







目录
1、const和引用的疑惑
关于const和引用的疑难问题,在前面的 第三篇 和 第七篇 文章中已经解释过了,前面多次提到符号表,这里重点解释以下符号表!
什么是符号表?符号表存储在程序中的哪个地方?
- 符号表是编译器在编译过程中产生的关于源程序中语法符号的数据结构
- 如常量表、变量名表、数组名表、函数名表等等
- 符号表是编译器自用的内部数据结构
- 符号表不会进入最终产生的可执行程序中
怎样定义const常量才会使用符号表?
- 只有用字面量初始化的const常量才会进入符号表
- 对const常量进行引用会导致编译器为其分配空间
- 虽然const常量被分配了空间,但是这个空间中的值不会被使用
- 使用其它变量初始化的const常量仍然是只读变量
- 被volatile修饰的const常量不会进入符号表
- 会退化为只读变量,每次访问都从内存中取值
- const引用的类型与初始化变量的类型
- 相同:从该引用变量的角度来说,会使初始化变量成为只读变量,即无法通过该引用变量来改变初始化变量的值
- 不同:生成一个新的只读变量,其初始值与初始化变量相同
总之,在编译期间不能直接确定初始值的const量,都被作为只读变量处理。
2、引用与指针的疑惑
指针与引用的区别
- 指针是一个变量,其值为一个内存地址,通过指针可以访问对应内存地址中的值
- 引用只是一个变量的新名字,所有对引用的操作(赋值,取地址等)都会传递到其引用的变量上
- 指针可以被const修饰成为常量或者只读变量
- const引用使其引用的变量具有只读属性
- 指针就是变量,不需要初始化,也可以指向不同的地址
- 引用天生就必须在定义时初始化,之后无法在引用其它变量
如何理解“引用的本质就是指针常量”?
- 从使用C++语言的角度来看
- 引用与指针常量没有任何的关系
- 引用是变量的新名字,操作引用就是操作对应的变量
- 从C++编译器的角度来看
- 为了支持新概念“引用”必须要一个有效的解决方案
- 在编译器内部,使用指针常量来实现“引用”,因此“引用”在定义时必须初始化
所以:
- 当进行C++编程时,直接站在使用的角度看待引用,与指针毫无关系!
- 当对C++程序中的一些涉及引用的bug或者“奇怪行为”进行分析时,可以考虑站在C++编译器的角度看待引用!
3、重载与默认类型转换
先看示例:
exp-1.cpp
#include <stdio.h>
void func(int a, int b)
{
printf("void func(int a, int b)\n");
}
void func(int a, char b)
{
printf("void func(int a, char b)\n");
}
void func(char a, int b)
{
printf("void func(char a, int b)\n");
}
void func(char a, char b)
{
printf("void func(char a, char b)\n");
}
int main()
{
int a = 1;
char b = '2';
func(a, a);
func(a, b);
func(b, a);
func(b, b);
printf("*************************************\n");
func(1, 2);
func(1, '2');
func('1', 2);
func('1', '2');
return 0;
}
运行结果:
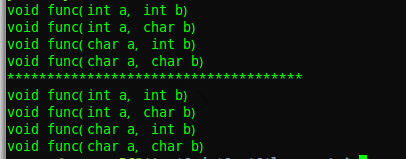
从运行结果来看,每个函数都按照我们想要的方式进行了匹配,但是我们通过字面值常量来调用函数时,编译器实际上做了默认的类型转换,这才使得函数匹配成功,但也正是由于默认的类型转换,可能就会导致匹配不像我们想象的那样进行!
C++编译器对字面量的处理方式
- 整数型字面量的默认类型为int,占用4个字节
- 浮点型字面量的默认类型为double,占用8个字节
- 字符型字面量的默认类型为char,占用1个字节
- 字符串型字面量的默认类型为const char*,占用4个字节
当使用字面量对变量进行初始化或赋值时
- 无溢出产生:编译器对字面量进行默认类型转换
- 产生溢出:编译器会做截断操作,并产生警告
深入理解重载规则
- 精确匹配实参
- 通过默认类型转换匹配实参
- 通过默认参数匹配实参
三条规则会同时对已存在的重载函数进行挑选
- 当实参为变量并能够精确匹配形参时,不再进行默认类型转换的尝试。
- 当实参为字面量时,编译器会同时进行精确匹配和默认类型转换的尝试。
4、C方式编译的疑惑
深入理解extern “C”
- extern “C”告诉编C++译器将其中的代码进行C方式的编译
- C方式的编译主要指按照C语言的规则对函数名进行编译
- 函数名经过编译后可能与源码中的名字有所不同
- C++编译器为了支持重载,函数名经过编译后会加上参数信息等附加信息,因而编译后的函数名与源码中完全不同,且每个重载函数的函数名都不一样
- C编译器不会在编译后的函数名中加上参数信息,与源代码中函数名一样
- C方式的编译主要指按照C语言的规则对函数名进行编译
示例:
exp-2.cpp
#include <stdio.h>
extern "C"
{
void func()
{
const int i = 1;
int& ri = const_cast<int&>(i);
ri = 5;
printf("i = %d\n", i);
printf("ri = %d\n", ri);
}
}
void func(const char* s)
{
printf("%s\n", s);
}
int func(int a, int b)
{
return a + b;
}
int main()
{
func();
func("Hello Linux!");
func(1, 2);
return 0;
}这里有三个重载函数,无参数的func函数被指定用C语言方式编译,现在编译两个版本:
第一版:无参数的func函数采用C语言方式编译;
第二版:无参数的func函数采用C++方式编译,即去掉extern “C”
编译命令:
g++ -S main.cpp -o main.s
g++ -S main.cpp -o main_cpp.s对比两次生成的汇编代码:
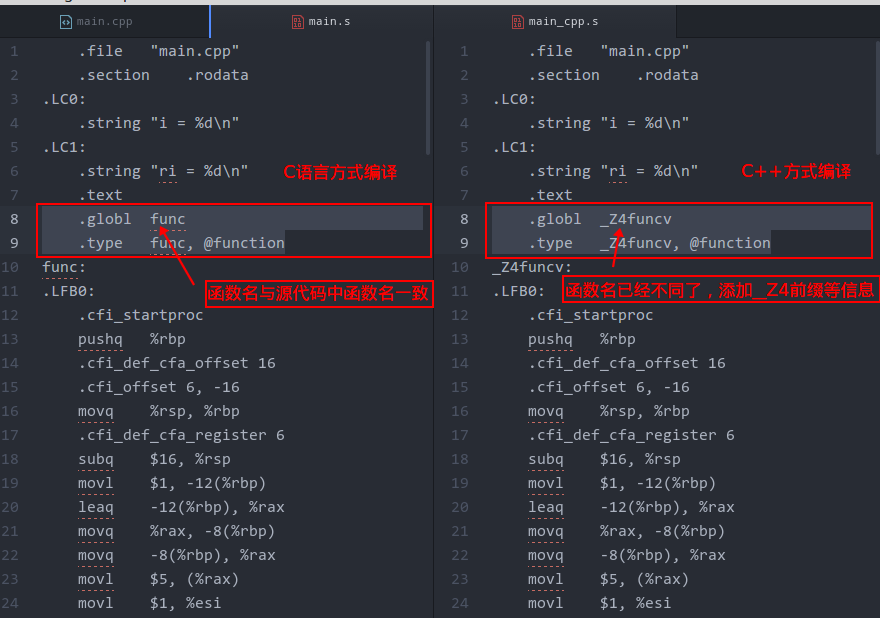
差别截图上已经标明,这其实就是为什么C和C++互相调用时,提示找不到函数的本质原因,因为一个编译后函数名变了,而一个却没变!
Tip:
extern “C” 中的重载函数经过C方式编译后将得到相同的函数名,因此 extern “C” 中不允许重载函数,但 extern “C” 中的函数可以与extern “C”之外的函数进行重载。
其次,再看C++重载函数编译出的汇编代码:
.file "main.cpp"
.section .rodata
.LC0:
.string "i = %d\n"
.LC1:
.string "ri = %d\n"
.text
.globl _Z4funcv
.type _Z4funcv, @function
_Z4funcv:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $16, %rsp
movl $1, -12(%rbp)
leaq -12(%rbp), %rax
movq %rax, -8(%rbp)
movq -8(%rbp), %rax
movl $5, (%rax)
movl $1, %esi
movl $.LC0, %edi
movl $0, %eax
call printf
movq -8(%rbp), %rax
movl (%rax), %eax
movl %eax, %esi
movl $.LC1, %edi
movl $0, %eax
call printf
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size _Z4funcv, .-_Z4funcv
.globl _Z4funcPKc
.type _Z4funcPKc, @function
_Z4funcPKc:
.LFB1:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $16, %rsp
movq %rdi, -8(%rbp)
movq -8(%rbp), %rax
movq %rax, %rdi
call puts
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE1:
.size _Z4funcPKc, .-_Z4funcPKc
.globl _Z4funcii
.type _Z4funcii, @function
_Z4funcii:
.LFB2:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
movl %edi, -4(%rbp)
movl %esi, -8(%rbp)
movl -8(%rbp), %eax
movl -4(%rbp), %edx
addl %edx, %eax
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE2:
.size _Z4funcii, .-_Z4funcii
.section .rodata
.LC2:
.string "Hello Linux\357\274\201"
.text
.globl main
.type main, @function
main:
.LFB3:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
call _Z4funcv
movl $.LC2, %edi
call _Z4funcPKc
movl $2, %esi
movl $1, %edi
call _Z4funcii
movl $0, %eax
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE3:
.size main, .-main
.ident "GCC: (Ubuntu 4.8.4-2ubuntu1~14.04) 4.8.4"
.section .note.GNU-stack,"",@progbits可以发现,虽然源代码中函数名都一样,但是在编译阶段就被编译器处理了,生成的汇编代码中每个重载函数的名字都不一样!所以重载是源代码级别的,汇编级别的没有重载一说,都是不同的函数!















 589
589

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









