







前言:当前最流行的Feed流产品有微博、微信朋友圈、头条的资讯推荐、快手抖音的视频推荐等,还有一些变种,比如私信、通知等,这些系统都是Feed流系统。Feed流是Feed + 流,Feed的本意是饲料,Feed流的本意就是有人一直在往一个地方投递新鲜的饲料,如果需要饲料,只需要盯着投递点就可以了,这样就能源源不断获取到新鲜的饲料。由于Feed流一般是按照时间“从上往下流动”,非常适合在移动设备端浏览。
一、Feed流简介
1.1、Feed流定义
在信息学里面,Feed其实是一个信息单元,比如一条朋友圈状态、一条微博、一条新闻或一条短视频等,所以Feed流就是不停更新的信息单元,只要关注某些发布者就能获取到源源不断的新鲜信息,我们的用户也就可以在移动设备上逐条去浏览这些信息单元。
Feed流本质上是一个数据流,是将 “N个发布者的信息单元” 通过 “关注关系” 传送给 “M个接收者”。
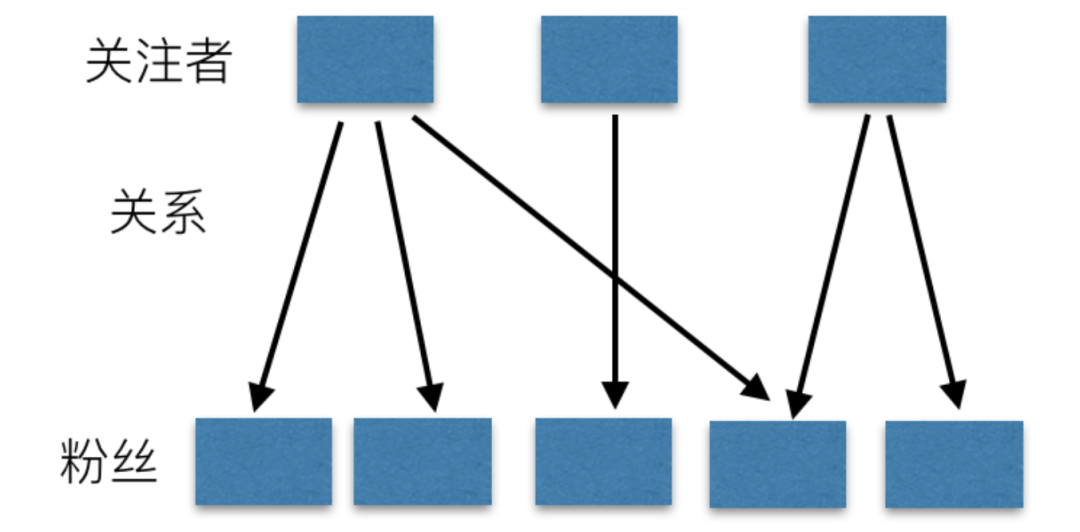
Feed流系统是一个数据流系统,据分为三类,分别是:
-
发布者的数据:发布者产生数据,然后数据需要按照发布者组织,需要根据发布者查到所有数据,比如微博的个人页面、朋友圈的个人相册等。
-
关注关系:系统中个体间的关系,微博中是关注,是单向流,朋友圈是好友,是双向流。不管是单向还是双向,当发布者发布一条信息时,该条信息的流动永远是单向的。
-
接收者的数据:从不同发布者那里获取到的数据,然后通过某种顺序(一般为时间)组织在一起,比如微博的首页、朋友圈首页等。这些数据具有时间热度属性,越新的数据越有价值,越新的数据就要排在最前面。
针对这三类数据,我们可以有如下定义:
-
存储库:存储发布者的数据,永久保存。
-
关注表:用户关系表,永久保存。
-
同步库:存储接收者的时间热度数据,只需要保留最近一段时间的数据即可。
1.2、Feed流应用场景特点
1) 读多写少
读写比例差距巨大,典型的读多写少场景。
2) 有序展示
需要根据timeline或者feed的打分值来进行排序处理展示。
二、Feed系统的数据存储设计
在数据存储上主要分三个部分
1)feed存储
是用户发布的内容存储,这部分内容需要永久存储,用户在查看个人主页的时候不论多久的都要可以看到。数据结构简化如下,根据userId进行水平分表
create table `t_feed`(`feedId` bigint not null PRIMARY KEY,`userId` bigint not null COMMENT '创建人ID'`content` text,`recordStatus` tinyint not null default 0 comment '记录状态')ENGINE=InnoDB;
2)关注关系存储
是用户之间关系的一个存储,也是控制用户能够看到feed范围的依赖,同样需要永久存储。
数据结构简化如下,根据userId进行水平分表:
CREATE TABLE `t_like`(`id` int(11) NOT NULL PRIMARY KEY,`userId` int(11) NOT NULL,`likerId` int(11) NOT NULL,KEY `userId` (`userId`),KEY `userId` (`likerId`),)ENGINE=InnoDB;
3)feed同步存储
用于feed流展示,可以理解为是一个收件箱,关注的人发布了feed,就要向其中投递。
可以根据业务场景保存一段时间内的内容,冷的数据可以进行归档也可以直接删除。
数据结构简化如下,根据userId进行水平分表:
create table `t_inbox`(`id` bigint not null PRIMARY KEY,`userId` bigint not null comment '收件人ID',`feedId` bigint not null comment '内容ID',`createTime` datetime not null)ENGINE=InnoDB;
4)总结
三张元数据表:用户表、作者表、文章表;
三张关联表:关注关系表、作者发件箱、用户收件箱;
三、如何设计Feed流系统?
设计Feed流系统时最核心的是确定清楚产品层面的定义,需要考虑的因素包括:
-
产品用户规模:用户规模在十万、千万、十亿级时,设计难度和侧重点会不同。
-
关注关系(单向、双写):如果是双向,那么就不会有大V,否则会有大V存在
-
如何实现Feed内容搜索?
-
虽然Feed流系统本身可以不需要搜索,但是一个Feed流产品必须要有搜索,否则信息发现难度会加大,用户留存率会大幅下降。
-
-
Feed流的顺序是时间还是其他分数,比如个人的喜好程度?
-
双向关系时由于关系很紧密,一定是按时间排序,就算一个关系很紧密的人发了一条空消息或者低价值消息,那我们也会需要关注了解的。
-
单向关系时,那么可能就会存在大V,大V的粉丝数量理论极限就是整个系统的用户数,有一些产品会让所有用户都默认关注产品负责人,这种产品中,该负责人就是最大的大V,粉丝数就是用户规模。
-
四、Feed流的主要模式
| 类型 | 推模式 | 拉模式 | 推拉结合模式 |
|---|---|---|---|
| 写放大 | 高 | 无 | 中 |
| 读放大 | 无 | 高 | 中 |
| 用户读取延时 | 毫秒 | 秒 | 秒 |
| 读写比例 | 1:99 | 99:1 | ~50:50 |
| 系统要求 | 写能力强 | 读能力强 | 读写都适中 |
| 常见系统 | Tablestore、Bigtable等LSM架构的分布式NoSQL | Redis、memcache等缓存系统或搜索系统(推荐排序场景) | 两者结合 |
| 架构复杂度 | 简单 | 复杂 | 更复杂 |
-
如果产品中是双向关系,那么就采用推模式。
-
如果产品中是单向关系,且用户数少于1000万,那么也采用推模式,足够了。
-
如果产品是单向关系,单用户数大于1000万,那么采用推拉结合模式,这时候可以从推模式演进过来,不需要额外重新推翻重做。
-
永远不要只用拉模式。
-
如果是一个初创企业,先用推模式,快速把系统设计出来,然后让产品去验证、迭代,等客户数大幅上涨到1000万后,再考虑升级为推拉集合模式。
4.1、推模式
4.1.2 推模式定义
推模式也称写扩散模式,当被关注人发布内容后,主动将内容推送给关注人,写入关注人的收件箱中。
当一个用户触发行为(比如发微博),自身行为记录到行为表中,同时也对应到这个用户的粉丝表,为每个粉丝插入一条feed。但是对于粉丝过万的大V,为每个粉丝插入一条feed对存储数据成本很大。

①当被关注人发布一条内容以后,获取所有关注该人的用户,然后进行遍历数据,将内容插入这些用户的收件箱中,示例如下:
/** 插入一条feed数据 **/
insert into t_feed (`feedId`,`userId`,`content`,`createTime`) values (10001,4,'内容','2021-10-31 17:00:00')
/** 查询所有粉丝 **/
select userId from t_like where liker = 4;
** 将feed插入粉丝的收件箱中 **/
insert into t_inbox (`userId`,`feedId`,`createTime`) values (1,10001,'2021-10-31 17:00:00');
insert into t_inbox (`userId`,`feedId`,`createTime`) values (2,10001,'2021-10-31 17:00:00');
insert into t_inbox (`userId`,`feedId`,`createTime`) values (3,10001,'2021-10-31 17:00:00'②当用户ID为1的用户进行查看feed流时,就将收件箱表中的所有数据进行查出,示例如下:
select feedId from t_inbox where userId = 1 ;③对数据进行聚合排序处理
4.1.2 存在的问题
1. 即时性较差
当大V被很多很多用户关注的时候,遍历进行粉丝进行插入数据非常耗时,用户不能及时收到内容
可尝试的解决方法:
1. 可将任务推入消息队列中,消费端多线程并行消费。2. 使用插入性能高、数据压缩率高的数据库
2. 存储成本很高
每个粉丝都要存储一份关注人的微博数据,大V粉丝量很高的时候,插入数据量成指数级上升。
并且微博可以将关注的博主进行分组,所以数据不仅要在全部收件箱中插入,也要在分组的收件箱中插入。
可尝试的解决方法:
数据冷热分离,热库仅保存短时间内的数据,冷库多保留一段时间的数据,冷热库均定时清理数据。用户量不断上涨,使用这种设计方案,终究还是会遇到瓶颈
3. 数据状态同步
当被关注用户删除微博或取关某博主时,需要将所有粉丝的收件箱中的内容都删除,依然存在一个写扩散的即时性问题
可尝试的解决方案:
在拉取数据的时候对微博的状态进行判断,过滤已删除/已取关的微博过滤以上解决方案可以在一定程度上提升效率,但是不能根源上解决问题。
4.1.3 推模式小结
推模式仅适用于粉丝量不会太多的情况,例如微信朋友圈,这样能够比较好的控制好即时触达性、以及数据存储的成本。
对于微博大V这种粉丝量很大的场景并不适合。
4.2、拉模式
4.2.1 拉模式
拉模式也称读扩散模式。当一个用户(特别是关注了很多人的)触发行为的时,拉取自己动态,检索用户的关注表,然后根据关注表检索新发的feed。如果一个用户关注过多的时候,查询该用户的关注列表也是有很大数据成本。

获取所有关注的博主ID
select liker from t_like where userId = 1;根据博主ID进行内容拉取
select * from t_feed where userId in (4,5,6) and recordStatus = 0;获取所有内容后根据timeline进行排序。
这样的方案解决了在推模式下存在的三个问题,但是却也引发了另外的性能问题。
假如,用户关注的博主非常多,要拉取所有内容并进行排序聚合,这样的操作必定会耗时很多,请求时延很高。
那么如何做到低耗时,完成快速响应呢?
单纯依靠数据库是无法达到要求的,所以我们要在中间引入缓存层(分片),通过缓存来降低磁盘IO。
流程为:
①关注列表缓存
将用户关注的所有博主ID存入缓存中。以用户ID为key,value为关注博主id集合
②微博内容缓存
以博主ID为key,value为微博内容集合。博主发布微博后,将微博内容存入集合中
③获取feed流时
根据关注的博主id集合,在所有缓存分片节点上拉取所有内容并进行排序聚合。
假如缓存分片集群为三主三从,也就是一共需要三次请求即可拉取到所有内容,然后进行时间倒排,响应给用户
4.2.2 存在的问题
系统的读压力很大:
假如用户关注了1000个博主,那么需要拉取这1000个博主的所有发布内容,进行排序聚合,对于缓存服务,以及带宽压力都很大。
可尝试的解决方案:
缓存节点一主多从,通过水平扩容,来分散读压力和带宽瓶颈4.2.3 拉模式小结
对于大V用户,拉模式能够很好解决写扩散存在的问题,同时也会带来上述存在的问题。
4.3、推拉结合模式
在线推,离线拉:
大V发动态,只同步发布动态给同时在线的粉丝,离线的粉丝上线后,再去拉取动态。来完成推与拉。

定时推,离线拉:
大V发动态之后,以常驻进程的方式定时推送到粉丝动态表。

feed流智能排序
智能排序基于趋势trending、热门hot、用户生产UGC 、编辑推荐PGC、相似Similarity等等因素综合考虑,随着技术的进步智能算法将会更加懂得用户的喜好。
4.4、总结
分析完推模式和拉模式的优缺点,我们很容易发现
推模式适合于粉丝量不大的场景。例如朋友圈,一对一聊天。
拉模式适合粉丝量巨大的大V用户。例如微博大V。
所以在场景设计时,可以将推模式和拉模式结合使用。逻辑如下
设定一个大V粉丝量阈值,达到阈值后触发打用户标签事件。
对于未达到阈值的用户依然使用写扩散方式,这样冗余的数据量不会太大,也不存在即时性问题。
当达到阈值的用户发微博的时候,将微博内容存入缓存(热数据),不进行写扩散,而是粉丝拉取数据与收件箱中的数据进行排序聚合。
PS:这里还可以通过用户行为去维护一个活跃粉丝列表,对于该列表中的粉丝,同样进行一个写扩散的行为,保证即时触达。
五、Feed 评论功能设计
除了私信类型外,其他的feed流类型中,都有评论功能,评论的属性和存储库差不多,但是多了一层关系:被评论的消息,所以只要将评论按照被被评论消息分组组织即可,然后查询时也是一个范围查询就行。这种查询方式很简单,用不到关系型数据库中复杂的事务、join等功能,很适合用分布式NoSQL数据库来存储。
所以,一般的选择方式就是:
-
如果系统中已经有了分布式NoSQL数据库,比如Tablestore、Bigtable等,那么直接用这些即可。
-
如果没有上述系统,那么如果有MySQL等关系型数据库,那就选关系型数据库即可。
-
如果选择了Tablestore,那么“评论表”设计结构如下:
| 主键列顺序 | 第一列主键 | 第二列主键 | 属性列 | 属性列 | 属性列 |
|---|---|---|---|---|---|
| 字段名 | message_id | comment_id | comment_content | reply_to | other |
| 备注 | 微博ID或朋友圈ID等消息的ID | 这一条评论的ID | 评论内容 | 回复给哪个用户 | 其他 |
如果需要搜索评论内容,那么对这张表建立多元索引即可。
六、Feed流架构思想
6.1、架构模型演化
(1)重新梳理一下,最始,为了使得用户读取关注流的响应时间快,采用推模型,公众号作者发文章后,立即推送给所有粉丝。从三个角度,我们讲这种设计思想在架构设计中,有 牺牲写性能,换取读性能、用空间换时间、平摊复杂度
(2)后来,粉丝数变多,推模型的推送阶段矛盾凸显,所以要想办法削平它。考虑到仅有一少部分读者是活跃用户,大部分读者是非活跃的,推送阶段只推给活跃用户,非活跃用户采用延迟推送的方式,这是延迟推模型。从架构设计的角度,这是冷热分离的思想。
(3)最后,用户层面的划分也扛不住大 V 作者了,进而考虑将作者也进行划分,分为大V 作者和普通作者,普通作者采用推模型或延迟推模型,大 V 作者采用拉模型,这是推拉结合模型。当然,这同样是冷热分离的思想。
6.2、架构细节优化
(1)再具体的细节,假如公众号作者的发件箱是用 mysql 或 hbase 这种数据库存储的,那大 V 作者的发布文章,可以进一步放在 Redis 中存储,读者在拉取大 V 作者的数据时就变得更快了,这是更细微层面的冷热分离。
(2)再比如,其实大部分用户,可能并没有关注到大 V 作者,但还是要去用户自己的关注关系表中,把其关注的作者都查出来,然后一个个判断是不是大 V 作者。当大部分情况下结果都是不存在大 V 作者时,我们又可以通过一点小技巧来优化,即在用户表中存储一个字段,表示该用户是否有关注大 V 作者。这样,在用户关注了一个大 V 作者后,就多了一步修改这个字段的逻辑,但换来的是大部分读者在查询大 V 作者时很可能无需查询,这显然是合适的,这又是一种牺牲写性能换取读性能,或牺牲空间换取时间的思想。
而整个,我们这样不断地发现优化点,不断牺牲这个换取那个,就是架构设计中的权衡,用一个更装逼的词汇就是,Trade-Off。其实就是英文的权衡。
倘若你在架构设计中,始终能有 Trade-Off 这种思想围绕,不论是理解很多组件的设计、业务的架构,还是面试中回答面试官的问题,都会让人觉得你的思路至少是清晰的,和你的交流,是通畅的。记住它,Trade-Off!
参考链接:



















 1544
1544

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











