







08分布式
Peer to Peer Networks
IP routing ip路由 和 routing overlays 路由覆盖
- 1. scalability 可伸缩性
- 2. load balancing 负载平衡
- 3. Network Dynamics (Addition/Deletion of Nodes)
- 4. Fault Tolerance 容错
- 5. Target Identification 目标识别
- 6. Security and Anonymity 安全和匿名
P2P
- 完整性保证
- 可用性保证
- P2P系统的好处
Pastry
GUID的生成
GUID的分布
Pastry的路由算法
逻辑距离和物理距离
局部性指标和路由表
自组织的路由覆盖网络
简单算法表示
- 新节点加入
- 节点失效
节点离开(Node Departure)
更新叶集
更新路由表
Pastry系统分析
BitTorrent
Peer to Peer Networks
IP routing ip路由 和 routing overlays 路由覆盖
IP路由和路由覆盖是两种不同的数据传输和网络通信机制。它们都涉及数据包从源头到目的地的路径选择,但是在设计、实现和使用的层面上有所不同。
IP路由(IP Routing)
IP路由是互联网中最基本的数据传输方式。它使用互联网协议(Internet Protocol, IP)来发送数据包。IP路由的关键在于它使用固定的网络结构和路由表来决定数据包的路径。
每当一个设备(如计算机、手机)尝试与网络上的另一个设备通信时,它会通过IP路由发送数据包。这些数据包包含源IP地址和目标IP地址。网络上的路由器使用路由表来决定如何将数据包从一个节点转发到下一个节点,直到它们到达目标位置。
举例: 当你访问一个网站时,你的计算机(客户端)会通过IP路由将请求发送到托管该网站的服务器。这个请求可能会经过多个路由器,每个路由器根据自己的路由表将请求向目标推进。
路由覆盖(Routing Overlays)
路由覆盖网络是建立在现有网络之上的一层抽象网络。它使用逻辑地址和路径而不直接依赖于物理网络的IP地址。这使得路由覆盖网络能够提供更为灵活的数据传输服务,如动态路由、负载平衡、故障转移和数据复制等。
在路由覆盖网络中,节点之间的通信不是直接发送到物理IP地址,而是发送到覆盖网络中的逻辑地址。覆盖网络中的每个节点都负责了解如何将数据转发到最终的目的地或下一个最佳的覆盖节点。
举例: P2P网络是路由覆盖的一个常见例子。例如,当你使用BitTorrent客户端下载文件时,你的计算机成为网络中的一个节点,它使用一个逻辑网络(覆盖网络)来发现文件片段并从多个节点下载数据。数据的传输并不直接依赖于IP路由,而是通过BitTorrent协议定义的逻辑网络来优化数据传输路径。
总结来说,IP路由关注于基于固定网络结构的数据传输,而路由覆盖更关注于在这个固定结构之上提供额外的服务和优化,它们可以提供更强大的功能和更灵活的网络管理能力。
1. scalability 可伸缩性
- IP:IPv4有232因为分层性质,很多地址无法使用,而且也不够多。IPv6有2128个地址,但也有分层性质导致的地址无法使用。比如通过前缀来划分网络
- Overlays:P2P可以须知到更多对象,地址远大于2128,所有地址都可使用。通常使用全局唯一标识符(GUID)来标识对象,非层次性的扁平地址空间,所有的地址都是可以独立使用的
2. load balancing 负载平衡
- IP:负载由网络拓扑和相关的流量模式决定。意味着某些路由器可能会因为处于流量繁忙的路径上而负载过重。
- Overlays:对象的位置随机化,流量模式不受网络拓扑的影响。因此路由覆盖网络可以避免由于网络拓扑导致的负载不平衡问题。
3. Network Dynamics (Addition/Deletion of Nodes)
- IP:路由表为基础异步更新,时间常数一般为1小时。当网络中添加或删除节点时,IP路由表需要更新
- Overlays:可以同步或异步更新,延迟很小
4. Fault Tolerance 容错
- IP:冗余由管理人员设计,确保容错率,但是昂贵。为了实现故障容忍,通常需要通过设计冗余的网络路径和多余的设备来提高网络的可靠性
- Overlays:路由和对象可以复制n倍,保证n个节点连接成功或失败。覆盖网络中,可以通过在多个节点上复制路由和对象引用来实现容错。当某个节点或连接失败时,可以自动切换到复制的路径或对象,这种方式通常比在物理网络层面上增加冗余成本更低。
5. Target Identification 目标识别
- IP:一个IP地址只映射一个目标节点。即一个IP地址只对应一个设备
- Overlays:可以将消息路由到最近的目标节点副本。这意味着不是单一的固定路径,而是可以根据网络情况动态选择最优的路径。
6. Security and Anonymity 安全和匿名
- IP:当所有节点都被信任时才安全。无法实现匿名。IP地址是公开的
- Overlays:可以不全被信任也安全,可以实现一定程度的匿名。例如通过路由信息的层层转发和加密,可以隐藏消息的最终来源或目的地。
P2P
点对点(Peer-to-Peer,简称P2P)中间件平台是一种分布式网络技术,它允许网络中的每个节点(通常是个人计算机或服务器)直接与其他节点进行通信和数据交换。P2P网络与传统的客户端-服务器模型不同,在客户端-服务器模型中,所有通信都是通过中央服务器进行的。在P2P网络中,每个节点既可以是客户端也可以是服务器
在P2P中间件平台中,对象通常是通过全局唯一标识符(GUID)来寻址的。GUID是一种“纯名称”,它不包含任何有关对象物理位置(如IP地址)的信息。这种命名方法提供了一定程度的匿名性,因为从GUID本身通常无法确定对象实际位于互联网上的哪个节点。
为了在网络中找到与GUID对应的数据对象,P2P平台使用了一种映射基础设施。分布式哈希表(Distributed Hash Table,DHT)模型是这种映射基础设施的一个常见例子。在DHT中,每个节点负责一部分哈希表的维护,这样可以将GUID映射到负责存储相关对象的节点。通过这种映射基础设施,P2P网络可以实现高效的对象查找过程。当一个节点需要访问一个数据对象时,它会使用DHT来确定哪个节点存储了该对象,并直接与该节点通信来获取或更新数据。
一旦确定了数据对象的位置,P2P网络就通过路由覆盖算法来执行数据的传递。这个算法是P2P中间件平台的核心部分,它决定了数据如何在网络中的节点间传输。路由覆盖网络不依赖于互联网的IP路由,而是创建了一个逻辑层,该逻辑层定义了节点间传输数据的路径。这个逻辑层允许P2P网络通过各种优化算法(如最小延迟、最大吞吐量或其他度量标准)来选择最优路径。它还允许网络动态适应节点的添加或移除,以及网络条件的变化。
P2P中间件平台允许数据对象的存储和检索在互联网上的任意位置进行,不依赖于固定的服务器或IP地址。这种方法提高了网络的可扩展性、容错能力,并且由于其分散的特点,也增强了系统的鲁棒性。此外,使用GUID和路由覆盖算法还可以提供匿名性和改进的数据传输效率。
完整性保证
- 基于安全哈希函数生成GUIDs: P2P平台使用安全哈希函数来为数据对象生成GUID。哈希函数保证了即使是极小的数据变动也会导致完全不同的哈希值,这有助于验证数据的完整性。当数据被检索时,可以通过比较数据的哈希值与原始哈希值来确认数据未被篡改,从而保证了数据的完整性。
可用性保证
- 多节点复制: P2P中间件平台通过在多个节点上复制数据对象来保证数据的可用性。即使某些节点发生故障或者不可达,数据仍然可以从其他节点中检索得到,这提高了系统的鲁棒性和数据的可用性。
- 容错路由算法: 这些算法确保了即使在面对节点失效或网络分割的情况下,网络仍能找到数据传输的路径。容错能力使得P2P系统可以自我恢复,即使在网络状况不理想的情况下也能继续操作。
P2P系统的好处
- 利用未使用的资源: P2P系统能够利用参与网络的主机计算机中的未使用资源,如存储空间和处理能力。这些资源通常在客户端-服务器模型中是被浪费的。
- 可扩展性: P2P系统能够支持大量的客户端和主机,同时维持网络链路和主机上的负载平衡。它通过分布式的特性避免了中心化系统可能遇到的瓶颈。
- 自组织特性: P2P中间件平台具有自组织的属性,能够在没有或很少人工干预的情况下自我维护和优化。这降低了随着主机和客户端数量增加而增加的支持成本。
总结来说,P2P中间件平台的设计允许网络在无需中央管理的情况下,通过其自我维护的能力和容错机制,确保数据的完整性和可用性。这些特性使P2P网络非常适合于动态变化且规模庞大的网络环境。
Pastry
Pastry是一种点对点的分布式哈希表(DHT)网络,它为节点和对象提供了一个分布式存储系统的实现。在Pastry中,每个节点和对象都通过128位的全局唯一标识符(GUID)进行标识。下面详细介绍Pastry的这些关键特性:
GUID的生成
- 节点GUID: 节点的GUID是通过对关联的公钥应用安全哈希函数(例如SHA-1)来计算得出的。这意味着每个节点的GUID是唯一且难以预测的,因为安全哈希函数设计之初就是为了防止任何形式的冲突和反向工程。
- 对象GUID: 对象的GUID是通过对对象的名称或对象存储状态的某一部分应用安全哈希函数来计算得出的。这样,对象的标识符也是唯一的,并且与对象的内容紧密关联。
GUID的分布
- 计算出来的GUID在0到2^128-1范围内随机分布。由于GUID的空间极其广阔,所以实际上不太可能出现两个不同的节点或对象具有相同GUID的情况。
Pastry的路由算法
- 在有N个参与节点的网络中,Pastry的路由算法能够保证在对数时间内(即O(log N)步骤)将消息正确地路由到任何一个GUID地址。这是通过一个精心设计的分层路由表和节点状态表实现的。
- 如果GUID标识了一个活跃节点,消息就直接传递到这个节点。如果目标GUID不对应任何活跃节点,消息将被传递到数值上最接近该GUID的活跃节点。
- 活跃节点负责处理发往它们数字邻域内所有对象的请求。这意味着每个节点并不是仅仅处理发往自己GUID的消息,还要处理那些与自己的GUID数值上接近的对象的请求。
路由覆盖网络,如Pastry,是在现有网络基础之上建立的一层逻辑网络,用于在节点之间传递消息。Pastry的路由步骤涉及使用底层协议(通常是UDP)来传输消息至一个在逻辑上“更接近”目的地的Pastry节点。这里的“逻辑上”指的是Pastry定义的逻辑空间,而非物理上的距离。
逻辑距离和物理距离
- 在Pastry逻辑空间中的“接近性”,是根据节点的GUID计算出来的。这种计算方式保证消息在每一步都更接近其目标GUID。
- 实际上,一个消息在互联网上从一个Pastry节点传输到另一个Pastry节点可能需要通过多个IP跳转。
局部性指标和路由表
- Pastry通过使用局部性指标(locality metric)来最小化网络路径的延伸风险。这意味着,在设置每个节点的路由表时,Pastry会选择那些在底层网络中网络距离较近的节点作为“邻居”。
- 这个指标是基于底层网络中的实际网络距离来选择路由表中的条目,从而优化了数据传输路径,并减少了跳数。
自组织的路由覆盖网络
- 路由覆盖网络是完全自组织的:当新节点加入网络时,它们可以通过与现有节点交换O(log N)条消息来获取构建路由表和其他所需状态的数据。
- 当节点离开或者出现故障时,其它节点能够检测到这一变化,并且会协作重新配置自己的状态,以保持网络的完整性和服务的连续性。
简单算法表示






新节点加入
这段描述说明了一个具有GUID X的新节点如何加入Pastry系统。下面是加入过程的各个步骤:
- 计算GUID: 新节点使用其公钥通过SHA-1哈希函数计算出自己的GUID X。这确保了每个节点有一个独一无二的标识符。
- 找到附近的节点A: 新节点需要找到一个已经是Pastry网络一部分的且在网络距离上最近的节点A。这通常是通过最近邻算法来实现的,目的是为了找到一个与新节点在网络拓扑上距离较近的节点,这有助于维持Pastry网络的局部性和效率。
- 发送加入消息: 新节点向找到的节点A发送一个加入消息,并附上其GUID X。
- 消息路由到节点Z: 节点A收到加入消息后,会将消息沿着路径向那些其GUID在数值上接近新节点GUID X的节点路由。最终,消息会被路由到节点Z,其GUID在数值上最接近新节点GUID X。
- 状态传递: 在消息路由的过程中,节点A、Z以及路径上的所有节点会将它们的状态信息发送给新节点X。状态信息包括它们的叶集和路由表,这对新节点构建自己的Pastry状态是必要的。
- 构建状态表并通知: 新节点X使用接收到的信息来构建自己的叶集和路由表。构建完成后,它将通知那些受影响的节点。这个通知过程可能涉及更新这些节点的叶集和路由表,以包含新节点X作为成员。
通过这一过程,新节点成功地加入Pastry网络,并且网络中的其他节点将会更新它们的状态以包含新节点的信息,从而保持网络的最新状态和高效路由。这个过程也保证了即使在持续变化的网络环境中,如节点频繁地加入和离开,Pastry网络也能够自我组织和维持其结构。
节点失效
Pastry分布式网络在处理节点离开(或节点失败)时如何维护网络状态的完整性。这里涉及两个关键部分:叶集(Leaf Set)和路由表(Routing Table)的更新。以下是详细解释:
节点离开(Node Departure)
当节点失去与其所有邻居节点的通信时,它被视为已失败。在Pastry中,节点的失效通常通过邻居间的定期通信来检测。一旦检测到节点失效,就需要更新包含该失败节点GUID的叶集和路由表。
更新叶集
- 如果失败的节点在叶集L中,检测到失败的节点的邻居节点会联系叶集中的一个存活节点,请求其叶集L’。
- 使用请求到的叶集L’来修复自身的叶集,以此确保叶集的完整性和正确性。
更新路由表
- 如果失败的节点被路由表识别,即便有路由表条目不再有效,消息的路由仍然可以继续进行。
- 该行的存活节点将被联系,以获取同一行的条目并更新自己的路由表。
- 如果同行没有存活节点,就会联系前一行的节点以获得更新。
Pastry系统分析
Pastry是一个通用的点对点内容定位和路由系统,它的设计考虑了以下特点:
- 支持复制:系统支持将数据复制到网络中的多个节点,以增加数据的可用性和耐用性。
- 容错性:通过在叶集和路由表中维护多个条目来增强容错性,从而使网络能够在节点失效时自我修复。
- 良好的可扩展性:Pastry能够有效地扩展到大量的节点,而不会显著影响性能。
- 应用范围广泛:由于其灵活性,Pastry被用于多种应用程序,例如:
- PAST:大规模的点对点文件共享系统。
- SCRIBE:群组通讯系统。
- Squirrel:去中心化的点对点Web缓存。
- SplitStream:内容流媒体/分发系统。
- 考虑网络局部性:在路由消息时,Pastry考虑了节点在底层传输网络中的局部性属性,这可以降低延迟并优化网络性能。
通过这些特性,Pastry能够为分布式应用提供一个鲁棒的底层框架,能够在面对节点失效和网络变动时,快速适应和自我恢复。
BitTorrent
BitTorrent 是一个点对点(P2P)文件分享协议,它允许用户直接通过互联网互相分享和下载大型文件,而无需依靠中央服务器。这种技术于2001年由布拉姆·科恩(Bram Cohen)发明,并迅速成为世界上最受欢迎的文件分享方法之一。
下面是BitTorrent工作的基本原理:
- 分布式文件传输:在BitTorrent网络中,文件不是从单一源下载,而是被切割成许多小块。下载者(leechers)从其他用户(seeders)那里下载小块文件。这意味着文件源可以支持大量用户而不会因为带宽限制而导致速度下降。
- 种子和对等体:在BitTorrent术语中,已经下载完整文件并继续上传给其他人的用户称为“种子”(seeders)。正在下载文件的用户称为“对等体”(peers)或“下载者”(leechers)。
- Torrent文件和磁力链接:要开始下载文件,用户需要获取一个“.torrent”文件或者一个磁力链接。这个文件或链接包含了文件分块的信息以及网络中的跟踪器(tracker),跟踪器是协助寻找其他拥有文件块的用户的服务器。
- 跟踪器和DHT:跟踪器协助对等体之间的通信。然而,现代的BitTorrent客户端也使用分布式哈希表(DHT)技术,这样即使没有跟踪器也能找到文件块的来源。
- 上传和下载:用户在下载文件的同时,也会上传已经下载的文件块给其他用户。这种方式保证了文件的快速传播,并确保了网络的生态健康。
BitTorrent协议的设计鼓励用户上传文件,因为下载速度往往受到上传速度的影响。如果用户只下载而不上传,他们的下载速度可能会受到限制。
尽管BitTorrent协议本身是合法的,但它常常与非法文件分享活动联系在一起,因为它可以用来分享受版权保护的内容。然而,它也被用于合法的用途,例如分发大型软件和游戏文件、公共领域的影片和音乐,以及作为某些公司和组织分发数据的方式。
所以每个人都可以为别人下载某个文件做一定的共享呗,比如A共享前百分之五的内容,B共享百分之15,等等
-
file swarming (i.e. File Sharing)
-
swarm = set of peers that are participating in distributing the same files • Usually does not perform all the functions of a typical P2P system such as searching
-
在BitTorrent术语中,“peer”通常指的是参与文件共享网络的任何用户,无论是下载文件的用户还是提供文件供其他人下载的用户。当一个peer完全下载了一个文件后,他们可以成为该文件的“seed”(种子),这意味着他们拥有文件的完整副本,并且继续留在网络中供其他peers下载。当一个peer还在下载文件的过程中,他们既是下载者(leecher),也是上传者,因为他们可以上传已经下载的文件部分给其他peers。
以下是相关的步骤和术语概述:
- 创建.torrent文件:想要共享文件或文件群的用户(peer)首先会创建一个.torrent文件。
- .torrent文件:这是一个小文件,包含以下内容:
- 要共享的文件的元数据(meta data)。
- 关于tracker的信息,tracker是一个协调文件分发的计算机。
- 使用.torrent文件:peers首先获取.torrent文件,然后连接到该文件指定的tracker。tracker负责告诉peers从哪里下载文件的各个片段。
在BitTorrent网络中,任何人都可以是peer,不论他们是在下载文件还是在上传文件。一旦peer下载了全部文件并保持其客户端开启以供他人下载,他就变成了一个seed。这种设计鼓励文件的快速和高效分发。
-
一些术语
- seed:提供别人下载资源的人
- leech:需要下载的人
- tracker:跟踪器是BitTorrent 文件共享生态系统中的中央服务器,虽然现代的BitTorrent客户端也可以在没有传统跟踪器的情况下通过分布式哈希表(DHT)发现对等方。
- 保持对等方列表:跟踪器保存一个所有参与共享特定
.torrent文件中的文件的对等方列表。 - 协调文件分发:它协助新的对等方找到已经在群聚中的对等方,并开始文件块的下载和上传过程。
- 使对等方互相发现:跟踪器响应对等方的请求,并提供一个对等方列表,使得它们能够连接并相互分享数据。
- 状态信息:跟踪器跟踪对等方的状态信息,如是否已完成下载或仍在下载中。
- 返回随机对等方列表:为了保证网络的健康和效率,跟踪器通常会返回一个随机的对等方列表给请求的peer,这样可以避免所有peer同时连接到同一个或一小组peers。
- 保持对等方列表:跟踪器保存一个所有参与共享特定
- .torrent file:一个
.torrent文件是一个小的元数据文件,包含了关于文件共享过程所需的关键信息,通常包括:- 跟踪器的URL:指向一个或多个跟踪器的链接,这些跟踪器负责协调文件传输。
- 文件的分片信息:文件被分成多个分片(pieces),每个分片有一个唯一的散列值(通常是SHA-1散列)。这些散列值用于确保文件在传输过程中的完整性。
- 分片长度:每个分片的大小(通常是固定的数值,例如64KB to 1MB)。512居多
- 文件名:要分享的文件或文件集合的名称。
- 文件长度:文件的总大小,有时候如果是多文件共享,这部分可能会包含每个文件的大小和名称。
-
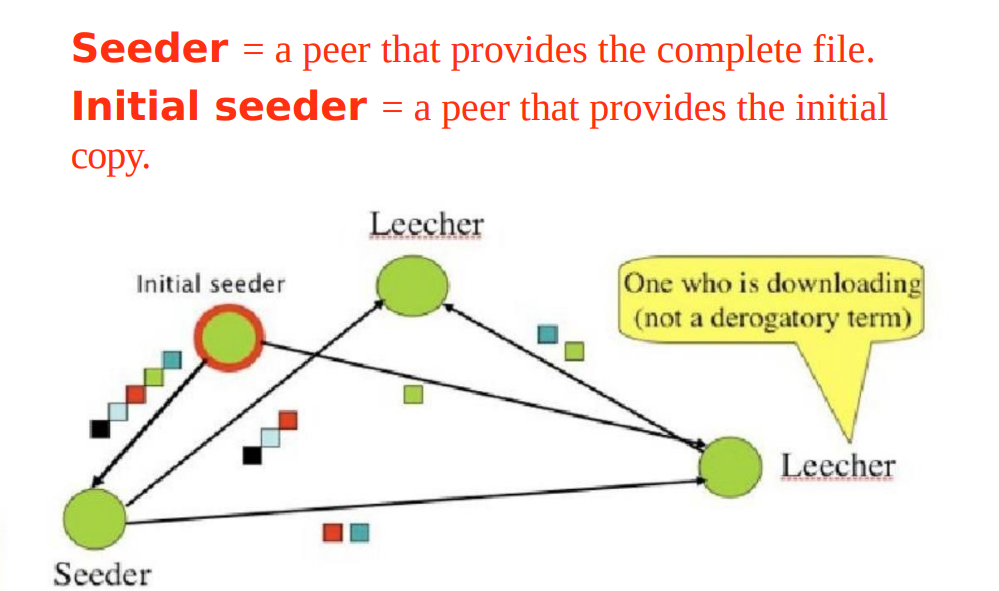
- 此种文件一般托管到web服务器
- 初始种子首先切片。这些小块独立上传和下载
- 下载者首先找到指向tracker的torrent文件,此文件包含文件块的元数据和追踪器地址
- 下载者联系追踪器,追踪器告知此下载者其他和他一块下的peers
- 一边下一边给别人提供副本
- 下载完毕后会成为一个新种子,下载者成为新seeder
- 在文件重组过程中,客户端会验证每个文件块的校验和(checksum),通常是通过比较每个块的哈希值来确保文件的完整性和准确性
- 这种方法使得大型文件能够在没有中央服务器的情况下快速有效地分发,因为每个下载者都参与到文件的上传过程中,帮助分发给其他用户。这就是所谓的“群聚”(swarm)效应,它是BitTorrent高效率的关键所在。

-
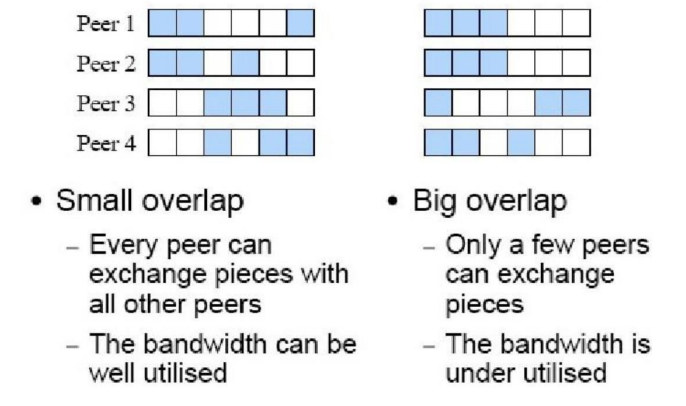
高效,快速下载。从许多点下载,加速;减少对等点之间的块重叠,允许每个peer尽可能多的与其他peer交换;下载随机片段,优先考虑最稀有片段,以实现均匀的片段分布。他们通常会以随机顺序下载文件块,而不是按顺序。这样做的目的是减少早期阶段所有peers都试图获取相同块的可能性,从而减少了竞争,确保了更多的块能被同时传播。优先下载在整个网络中出现次数最少的块。这种策略有助于确保所有的块都以相同的频率被复制跨peers
-
-
-
可靠,快速恢复,验证数据完整性。BitTorrent网络必须对peer的断开连接(dropping)表现出弹性,因为在文件共享过程中,peer可能由于各种原因随时加入或离开网络。对断开连接的peers的容忍度:
- 降低单个peer依赖:由于每个peer都有可能掉线,BitTorrent设计了不依赖单一peer的系统。一个文件块的多个副本会分布在多个peer之间,这样即使某个peer掉线,其他peer仍然可以提供该文件块。
- 动态重新分配:当一个peer掉线时,正在与之交换数据的其他peer会寻找其他拥有所需文件块的peer。客户端软件通常会自动管理这个过程,确保下载不会因为某个peer的断开连接而中断。
最大化文件块冗余:
- 分发副本最大化:通过确保每个文件块都有尽可能多的副本,BitTorrent协议增加了网络的健壮性。这意味着即使某些peer离线,文件块仍然可以从其他多个peer处获得。
- 保证高可用性:最大化每个文件块的分发副本确保了即使在peer数量变动较大的情况下,网络中的文件块也能高可用。这有助于维持快速且稳定的下载速度。
-
最大限度分发副本,最大限度提供稀有副本


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









