







#论文题目:MP2: A Momentum Contrast Approach for Recommendation with Pointwise and Pairwise Learning(MP2:动量对比框架缓解推荐系统中的标注偏差)
#论文地址:https://arxiv.org/pdf/2204.08326.pdf
#论文源码开源地址:暂无
#论文所属会议:SIGIR’22
#论文所属单位:eBay、Tencent
一、引言
什么是标注偏差?
逐点损失中将标签标记为0和1,但是用户的偏好可能是0.9,0.7这种类似的情况,所以存在偏差。
在之前的博客中也提到逐点损失是有偏差的,因为在不同的样本对比中,标签标记为0或1,其在损失函数中的位置不一样,其对应的数学表达也不一样。也就是说,标注偏差会使得模型的Loss函数中的样本点反复横跳。(一会样本点是正样本,一会是负样本)

下图中的B样本就存在标注偏差。

什么是动量下降?
动量梯度下降(Gradient Descent with Momentum)算法思想:参数更新时在一定程度上保留之前更新的方向,同时又利用当前batch的梯度微调最终的更新方向,简言之就是通过积累之前的动量来加速当前的梯度。
下面一张图可以很直观地表达Momentum算法的思想。举个简单例子,假设上次更新时梯度是往前走的,这次更新的梯度算出来是往左走,这变化太剧烈了,所以我们来做个折中,往左前方走。感觉上,像是上次更新还带有一定的惯性。

这样梯度下降过程会有什么变化,如下图所示:

使用动量梯度下降时,通过累加过去的梯度值来减少抵达最小值路径上的波动,加速了收敛,因此在横轴方向下降得更快,从而得到图中蓝色的曲线。当前后梯度方向一致时,动量梯度下降能够加速学习;而前后梯度方向不一致时,动量梯度下降能够抑制震荡。
我们可以形象的理解,给定一个小球,小球在向下运动的过程中会有加速度,导致越来越快,但是由于 β \beta β的存在使得不会一直加速运行。具体详见博客链接,本文在选取动量参数的时候也是从上述[0.5,0.9,0.95,0.99]中做交叉验证实验选取最优解的。
二、创新点
通过上述描述,显而易见,本篇文章的创新点为:
- 由于在小批量梯度下降中,如果每次选取的样本数量较小,损失会呈现震荡的方式下降,而用动量下降方法,则会抑制这种现象。
- 作者发现成对标签的软标签特性可以用来减轻逐点标签的偏差。因此,为减轻样本集合中逐点标注的偏差,本文提出了动量对比框架(MP2),它结合了逐点和成对学习。
作者在ICLR-2017的Temporal Ensembling for Semi-supervised
Learning文章上进行了改进,该文章也提出了和本文同样的结构,但是其损失函数是最小化(2)式,而不是设置不同差异的权重数值。
三、算法框架

3.1 三塔结构设计
由上图我们可以看到它由一个用户网络
ϕ
\phi
ϕu(·,
θ
\theta
θu),一个普通的商品网络
ϕ
\phi
ϕv(·,
θ
\theta
θv)和一个商品动量网络
ϕ
\phi
ϕm(·,
θ
\theta
θm)组成。其中,
ϕ
\phi
ϕv(·,
θ
\theta
θv)和
ϕ
\phi
ϕm(·,
θ
\theta
θm)具有同样的结构。三塔下方是一个特征embedding层,用于处理数字和分类特征,得到稠密的表征。用
u
u
u作为
ϕ
\phi
ϕu(·,
θ
\theta
θu)生成的用户表示,用
v
v
v作为
ϕ
\phi
ϕv(·,
θ
\theta
θv)生成的item的普通表示,用用
v
v
vm作为
ϕ
\phi
ϕm(·,
θ
\theta
θm)生成的item的动量表示。然后,将这些表示用于逐点和成对学习。
对于数据样本(
U
U
Ui,
V
V
Vj,
V
V
Vt,
y
y
yi,j,
y
y
yi,t, j > ut),我们使用
y
y
y^ i,j=
u
u
ui
v
v
vmj 和
y
y
y^ i,t=
u
u
ui
v
v
vmt来预测pointwise对应的标签,使用
y
y
y^ pair=
u
u
ui
v
v
vj -
u
u
ui
v
v
vt来预测pairwise标签。
回顾一下,我们的目标是学习一个一致的项目表示,所以设计了两个项目网络用于对比着的表示学习。直观上,如果优化过程中某一项表征的实值变化较大,说明该项表征波动较大,对应标签可能存在标注偏差。利用两个商品网络对波动进行建模,然后解决标注偏差,这包括两个阶段:
- 动量更新。由于逐点标签受到标注偏差的影响, v v vm可能在传统的梯度下降优化器中波动很大。商品表征 v v vm(逐点学习)通过动量更新而不是正常的梯度反向传播进行优化,这确保了一致的更新。
- 有差异的权重标签。波动是通过同一商品的两个表征的差异来衡量的,这进一步作为逐点标签的置信度。波动越大,表示相应的逐点标签的权重越低,这会自动降低不可信逐点标签的重要性。
3.2 动量更新
简单商品网络
ϕ
\phi
ϕv(·,
θ
\theta
θv)和用户网络
ϕ
\phi
ϕu(·,
θ
\theta
θu)通过梯度下降办法更新其权值,但是
ϕ
\phi
ϕm(·,
θ
\theta
θm)通过平均
θ
\theta
θv更新
θ
\theta
θm,公式如下:
其中,
α
\alpha
α∈[0, 1)是超参数,控制
θ
\theta
θm的平滑度。尽管由于标注偏差,某些商品可能对同一用户具有 0 和 1 的逐点标签,但可以使商品表征的波动很小。相比之下,在经典推荐模型(
y
y
yi,j=
u
u
ui
v
v
vj)中,
v
v
vj将收到相反的优化信号,这将影响商品表征的一致性。
学习目标通过反向传播▽
L
L
Ltotal更新
ϕ
\phi
ϕu(·,
θ
\theta
θu)。对于每一步,参数
θ
\theta
θu的更新会立即反映在下一批的用户表征中。另一方面,商品表征不是通过
ϕ
\phi
ϕv(·,
θ
\theta
θv)得到的,而是通过动量复制得到的。
3.3 有差异的加权标签
动量更新后,我们利用
ϕ
\phi
ϕv(·,
θ
\theta
θv)和
ϕ
\phi
ϕm(·,
θ
\theta
θm)两项表示之间的差异来近似波动。差异定义如下:

δ
\delta
δj代表元素级差异,||表示元素的绝对值操作,
c
c
c是
δ
\delta
δj矩阵的长度,
δ
\delta
δj _是一个数值,我们把这整个差异作为点态标签的置信度项。
大的
δ
\delta
δj _表示高度不确定性,因此使用它的倒数作为逐点标签的置信度。在一个数据样本中有两个商品(即j和t)并且它们是相关的,同理可得,将它们组合起来作为标签权重:

从对应的
ϕ
\phi
ϕv(·,
θ
\theta
θv)和
ϕ
\phi
ϕm(·,
θ
\theta
θm)得到的两个表征的相似性反映了训练商品表征空间的局部性。
其中,作者提出这个思想的原因是因为引用了ICLR-2017的Temporal Ensembling for Semi-supervised
Learning文章,该文章也提出了和本文同样的结构,但是其损失函数是最小化(2)式,而不是设置不同差异的权重数值。
3.4 损失函数计算
MP2由两种损失组成:逐点损失和成对损失。对于逐点损失,使用差异项作为数据样本的置信度,其中,
w
w
wj,t表示在一个训练样本item上
j
j
j和
t
t
t的权重:

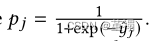
成对损失使用用户表征和来自动量网络的商品表征,公式如下:

最后,总体损失函数为:

下图表示算法的整体步骤:

四、结果

4.1 对比实验简介
- NeuMF:这是一种基于神经网络的具有二元交叉熵损失的协同滤波方法。它由双塔结构组成。
- BPR:这是一种对具有两两排序损失的矩阵分解模型进行优化的pairwise排序方法,是经典的两两(pairwise)推荐模型。
- Ranknet-NN:这是一个神经网络模型应用pairwise损失和一个双塔结构。
- APPL:该模型是一个联合学习模型,结合了两个点态损失和一个成对损失。它的原始版本是基于矩阵分解的,论文实现了一个深度学习版本,用一个双塔神经网络取代矩阵分解。
- T3 (Three-Tower): 该模型是MP2的一个截短版本,我们从MP2中去掉了动量更新和差异项。这个模型包含了一个三塔结构有两个点向标签和一个成对标签。通过网格搜索进行超参数调整,并使用最佳超参数对每种方法进行测试,以便进行公平比较。
4.2 实验对比结论
- 损失函数具有联接损失的模型(即MP2、T3和APPL)通常优于损失函数只是具有成对损失的模型(Ranknet-NN和BPR)或点态损失的模型(neuf),这表明结合pointwise和pairwise学习是一种很有前途的推荐方法。
- pairwise模型在经验上优于pointwise模型。这主要是因为pairwise模型捕捉项目的相对关系,数据集不存在注释偏差。
- Ranknet-NN(深度pairwise模型)在4个数据集上的表现优于BPR(非深度pairwise模型)。它们的损失函数是相同的,区别在于RanknetNN采用的是神经网络,可以学习高阶特征交互。相反,BPR基于矩阵分解,只能利用浅层特征交互进行推荐。
- MP2优于three tower和APPL,表明动量更新和加权策略的有效性。我们还发现T3比APPL更好,验证了三塔结构优于二塔结构的优越性。
通过以上分析,我们可以得出结论,MP2是有效的和有竞争力的。
五、结论
在本文中,研究了推荐中的标注偏差,这是一个广泛存在但被忽视的问题,它是由二进制点标签的有限表达性引起的。因此论文提出了MP2,一个动量对比框架的推荐,结合点态和成对学习,以减轻注释偏差。实验表明MP2比其他竞争方法具有更大的优越性。在未来,我们计划结合深度学习中的listwise loss和pointwise loss进行推荐。















 2014
2014











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









