下载的日语-英语平行数据集。JParaCrawl被描述为“由NTT创建的最大的公开可用的英语-日语平行语料库。它是通过在网页上大规模抓取并自动对齐平行句子来创建的。” 您也可以在这里查看相关论文。

在导入所有的日语句子及其对应的英语句子后,我删除了数据集中的最后一条数据,因为它存在缺失值。总共,在训练集trainen和trainja中,句子的数量为5,973,071条,然而,为了学习目的,通常建议对数据进行抽样,并确保一切按预期工作,然后再使用全部数据,以节省时间。
以下是数据集中包含的一条句子的示例。
当然我们也可以使用不同的平行数据集来跟随本文,只需确保我们可以将数据处理成如上所示的两个字符串列表,分别包含日语和英语句子。
准备分词器
不同于英语或其他字母语言,日语句子中没有空格来分隔单词。我们可以使用JParaCrawl提供的分词器,该分词器是使用SentencePiece为日语和英语创建的,您可以访问JParaCrawl网站下载分词器。

在加载分词器之后,您可以通过执行以下代码来测试它们,例如: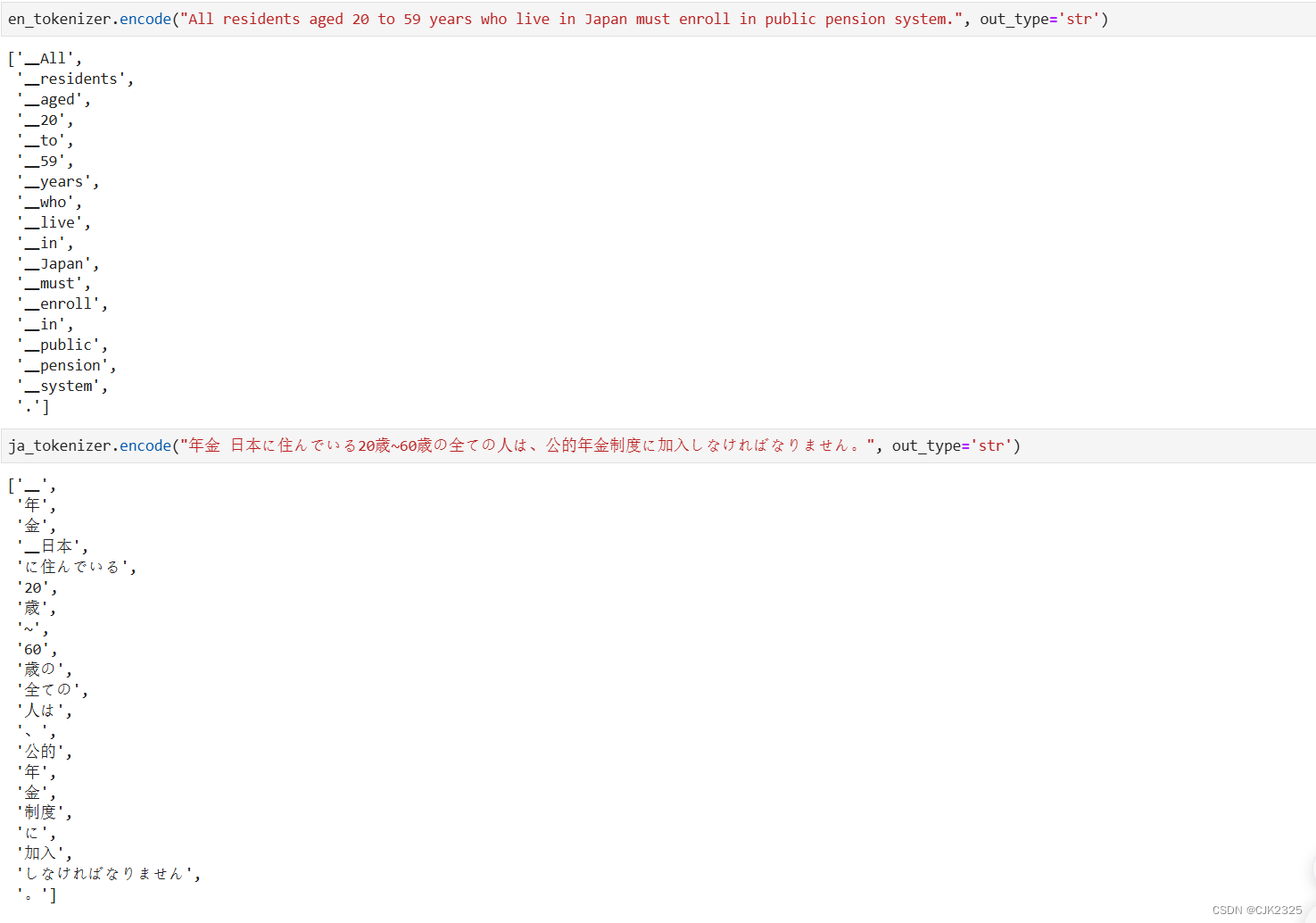
构建TorchText的词汇对象并将句子转换为Torch张量
使用标记器和原始句子,然后构建从 TorchText 导入的词汇对象。 这个过程可能需要几秒钟或几分钟,具体取决于我们数据集的大小和计算能力。 不同的标记器也会影响构建词汇所需的时间,我尝试了几种其他的日语标记器,但 SentencePiece 似乎对我来说运行得很好,而且足够快。

获得了词汇对象之后,我们就可以使用词汇表和分词器对象来构建训练数据的张量。

创建DataLoader对象以便在训练过程中进行迭代
这里,我将批大小设置为16,以防止“cuda内存不足”的问题,但这取决于诸如你的机器内存容量,数据大小等各种因素,所以根据你的需求随意更改批大小(注意:PyTorch的教程使用Multi30k德英数据集时将批大小设置为128)。

序列到序列Transformer
接下来的几段代码和文本说明(用斜体字书写)来自原始的PyTorch教程[https://pytorch.org/tutorials/beginner/translation_transformer.html]。我没有做任何改变,除了批量大小BATCH_SIZE和单词de_vocab被更改为ja_vocab。
Transformer是一种用于解决机器翻译任务的Seq2Seq模型,在“Attention is all you need”论文中引入。Transformer模型包括一个编码器和一个解码器块,每个块都包含固定数量的层。
编码器通过一系列多头注意力和前馈网络层将输入序列处理,输出称为记忆(memory),将其与目标张量一起传递给解码器。编码器和解码器使用教师强制技术进行端到端训练。

文本标记通过使用标记嵌入来表示。在标记嵌入中添加位置编码,引入了单词顺序的概念。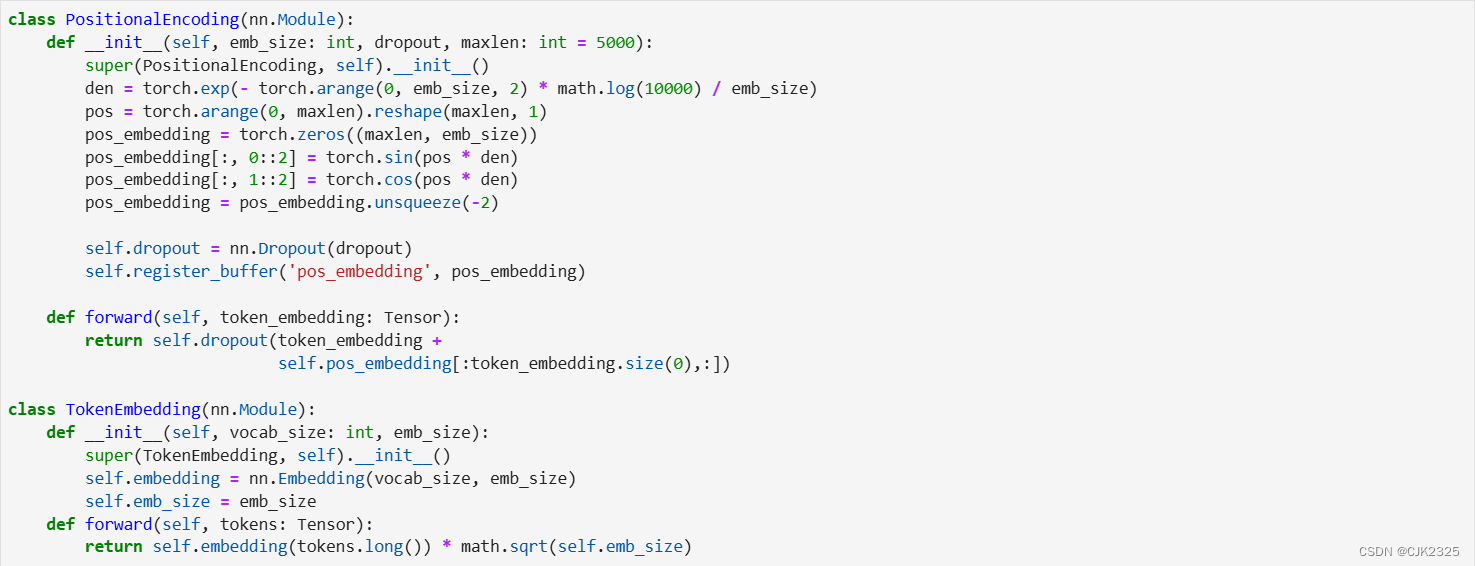
我们创建一个后续词掩码,以阻止目标词关注其后续词。我们还创建了用于遮盖源和目标填充标记的掩码。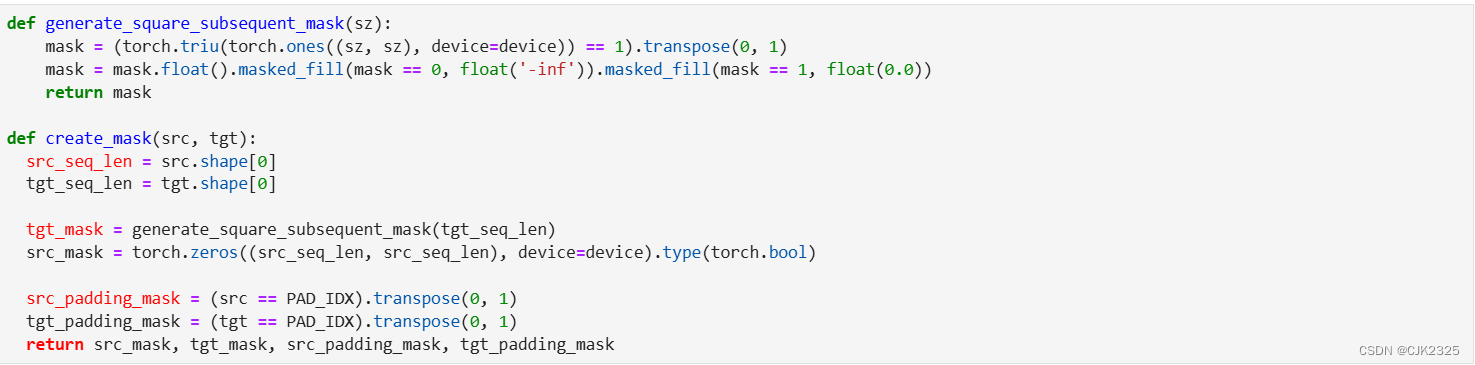
定义模型参数并实例化模型
这里我的服务器实在是计算能力有限,按照以下配置可以训练但是效果应该是不行的。如果想要看到训练的效果请使用你自己的带GPU的电脑运行这一套代码。
当你使用自己的GPU的时候,NUM_ENCODER_LAYERS 和 NUM_DECODER_LAYERS 设置为3或者更高,NHEAD设置8,EMB_SIZE设置为512。
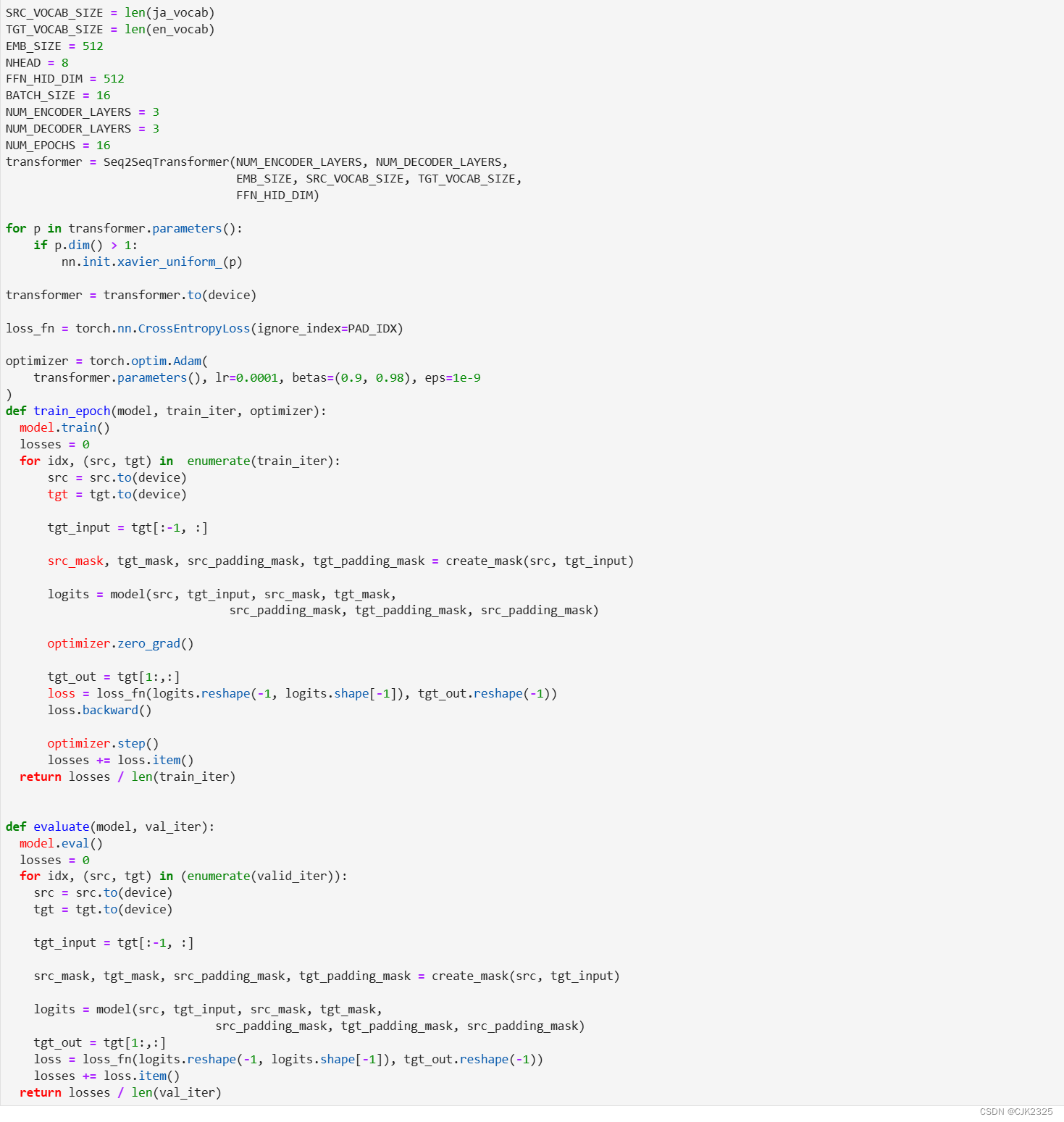
开始训练
最后,在准备好必要的类和函数后,我们准备训练我们的模型。不言而喻,训练完成所需的时间可能会因计算能力、参数以及数据集大小等许多因素而大不相同。
当我使用JParaCrawl的完整句子列表(每种语言约590万个句子)来训练模型时,使用单个NVIDIA GeForce RTX 3070 GPU,每轮训练大约需要5个小时。
以下是代码:
尝试使用训练好的模型翻译一句日语句子
首先,我们创建一个函数来翻译新句子,包括获取日语句子、标记化、转换为张量、推理,然后将结果解码成英文句子。
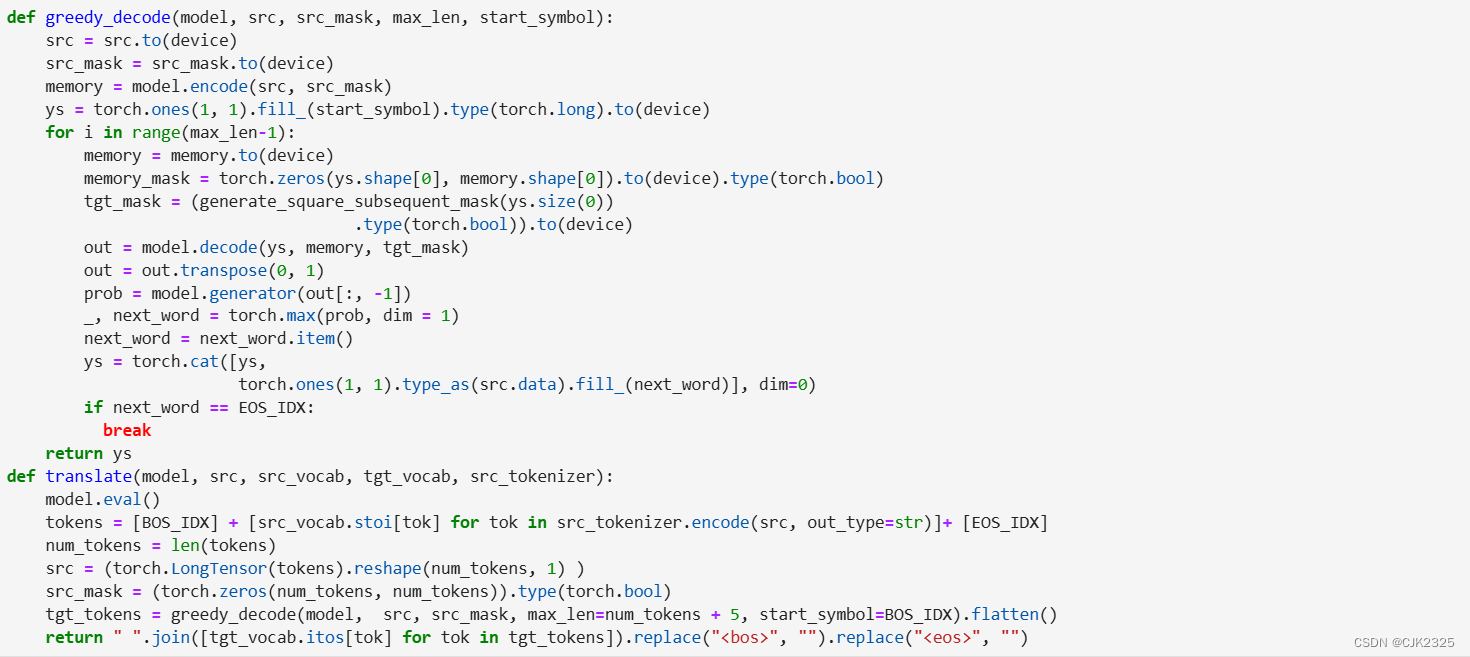
然后,我们只需调用翻译函数并传递所需的参数。

保存Vocab对象和训练好的模型
最后,在训练结束后,我们将首先使用 Pickle 保存词汇表对象(en_vocab 和 ja_vocab)。

最后,我们还可以使用 PyTorch 的保存和加载函数保存模型,以备后续使用。一般来说,根据后续使用的目的,有两种保存模型的方式。第一种只用于推理,我们可以稍后加载模型并用它来从日语翻译成英语。

第二种方式也用于推理,但当我们希望稍后加载模型并恢复训练时,也可以使用。
















 2978
2978

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









